


These two individuals, the producer and the recipient of language, or as we may more conveniently call them, the speaker and the hearer, and their relations to one another, should never be lost sight of if we want to understand the nature of language and of that part of language which is dealt with in grammar.
(Jespersen, Reference Jespersen1924, p. 17)
1. Introduction
As speakers of English or similar languages, we are prone to presume that the meaning-categories found in our grammar represent the essential information of a situation, and that whatever we express by more peripheral methods is just so much ‘extra stuff’. Take the English sentences The sun is coming up, look! or Hey, the sun has come up! (said as I shake my companion awake). In each of these, the core grammatical categories of tense, aspect, and mood dictate the choice of auxiliary and verbal inflection (is coming up, has come up). In contrast, expressions which position the speaker’s assessment of what information their interlocutor has access to lie at the sentence periphery and would not normally be seen as part of grammar. Look! presumes current non-access and directs attention. Hey! expresses dawning awareness – either speaker surprise, or directing the attention of a presumably non-aware addressee. Certainly, the choice of a phrase like has come up can indicate an assumption by the speaker that the described event is news to the interlocutor (McCawley, Reference McCawley1981; McCoard, Reference McCoard1978), but this meaning is only one of several that are available with the English perfect (Michaelis, Reference Michaelis1994), rather than a dedicated, necessary meaning. And starting a sentence with a word like certainly, as we do above, may be one of many tools we use to both concede and coerce an addressee’s point of view, but it is hardly a core component of forming a grammatical English clause. But this division of labour in English and languages like it – with the grammar focusing on event structure, and pragmatic questions of intersubjective placement outsourced to more marginal parts of the system – has distorted our view of what grammar can do. In these two serialised papers, we ask the reader to accompany us in some typological gymnastics which will show that there are numerous languages which place such ‘pragmatic’ factors at the heart of their grammars, and give their speakers neat shortcuts for expressing complex and delicate matters of who knows (or could, or should, know) the situation or event that is being described.
Taking a step back from what is familiar in English and its congeners, it should come as no surprise that there are languages which place intersubjective alignment at their heart. After all, grammars routinise our most common and central communicative tasks. And theory of mind (e.g., assessing an addressee’s attentional state), and the ability to coordinate attention with others (e.g., through awareness of whether another has perceptual access to the same or different things as we do) are central and defining human skills, and underpin many elements of social cognition (e.g., Enfield & Levinson, Reference Enfield and Levinson2006; Goody, Reference Goody1995; Tomasello, Reference Tomasello2008; Tomasello, Carpenter, Call, Behne, & Moll, Reference Tomasello, Carpenter, Call, Behne and Moll2005). Likewise, ostensive demonstration by adults, and children’s subsequent directing of attention, are a key part of adult–child interactions and set the scene for ‘natural pedagogy’ that is unique to humans Footnote 1 and common to all cultures (Csibra & Gergely, Reference Csibra and Gergely2009, Reference Csibra and Gergely2011). The ability to achieve such primary intersubjectivity (Trevarthen, Reference Trevarthen and Bullowa1979; cf. Scott-Phillips, Reference Scott-Phillips2015; Sperber & Wilson, Reference Sperber and Wilson1986) has been argued to be a prerequisite for the evolution of culture, and in particular of those conventionalised cultural manifestations which form linguistic signs. Footnote 2
Achieving intersubjectivity thus lies at the heart of how human communication systems evolved. But beyond this, speakers in real time need constantly to bring about adjustments to each other’s attention, beliefs, and states of knowledge – directing, persuading, and informing, at the same time as indicating empathy and deference (or their absence). Every human communicative system has a rich set of ways of doing this, many lying outside the domain of what is normally conceived of as grammatical structure. For example, Stivers and Rossano (Reference Stivers and Rossano2010) outline strategies used by speakers to mobilise the response of their addressee – gaze to the addressee, interrogative syntax, interrogative intonation, and speaking about topics that belong to the epistemic realm of the addressee. To this we might add gesture, and stance-taking phrases of various types (see Kockelman, Reference Kockelman2004, Biber & Finegan, Reference Biber and Finegan1989). Detailed investigations of these communicative resources have been pursued in discourse analysis (e.g., Verhagen, Reference Verhagen2005, Reference Verhagen, Dąbrowska and Divjak2015) and in the conversation-analytic tradition (Heritage, Reference Heritage, Stivers, Mondada and Steensig2011, Reference Heritage2012a, Reference Heritage2012b; Sacks, Reference Sacks, Button and Lee1987; Sacks, Schegloff, & Jefferson, Reference Sacks, Schegloff and Jefferson1974; Schegloff, Reference Schegloff2007).
But, despite the centrality of this communicative task, our understanding of the full panoply of grammatical means used across languages for intersubjective coordination remains basic (see, e.g., Heritage’s comments on the possible ‘shortchanging’ of linguistic form in his own work on epistemics in action; Reference Heritage2012c, p. 76). In this paper we return the focus to linguistic form, and in particular grammatical organisation. We argue that many languages have grammaticalised systems for monitoring and adjusting intersubjective settings; it is this grammaticalised intersubjectivity which we refer to as engagement, in much the same way as grammaticalised time representation merits the special metalinguistic term tense. Footnote 3 Our paper is serialised into two parts, across two successive issues of this journal – the first introducing the phenomenon, situating it with respect to other work on intersubjectivity in language, and outlining the key role of deixis in coordinating attention, the second broadening out to a typological survey of the phenomenon of engagement and to the diachronic question of how engagement systems originate.
Within this first part, we begin with an initial example from the Colombian language Andoke (§2), whose description by Landaburu (Reference Landaburu, Guentchéva and Landaburu2007) was the first to argue for engagement as a core grammatical phenomenon. We then review two other bodies of work on epistemic distribution in the speech situation. The first research tradition (§3) is attuned to general properties of conversational organisation rather than the use of core grammatical devices. The second (§4) sets up a general framework for viewing multiple perspective in language, necessary to understand the asymmetries of knowledge distribution that accompany any projection by the speaker of what they believe (or wish to portray they believe) the addressee’s epistemic disposition to be. Footnote 4 In §5, the concluding section of Part I, we pass to the primal scenario for establishing shared access – deixis – and examine the notion of engagement as it applies to the management of joint attention in deictic scenarios of drawing attention to entities, through demonstrative systems such as those of Turkish and Jahai.
