






1. Introduction
Scalar transport in turbulence plays significant roles in various practical applications, ranging across geophysical and environmental problems such as the advection and dispersion of pollutants in the atmosphere (Mazzitelli & Lanotte Reference Mazzitelli and Lanotte2012; Nironi et al. Reference Nironi, Salizzoni, Marro, Mejean, Grosjean and Soulhac2015), mixing of nutrients in the