2. What is engagement? An initial example
Consider the following pair of contrasting sentences from Andoke, an isolate language of the Colombian Amazon (Landaburu, Reference Landaburu, Guentchéva and Landaburu2007). Footnote 5
-
(1) a. páa b-ʌ ʌ-pó’kə̃-i
already +spkr+addr.engag-3sg.inan 3sg.inan-light-agr
‘The day is dawning (as we can both see).’
-
b. páa kẽ-ø ʌ-pó’kə̃-i
already +spkr-addr.engag-3sg.inan Footnote 6 3sg.inan-light-agr
‘The day is dawning (as I witness, but which you were not aware of).’
The relevant point of grammatical contrast is seen in the auxiliaries bʌ and kẽ (structurally similar to a word such as is in the English phrase is dawning) that precede the main verb ʌpó’kə̃i ‘light(en), dawn’. The Andoke auxiliaries are made up of two parts: the first element (b- or kẽ-) encodes the dimension of ‘engagement’ – the relative access of speaker and hearer – and the second element marks subject agreement (i.e., who is undertaking the activity; in this case, the day or the sun itself, which is encoded as a third person singular inanimate subject). No descriptive sentence can be constructed without employing one element from the engagement set. Footnote 7
Consider the situation where the day is dawning and the two of us, speaker and hearer, are watching the sun rise together, so the speaker can presume joint attention to this mutually accessible event. This would be expressed as in (1a), using the auxiliary base b- (represented as ‘plus speaker and plus addressee engagement’, +spkr+addr.engag). But if the event is not accessible to the addressee – for example, he is only just waking up and is not attending to it – the base, kẽ- (‘+spkr-addr.engag’) would be chosen (1b). Footnote 8 Though the reference to ‘seeing’ in our elaborated translations may seem reminiscent of evidentials, in particular those marking the source of information as visual, what is at issue in examples like (1a, b) is not primarily the source of information but whether the addressee is presumed to be attending to, or more broadly to have access to, the event: pure evidentiality is about sources, whereas engagement is about the presumed presence or absence of intersubjective sharing, whatever the source. We will see later, however, that many languages exhibit complex interactions between engagement and evidentiality (Part II, §3).
As a second example, consider how one would translate ‘it’s the white people arriving’ into Andoke (Landaburu, Reference Landaburu, Guentchéva and Landaburu2007, p. 25). In a standard situation, with shared access to the event, the ‘shared engagement’ auxiliary base b- (2a) would be used – for example, where both the speaker and addressee are together in a canoe, the speaker hears the noise of a distant motor, and directs the addressee to pay attention to it, confident that they, too, will be able to hear it. On the other hand, the ‘unshared engagement’ auxiliary base in (2b) would be used in situations where (i) the interlocutor does not have direct access to the event described, but (ii) the speaker is sure of their assertion. A strong internal revelation to the speaker would be one such context; another would be the case where the speaker is up in a tree and from there sees the white people, whose arrival would not be visible to the addressee, positioned at the foot of a tree in the forest.
-
(2) a. duiʌ́hʌ b-ə̃ dã-ə̃-ʌ
whites +spkr+addr.engag-3pl ingr-move-3
‘It’s the whites arriving (as we can both witness).’
-
b. duiʌ́hʌ kẽ-ə̃ dã-ə̃-ʌ
whites +spkr-addr.engag-3pl ingr-move-3
‘It’s the whites arriving (which I know / can witness but you can’t).’
This initial two-way contrast (shared accessibility versus speaker-only accessibility) is, in turn, part of a four-valued set of auxiliary bases (with a further subdivision of one value) whose other members deal with cases where the speaker lacks knowledge. In the case of true questions, where the interlocutor can be expected to know the answer, the pair k-/d- is used (Landaburu, Reference Landaburu, Guentchéva and Landaburu2007, p. 27): k- for polar (yes-no) questions such as ‘Is it the whites who are arriving?’ (3a), and d- for WH-questions like ‘Who is coming?’ (3b). The fourth value, coded by bã-, is used for self-interrogatory questions to which the speaker expects no answer from their interlocutor, who is simply a witness to the speaker’s deliberation; that is, the event is presented as inaccessible to both parties (3c). Footnote 9
-
(3) a. duiʌ́hʌ k-ə̃ dã-ə̃-ʌ
whites -spkr+addr.engag.pq-3pl ingr-move-3
‘Is that the whites arriving?’
-
b. kói d-ə̃ dã-ə̃-ʌ
who -spkr+addr.engag.iq-3pl ingr-move-3
‘Who is arriving?’
-
c. duiʌ́hʌ bã-ə̃ dã-ə̃-ʌ
whites -spkr-addr.engag.pq-3pl ingr-move-3
‘I wonder if those are the whites coming’. (Landaburu, Reference Landaburu2005, p. 2)
As Guentchéva and Landaburu (2007, p. 5) put it, the contrast between the auxiliary bases of Andoke “is better seen, not simply as a relation between the speaker and the truth of their statement but also … as a relation between what the interlocutors know”. Footnote 10 Further, Landaburu argues (2007, p. 30) that “as well as the knowledge of the speaker, we are dealing here with relations of epistemic authority between the speaker and the hearer. The speaker’s judgment of the truth of his proposition combines with the intersubjective dimension of the proposition, inside the grammatical system and not simply in perlocutionary or pragmatic effects.” Footnote 11
As Table 1 shows, Landaburu posits an orthogonal pairing of two two-valued semantic dimensions, neatly accounting for the functional symmetry of the Andoke system. (He treats k-/d- as specific variants conditioned by polar vs. WH-question as seen above.)
table 1. The Andoke engagement paradigm as a 2 x 2 matrix (Landaburu, 2007, p. 30)

We adapt his terminology slightly in the translation process, substituting ‘knowledge’ vs. ‘lack of knowledge’ for his terms ‘savoir’ vs. ‘non-savoir’, and ‘speaker’ and ‘addressee’ for his ‘je’ vs. ‘tu’. In addition to these merely translational changes, we comment here on two more substantive problems of terminology. First, Landaburu’s terminology conceals a deep asymmetry: the speaker knows what they themselves know, but can only presume what the addressee knows, so that a more realistic characterisation of the terms in the left-hand column would be ‘presumed addressee (lack of) knowledge’, an issue we return to in §4 under the rubric ‘multiple perspective’. Second, neither Landaburu’s savoir nor its rough English equivalent ‘knowledge’ fully convey the range of the addressee’s mental dispositions: arguably, the crucial difference between the (a) and (b) example in each case concerns differential accessibility to the speaker and the addressee. In some of his examples it is clearly knowledge that is at issue, but in others, such as the ‘sunrise’ examples in (1), attention seems the more crucial mental disposition.
Landaburu presciently observes (2007, pp. 30–31) that it was unlikely that the contrasts he described there would be found just in Andoke, and that further research would probably turn up comparable phenomena elsewhere. Moreover, he suggests that an emphasis on speaker-knowledge, at the expense of the epistemic relations between speaker and addressee, results from the influence of traditional grammar (whose assumptions were then imported into formal logic), itself reflecting the contingent privileging of certain grammatical categories (tense, aspect, mood) in the classical Indo-European languages.
There are, of course, important and familiar exceptions to the lack of attention paid to grammaticalised epistemic relations between speaker and hearer. The most important are (a) the definiteness contrasts expressed in article systems in western European languages, Footnote 12 (b) focus systems responsive to information structure, Footnote 13 and (c) discourse particles Footnote 14 like German doch ‘after all, actually (against earlier expectation)’ or Italian mica ‘not at all (against earlier positive expectation)’ which express incompatibilities between an asserted state and that presumed to have been the case at some prior moment in the discourse. Footnote 15 For many investigators of information structure, which takes in “such psychological phenomena as the speaker’s hypotheses about the hearer’s mental states” (Lambrecht, Reference Lambrecht1994, p. 3), it is a precondition that “what one individual may know or hypothesize about another individual’s belief-state” is only of analytic interest “insofar as that knowledge and those hypotheses affect the forms and understanding of LINGUISTIC productions” (Prince, Reference Prince and Cole1981, p. 233).
All of these studies, then, are relevant to the domain of intersubjective coordination. But as we will show, they represent only a fraction of the grammatical design space. With the wider typological sample we adduce, it is clear that the world’s grammars attest a much wider set of intersubjectively relevant categories than has previously been suspected. The initial typological framework we propose here aims to set out a broad programme of typological research that systematises the great diversity of grammatical devices in the intersubjective domain, along the following two axes:
-
(i) scope, be it semantic or syntactic (entity/location/referent, state of affairs/proposition, evidence/metaproposition),
-
(ii) intersubjective distribution (epistemic authority can be speaker, addressee, neither, or both).
A note on terminology before we proceed. Rather than burden the overworked term intersubjectivity with one further use, we will follow Landaburu’s lead in using the term engagement to refer to a grammatical system for encoding the relative accessibility of an entity or state of affairs to the speaker and addressee. Footnote 16 This definition clearly relates to Du Bois’ (Reference Du Bois and Engelbretson2007, p. 144) notion of ‘alignment’, “the act of calibrating the relationship between two stances, and by implication between two stancetakers”. Footnote 17 But whereas his term is intended to be broadly functional, we reserve engagement for grammaticalised systems, which are only one means of addressing the alignment problem. Likewise, while the term ‘stance’ has been employed in somewhat similar ways by various authors, it is generally used in a broadly functional way rather than focusing on grammaticalised systems: examples are Heritage’s (Reference Heritage2012a, p. 6) definition of ‘epistemic stance’ as concerning “the moment-by-moment expression of [social] relationships, as managed through the design of turns at talk”, or Engelbretson’s (Reference Engelbretson2007) more general definition of stance as expressing ‘a personal belief or attitude’ or ‘social value’.
Finally, a remark on the trajectory by which categories are ‘typologically detached’ from semantically related categories that they share expression with in many languages. In laying out their analyses, it is helpful for typologists to work with canonical, neatly cut-and-dried categories (Brown, Chumakina, & Corbett, Reference Brown, Chumakina and Corbett2013), so as to illustrate the dimensions of the design space with maximal clarity. But the relation of engagement to epistemic categories means that it borders on many more familiar linguistic categories: evidentiality, miratives, focus, mood, and modality. Footnote 18
And much of the time actual languages run some of these dimensions together. This may arise through conventionalised polysemous extensions across categories, e.g., the well-known case of Turkish -mIş, used both for evidential categories and for miratives (Aksu-Koç & Slobin, Reference Aksu-Koç, Slobin, Chafe and Nichols1986; Slobin & Aksu-Koç, Reference Slobin, Aksu-Koç and Hopper1982). Or it may come about by exploiting inferences from one type of interpretation to another, e.g., by applying hearsay evidentials to one’s own past behaviour to indicate ironical disbelief or lack of responsibility for one’s unconscious actions (see, e.g., Michael, Reference Michael2012; Wilkins, Reference Wilkins1986). Our general strategy, in unfolding the typological framework we develop here, is to begin each major section with more clear-cut cases and then look at more complex and transitional ones.
3. Epistemic management in conversation
In a series of papers, John Heritage discusses the related notions of ‘epistemic status’, ‘epistemic stance’, ‘epistemic gradient’, and ‘territories of knowledge’ in an effort to account for the relation between sentence-type and communicative function, and how this is seen in the sequential unfolding of turns as a form of social action (Heritage, Reference Heritage, Ford, Fox and Thompson2002, Reference Heritage, Stivers, Mondada and Steensig2011, Reference Heritage2012a, Reference Heritage2012b, Reference Heritage, Sidnell and Stivers2013; Heritage & Raymond, Reference Heritage and Raymond2005, Reference Heritage, Raymond and De Ruiter2012). He argues that epistemic status and epistemic stance are keys to understanding the discrepancies between grammatical form and (social) action, an issue that has plagued speech-act theory since its formulation (Austin, Reference Austin1962; Searle, Reference Searle1969) and necessitated the label ‘indirect speech-acts’ to account for such discrepancies (see Levinson, Reference Levinson1979, Reference Levinson1983, for a critique).
Epistemic status, as an index of relative epistemic authority, is formulated with reference to the notion of A- and B-events (Labov & Fanshel, Reference Labov and Fanshel1977): A-events are known only to the speaker (speaker authority) and B-events are known only to the addressee (addressee authority). Typical B-events include the addressee’s opinions, beliefs, bodily states, or professional expertise. The observation that authority to comment on events is unevenly distributed across speech-act participants is also explored in detail by Kamio (Reference Kamio1997), who notes the infelicity of Japanese statements that target the addressee’s ‘territory of information’ unless these are marked by appropriate sentence-final particles, which serve to weaken the speaker’s epistemic claims and mitigate the force of such statements. Kamio’s conceptualisation of ‘territories of information’ is adopted by Heritage to define epistemic status as a relatively stable concept subject to socio-cultural conventions:
[W]e can consider relative epistemic access to a domain as stratified between actors such that they occupy different positions on an epistemic gradient (more knowledgeable […] or less knowledgeable […] which itself may vary in slope from shallow to deep …). We will refer to this relative positioning as epistemic status, in which persons recognize one another to be more or less knowledgeable concerning some domain of knowledge[.] (Heritage, Reference Heritage2012b, p. 32)
The heuristic of an ‘epistemic gradient’ allows for a relative positioning of the speech-act participant’s knowledge-states and rights to knowledge. This notion has been used, for example, in cross-linguistic research on sentence-final particles that signal different kinds of questions (see Enfield, Brown, & de Ruiter, Reference Enfield, Brown, de Ruiter and de Ruiter2012; Hayano, Reference Hayano2012). The notion of epistemic gradient may be used to determine a speaker’s epistemic stance, as indicated by the speaker’s choice of sentence-type.
Heritage’s efforts to detail how the epistemic statuses of speech participants shape turn-design enable us to look under the hood of the ‘epistemic engine’ of conversation (Heritage, Reference Heritage2012b). Indeed, language users are continuously keeping track of what others know and how their own knowledge can be related to the knowledge of others, and Heritage offers us a detailed and empirically grounded picture of how this ‘epistemic ticker’ works in everyday conversation.
There are, however, some issues that concern us in exploring the notion of ‘engagement’ from a cross-linguistic perspective, which are left mostly without comment in Heritage’s work. One particularly important issue is what (linguistic) resources are available for conveying epistemic stance. While sentence-type has occupied a central role in research on English, linguistic forms signalling aspects of epistemic status and stance go well beyond sentence-type distinctions and may involve grammatical sub-systems that specifically target the perception, attention, and perspective of the speech participants, without requiring reformulation as interrogatives.
A final consideration is that Heritage’s formulation of an epistemic gradient remains underspecified with respect to the individual commitments of the speech participants. That is, while a ‘seesaw’ gradient is conceptually useful, it veils the fact that the speaker’s assumptions concerning the addressee’s knowledge of some event are ‘in the mind of the speaker’ and do not necessarily correspond to the addressee’s actual knowledge state (see below, Evans, Reference Evans2006; cf. Bergqvist, Reference Bergqvist2015). The notion of multiple perspective, which we discuss in the next section, provides this underlying asymmetry with an explicit formulation, where the speech participant’s points-of-view with respect to objects of discourse are calculated from the speaker’s perspective.
4. Multiple perspective in grammar
As mentioned already, there is a clear asymmetry in the contrasts of epistemic distribution which engagement expresses. Whereas speakers have direct access to their own perspective, and can thus assert with confidence what they know, attend to, or perceive, in the case of the addressee they can only assume, to varying degrees of certainty. Assessments of the mental directedness of others therefore involve a type of complex perspective (Evans, Reference Evans2006), which represents the speaker’s assumption about the addressee’s attentional state or access with respect to some state of affairs. Footnote 19
As a caution that not all investigators have taken this as obvious, consider the discussion of definite articles in Givón (Reference Givón1989), and in particular his statement that definite descriptions are “inherently about knowledge by one mind of the knowledge of another mind” (p. 206). We do not share Givón’s epistemological optimism – that one mind can have knowledge of the knowledge of another mind. As a more accurate and epistemologically cautious characterisation, we prefer the formulation given in Hawkins (Reference Hawkins1978, p. 97): “the speaker when referring [and choosing between definite and indefinite articles – authors] must constantly take into consideration knowledge of various kinds which he assumes his hearer to have.” Footnote 20 This asymmetry – i.e., that assessments of knowledge or attention by the interlocutor are based on assumptions by the speaker – should be borne in mind throughout our discussion.
Multiple perspective constructions are constructions that “encode potentially distinct values, on a single semantic dimension, that reflect two or more distinct perspectives or points of reference” (Evans, Reference Evans2006, p. 99). These are found in various parts of the grammar and fall into three kinds of perspectives: double, meta-, and complex perspective.
‘Double perspective’ is calculated with regard to two points of reference at once, each having equivalent epistemological status. An example is a demonstrative system like Japanese, where both the speaker’s and the addressee’s positions are taken into account when relating a figure to a location (e.g., Japanese: kore ‘speaker proximate’, sore ‘addressee proximate’, are ‘proximate to neither speaker nor addressee’; see Hinds, Reference Hinds1973). Double perspective constructions are likely to be limited to ‘transparent dimensions of experience’ such as space and time, as these do not require calculations regarding the attention and psychological state of others: the stated perspectival values of double perspective constructions are objectively verifiable. (As we shall see, however, this does not mean that spatial demonstratives cannot develop less epistemologically transparent uses, including psychological and attentional parameters – see §5, below.)
Meta- and complex perspective constructions are defined by the embedding of one perspective inside another. In meta-perspective constructions the perspective of one person is considered from the perspective of another. This can be seen in reported speech constructions such as, He said (that) linguistics has high standards of evidence, where the speaker asserts a report of another’s assertion, but does not directly represent the speaker’s position regarding the secondary assertion, i.e., linguistics has high standards of evidence.
Complex perspective features the speaker’s assertion of his/her own perspective along with that assumed by the speaker to hold for the addressee/other. The sentence He is under the illusion that linguistics has high standards of evidence, by using an anti-factive predicate in the main clause, simultaneously predicates one perspective of the embedded subject (who believes linguistics has high standards of evidence) and a different perspective of the speaker (who believes that any claim that linguistics has high standards of evidence is illusory). Summarising the contrast, a meta-perspective does not require the speaker’s evaluation regarding the perspective of the other (although it may be present by implicature), whereas a complex perspective features non-defeasible assertions regarding both parties.
In the context of epistemic marking, multiple perspective constructions are arguably restricted to variants of meta- and complex perspective if one concedes that the perspective of the other necessarily is embedded in the speaker’s perspective. The conceptualization of multiple perspective in epistemic marking targets the same issues that Heritage (Reference Heritage, Stivers, Mondada and Steensig2011, Reference Heritage2012a, Reference Heritage2012b, Reference Heritage2012c) details for epistemic status and stance, but with an increased focus on the different ways in which perspectives may be expressed, and what subsystems of language facilitate such expressions.
5. Demonstratives and the coordination of attention to objects and places

Arguably the most basic of intersubjective tasks in conversation is to coordinate the speaker’s and addressee’s attention on an object present in the context, by drawing the latter’s attention towards that object through pointing or eye-gaze. After a long period when the typology of demonstrative systems was dominated by their spatial properties (Anderson & Keenan, Reference Anderson, Keenan and Shopen1985; Diessel, Reference Diessel1999a, Reference Diessel1999b; Dixon, Reference Dixon2003), the field is unveiling a growing number of cases where demonstratives can best be understood as grammatical devices for bringing one’s interlocutor’s attention into line with one’s own (cf. Janssen, Reference Janssen and Brisard2002). As Hausendorf (Reference Hausendorf and Lenz2003, pp. 257–9) puts it:
How can we account for the transition from single perceiving activities to mutually shared perception? … Whenever sensory perception is to be extended or differentiated in order to make use of what can be seen, heard, smelt or touched in the physical environment, deictic devices can be expected to make sure that these perceiving activities become mutually shared. … I would propose to consider deixis as a device whose main function is to ‘help’ perceiving activities to become mutually shared communicative moves. … Deixis allows visual perception to be perceived in itself.
Classic typologies of demonstrative systems (e.g., Anderson & Keenan, Reference Anderson, Keenan and Shopen1985) looked at the degrees of distance from the origo or speaker: two in (modern) English (this/that), three in Spanish (este, ese, aquel, using the analyses of Hottenroth, Reference Hottenroth, Weissenborn and Klein1982, and Diessel, Reference Diessel1999a), and seven in Malagasy (but with an additional visible/invisible contrast that gives fourteen; Rasoloson & Rubino, Reference Rasoloson, Rubino, Adelaar and Himmelmann2005). These may then be elaborated by other spatial characteristics like up/down, upstream/downstream, etc. Despite their great variety, on these accounts all are fundamentally egocentric systems.
The next level of interpersonal complexity adds the possibility of taking other parties to the conversations as anchor point. Again, staying at the simplest level, entities can next be related to speaker, addressee, both, or neither, e.g., the three-way contrast in Japanese (kore speaker-proximal vs. sore addressee-proximal vs. are other), or the four-way contrast which is obtained in Quileute (Andrade, Reference Andrade and Boas1933, p. 252) by adding a fourth ‘first inclusive’ value: x̣o´’o ‘near the speaker’, so´’o ‘near the second person’, sa´’a ‘at a comparatively short distance from both’, áˑtca’a ‘at a long distance’. Burarra (Glasgow & Glasgow, Reference Glasgow and Glasgow1977) is similar, with some interesting further twists. Footnote 21
Systems that take more than one conversational party as spatial anchor points may then be elaborated further by taking degrees of distance from two or more of these reference points. Abui, for instance (Kratochvil, Reference Kratochvil2007, Reference Kratochvil2011) has speaker-proximal, addressee-proximal, speaker-medial, addressee-medial, and distal (note that the speaker vs. addressee anchor point becomes irrelevant once the referent is far enough away), among other values bringing in factors like elevation. For example, one would say do fala for ‘this house, near me’, to fala for ‘that house, near you’, o fala or lo fala for ‘that house, some distance from me (but closer to me than you)’, yo fala for ‘that house, some distance from you (but closer to you than me)’, and oro fala for ‘that house (far from us both)’. Inuktitut (Denny, Reference Denny1982) is another example of a language where there are two sets of demonstratives – speaker-anchored vs. other-anchored – where the second set may be anchored to a previous speaker, to the addressee, or to some other person or thing in the situation, which may not have been referred to before.
With these systems, we have now brought in interpersonal space – through the choice of speaker, addressee, both, or other as spatial anchor point – but not yet any intersubjective considerations, at least as far as most such systems are normally described – though one suspects that, for example, locations near the addressee are assumed to be more accessible to their attention, and even early accounts that focus on spatial semantics allow for metaphorical extensions into psychological domains. Footnote 22
At a third level of elaboration, perceptual modality enters the typology. We have already mentioned that Malagasy distinguishes visible from non-visible in addition to seven grades of distance. In Santali (Zide, Reference Zide, Barrau, Thomas, Bernot and Haudricourt1972, digesting material from Bodding, Reference Bodding1929) demonstratives can add -tɛ for objects perceived visually and -nɛ for objects perceived by other senses which means, usually, aurally. Quileute (Andrade, Reference Andrade and Boas1933, p. 252), in addition to the four person-oriented forms mentioned above, has three forms for different types of partly or wholly invisible location: one for where they are nearby and maybe partly visible, one for where they are invisible but in a known location, and one where they are invisible and also in an unknown location. Footnote 23 The detailed analyses of the Yucatec Maya demonstrative system by Hanks (Reference Hanks1990, Reference Hanks1999, Reference Hanks, Enfield and Stivers2007, Reference Hanks2009) show not only that there are formal contrasts based on a three-way contrast in sensory modality (visual, tactile, auditory/olfactory) in addition to distance, but also that the system is best understood as providing a “directive function … whereby they direct an addressee to look, listen or take an object in hand” (Hanks, Reference Hanks1999, p. 124).
Our journey through demonstrative systems has thus led us into increasingly intersubjective terrain. Starting with a primarily spatial system, Footnote 24 we passed to systems which recognise other conversational participants as the anchor point for reckoning spatial relations, then on to those which direct the sensory modality which their interlocutors should use in searching for referents. We now raise the intercognitive status a final notch, examining demonstrative systems that explicitly encode the speaker’s assumptions about whether the addressee has succeeded in locking onto the referent.
The first language for which this was shown clearly was Turkish, in studies by Aslı Özyürek (Reference Özyürek, Santi, Guaitella, Cave and Konopczynski1998) and her colleagues Sotaro Kita (Özyürek & Kita, n.d.) and Aylin Küntay (Küntay & Özyürek, Reference Küntay, Özyürek, Skarabela, Fish and Do2002, Reference Küntay and Özyürek2006). Turkish has a three-valued demonstrative system with three forms bu, şu, and o, which had previously been analysed as a person-based system on Japanese lines (e.g., Lyons, Reference Lyons1968) or as a distance-based system on Spanish lines (Bastuji, Reference Bastuji1976; Serebrennikov & Gadzuyeva, Reference Serebrennikov and Gadzuyeva1979). However, these early analyses drew their base data from written texts in which the dynamics of face-to-face interaction could not be gauged accurately. Özyürek and her colleagues broke new ground by using videos of face-to-face interaction in which it was possible to track eye-gaze and pointing Footnote 25 behaviour at the same time as demonstrative use, leading to the following breakthrough.
Two of the Turkish demonstrative forms, bu and o, appear to be used roughly like English this and that, contrasting entities close to and distant from the speaker. It is the third form şu which is unusual compared to previously studied systems: it can be used for objects at any distance, but only if joint attention has not yet been established. This gives us the following set (Table 2), adjusting the first two for the fact that, unlike English, they require joint attention to be established in addition to specifying distance.
table 2. The Turkish demonstrative system (after Özyürek & Kita, n.d.; Küntay & Özyürek, 2002)

Consider the following example from the work of Özyürek and her colleagues. A teacher and two students are in a pottery class and one of the students wishes to refer to an object that is at the other end of the room. She points to it but the teacher’s gaze has yet to fix on it (example (4) and Figure 1); at this point she uses the term şu:
-
(4) ya hocam şu oval mesela
well teacher nonmutdem oval for.example
‘well sir that oval(one) for example’
In a second, more elaborated, utterance, in which she keeps pointing to the vase but the teacher’s gaze has yet to lock onto it (example (5) and Figure 2), she continues to use the possessive form of şu, namely şunun ‘of that one (which you have yet to identify):
-
(5) şu- nun dış yüzey-in-e koy-up da
nonmutdem-gen outer surface-gen-dat put-ger connec
‘by putting it on that thing’s outer surface’
Finally the teacher’s gaze moves up to follow the point and locate the referent (example (6) and Figure 3), and now the speaker switches to o, the form for distant but mutually attended objects (o is suffixed by (n)dan to mean ‘from that’):
-
(6) o ndan da olabilir
dist:abl and possible
‘That could be one as well.’
We can summarise how the Turkish deictic routine works in the following way: use a combination of pointing plus şu until you are sure of having achieved mutual attention on the object at issue, then proceed by using bu or o according to the distance to the referent.

Fig. 1. Use of Turkish demonstratives (a).

Fig. 2. Use of Turkish demonstratives (b).

Fig. 3. Use of Turkish demonstratives (c).
Our second example comes from work by Niclas Burenhult (Reference Burenhult2003, Reference Burenhult2008) on the Aslian language Jahai, spoken in Malaysia. Jahai has a set of eight demonstratives which can be arranged as in Table 3. The forms starting with a glottal stop (ʔ) are adverbials like ‘here’, while those starting with t are nominal demonstratives with meanings like ‘this’, but the logic of these two series is otherwise identical.
table 3. Jahai demonstratives (Burenhult, Reference Burenhult2003)
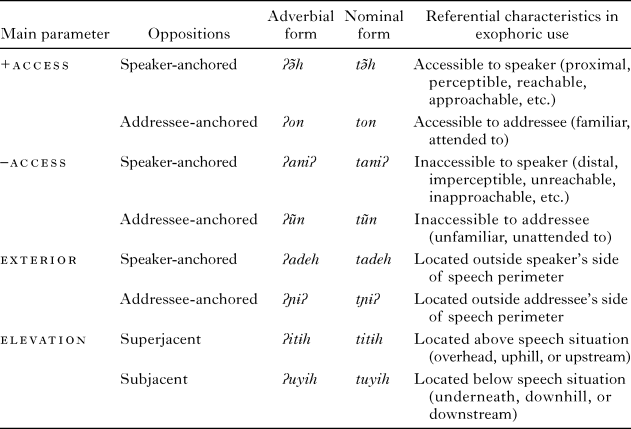
According to Burenhult, the Jahai conceive of conversation as a sort of container, and as “soon as a person addresses another person, they and the area between them become a connected spatial entity” (Burenhult, Reference Burenhult2008, p. 116). The last four pairs in the table position objects with respect to that container. If we imagine it cut in half by a line between the speaker and the addressee, those on the speaker’s side but outside the container will be denoted by tadeh, those outside it but on the addressee’s side by tɲɨʔ. Those conspicuously above or below the speech situation will be identified using the so-called superjacent or subjacent demonstratives from the ‘elevation’ set.
But it is the top four which interest us more here, and in particular the ‘addressee-anchored accessible’ ton. Burenhult obtained revealing data on this system using a ‘director-matching task’ where a ‘director’ has a photograph of different arrangements of objects, which he describes orally to a ‘matcher’ whose job is to reproduce the arrangement using real objects. In addition to his own photograph, the director can see the matcher and what he is setting out, whereas the matcher can only see his own objects and needs to rely on the director’s verbal description. Under these circumstances, discourses are produced which typically begin with the director’s introduction of a referent (e.g., ‘take the one which is flat and round’), proceed with a sequence of demonstrative exhortations by the director as he monitors what the matcher is doing (‘Underneath the one that has a hole. A different one, different one, different one. This one.’) and end with a confirmation (‘Yes, that one!’). The predominant pattern through these discourses is to culminate in the ‘addressee-anchored accessible’ ton after a series of other demonstratives giving spatial specification (examples (7) & (8)).
-
(7) tũn – tɲɨʔ – ton ‘that (on your side but so far inaccessible to you) – that way over\on your side – that.one.now’
or
-
(8) taniʔ – taniʔ – ton ‘this one (inaccess.) – this one (inaccess.) – that one now!’
The way the Jahai demonstratives track the speaker’s monitoring of the addressee’s attention is thus rather similar to Turkish, but the actual progression is almost the converse (see Table 4). The initial şu forms in Turkish give no spatial information of their own, merely telling the addressee to keep looking (in particular, to follow the point), but once lock-in has been achieved they give way to spatially specific forms (close to or far from speaker). In Jahai the forms used give much more spatial information as the progression unfolds – is it in the speaker’s or the addressee’s half of the container, or close to the speaker or the addressee? But once lock-in has been achieved, the form ton is used regardless of exact spatial position, as if the attentional accessibility of the object now makes spatial information unnecessary.
table 4. Comparison of semantic contrasts during the search and lock-in phases in Turkish and Jahai demonstrative systems

Before leaving these two systems, an observation is in order about the communicative ecology of pointing on the one hand and the demonstrative system on the other. The Turkish example makes it clear that achieving reference in conversation combines both gestural and linguistic elements as the demonstrative şu signals to the addressee to keep attending to the point. Indeed, Küntay and Özyürek (Reference Küntay, Özyürek, Skarabela, Fish and Do2002), who were puzzled by the fact that children still have not mastered the correct use of şu by the age of six despite the well-attested abilities of much younger children to monitor the gaze of adults, suggest that the delayed development is due to the extra cognitive demands of coordinating linguistic and gestural elements. Footnote 26
On the other hand, in Jahai the use of actual pointing is much more limited. Within the experimental ‘director–matcher’ set-up, pointing was not an allowable part of the procedure. And in more naturalistic settings Burenhult mentions a number of reasons why pointing is much less common among Jahai than among most other cultures: communication often occurs while walking single-file along forest paths, or between spouses after dark, and in any case there are a number of cultural taboos against pointing. He goes on to suggest that the elaboration of the Jahai demonstrative system, which in effect gives a complex series of clues as to how the addressee should keep looking, compensates for the unavailability of pointing in many circumstances.
We draw our examination of demonstratives to a close by looking more briefly at two further examples where monitoring of the addressee’s attention and expectations is relevant, though not in the sense we have seen of directly tracking whether they have latched onto the referent but rather in helping them assess its identification against previous expectations or searches.
The first comes from the Australian language Bininj Gun-wok, Gun-djeihmi dialect (Evans, Reference Evans2003). Among a large number of demonstratives (and just giving the masculine forms, beginning with na-), an interesting part of this system is the intersection of distance with whether the speaker deems the addressee to have had some previous interest in the entity at issue. Let’s say you are looking for something without success, and I spot it: I would then say either nabernu (if it is distant) or nabehrnu (the h represents a glottal stop) if it is close to hand. On the other hand, if I present something which I didn’t think you had been interested in before (say I find a new plant which you didn’t know existed) I could hold it up to you and say nahni. In other words, the system tracks pre-existing cognitive interest (or not) on the part of the addressee, and crosses this with distance.
A related phenomenon is attested for the Athapaskan language Kaska, namely the class of directionals (Moore, Reference Moore2002, ch. 19; the term is also used by Golla, Reference Golla and Goddard1996), also referred to in the Athabaskanist literature as ‘deictic/directionals’ (Rice, Reference Rice1989), and ‘locationals’ (Henry & Henry, Reference Henry and Henry1969). Leer (Reference Leer, Cook and Rice1989) has proposed that these derive from old sequences of a demonstrative plus a noun. Kaska directionals resemble demonstrative adverbs, and are built from two parts. The stem has spatial meanings like ‘off to the side’, ‘above’, ‘below’, ‘downstream’, ‘back down a trail’, or temporal meanings like ‘past’ or ‘future’. But it is the prefix which concerns us here, since these are sensitive to shared or unshared knowledge states.
Of crucial interest is the way three of the prefixes indicate different distributions of knowledge about the location across the speaker and addressee:
With reference to the more distant locations, the directional also indicates whether the speaker and the addressee know the exact location being referred to. For instance, the prefix kúh- is used when the exact location is known by both the speaker and those they are addressing. As other examples, the prefix de- is used when the location is known by the speaker, but not those they are addressing, and the prefix ah- is used when neither the speaker nor their audience know the exact destination, but only its approximate direction. (Moore, Reference Moore2002, p. 404; italics added)
In terms of the four-way set of engagement values we found for Andoke (§2), this set covers three of the values: speaker-only, shared, and known to neither. It is only the fourth term – for the situation where the speaker does not know the exact location, but expects that the addressee might – that appears to be missing from this system. Footnote 27
Finally, we note that marking the mutual knowledge of speaker and addressee as regards an entity also appears to be relevant to what have been analysed as evidential morphemes either within or outside demonstrative systems, although these are generally less well understood and less documented cross-linguistically (see Reference Jacques and AikhenvaldJacques, in press). Storch and Coly (Reference Storch, Coly, Aikhenvald and Dixon2014, p. 8) describe the suffix -dìyà in Maaka (Nigeria) as indicating “that both speaker and hearer know or see the participant in question” (9). They further comment that this form originates from a Kanuri term meaning ‘surely, entirely, only’, highlighting the connection between joint witnessing and the establishment of truth (see also comments reproduced from Sillitoe, Reference Sillitoe2010, in Part II, §3).
-
(9) ʔáa-kè-díɓɓ zùlúm-tò- dìyà
cond-2sg:masc-crush:perv anus-poss:3sg:fem-joint:vis
tà-kwáadà-ntí-mìnê gè-ʔámmà-à
3sg:fem-throw:tr-assert-obj:1pl loc-water-DEF
‘If you crush her anus [that we can both see] she will definitely throw us into the water.’ (Storch & Coly, Reference Storch, Coly, Aikhenvald and Dixon2014, p. 197)
Across the world, in the South American language Lakondê (Telles & Wetzels, Reference Telles, Wetzels, Carlin and Rowicka2006) a nominal morpheme -te- ‘n.prox’ is described as encoding both spatial distance and mutual visual perception. For example, ‘sih-te-‘te ‘house-n.prox-ref’ is translated as ‘house which we see at a distance’. Footnote 28 Such nominal markers seem to be a genetic feature of Mamaindê languages and are especially elaborate in Southern Nambiquaran, which has aspect, tense, evidential, and engagement (termed ‘individual/collective verification’; Kroeker, Reference Kroeker2001) marking on definite nouns (Lowe, Reference Lowe, Dixon and Aikhenvald1999, p. 282). For example, the expression wa3lin3su3ait3tã2 (numbers indicate tones) is glossed as ‘this manioc root that I, but not you, saw some time in the past’ and may be contrasted to wa3lin3su3ait3ta3li2, meaning ‘this manioc root that we (both) saw some time in the past (Lowe, Reference Lowe, Dixon and Aikhenvald1999, p. 282; cf. Kroeker, Reference Kroeker2001, pp. 45–6). The meaning contrast between individual and collective verification of the manioc root may be traced to the -tã2 (individual verification) and the -li2 (collective verification) suffix at the ends of the nominals. The complexity of Southern Nambiquaran, while staggering at first glance, is suggestive of the potential range of variation and the richness of such systems.
We have focused in such detail here on demonstratives because they are the syntactically simplest method of achieving mutual coordination – as investigators have pointed out, from Bühler Footnote 29 (as quoted in the epigraph to this section) on to Diessel:
demonstratives function to coordinate the interlocutors’ shared attentional focus. In the simplest case, the demonstrative is used to direct the addressee’s attention to a referent that previously was not in the shared attentional focus; in this case, the demonstrative creates a new joint focus of attention. However, demonstratives are also commonly used to direct the addressee’s attention from the current referent to a previously established referent or to differentiate between multiple referents that are already in the shared attentional focus. (Diessel, Reference Diessel2006, p. 470)
Demonstratives generally distinguish a reasonably large set of ontological categories – entities (this), places (here), times (now), manners (thus), and so forth, welded together with deictics into sets like koko/soko/asoko ‘here / there [by you] / there (away from us both)’ in Japanese. However, the syntactic level at which they apply can be disarmingly simple. This makes it possible to use them in the most basic imaginable types of mini-dialogue, of the type discussed by Karcevski (Reference Karcevski1948/1969) Footnote 30 for Russian pairs like Ty kuda? Tuda. (‘You (’re going) whither?’ ‘Thither (accompanied by a suitable gesture).’); see Diessel (Reference Diessel2003) and Evans (Reference Evans and Schalley2012) for further discussion of these ‘dialogic parallelisms’.
These Karcevskian dialogues are possible because the semantics of the deictic expressions is essentially self-contained: Footnote 31 a pairing of a deictic value (e.g., proximal vs. distal) and an ontological one (e.g., place, or time, or manner). In Part II of this paper, we will pass to a number of systems where attentional coordination has been expanded to the point where it concerns not just objects, but the broader domain of events and the epistemic background to talking about them. There are some important differences between engagement as it can apply to objects (especially objects that are present in the speech situation) and as it applies to events and situations, which may require increased abstraction in reference, and, once in the past, are not available for ostension and must rather be remembered, learnt, believed, etc. We explore the complexity of encoding the differential accessibility of events using data from languages of the Americas, Papua New Guinea, and Northern India (for example: Did the speaker directly experience this event? Did the addressee experience it, too?). Finally, we see that, as regards the category of engagement, the distinction between objects and states of affairs is not so hard-and-fast: Abui shows that a diachronic pathway between the two can be traced via the increased functionality of demonstrative forms. And so we move from the world of entities, as discussed in Part I of this study, to the world of events, the topic of Part II.
Acknowledgments
We thank Laura Michaelis-Cummings for the opportunity to put forward the ideas in this paper through an invited paper to Language and Cognition. For institutional support of the research underlying it, we are grateful to the Australian Research Council (grants DP0878126 ‘Language and Social Cognition: the Design Resources of Grammatical Diversity’ and FL130100111 ‘The Wellsprings of Linguistic Diversity’), the Australian Research Council Centre of Excellence for the Dynamics of Language, the Alexander von Humboldt Foundation (Anneliese Maier Forschungspreis to Evans), the Swedish Research Council (dnr. 2011-2274), and the Netherlands Organisation for Scientific Research NWO (Netherlands Organisation for Scientific Research), Veni award 275-89-024, ‘Learning the senses: Perception verbs in child–caregiver interaction’, as well as to our respective host institutions: the Australian National University, Stockholm University, and Radboud Universiteit in Nijmegen. The ideas in this paper have emerged from discussions with many people, and we particularly thank the following: Niclas Burenhult, Bill Hanks, Sotaro Kita, Jon Landaburu, and Aslı Özyürek; we additionally thank Sotaro Kita and Aslı Özyürek for permission to reproduce figures from an unpublished paper they wrote on Turkish demonstratives that has influenced us deeply. Ron Planer, Matt Spike, Alan Rumsey, and Arie Verhagen gave much-appreciated helpful critical comments on an earlier version of this manuscript, as did two anonymous referees, and Susan Ford did an immaculate job in checking, formatting, and editing it.








 Open access
Open access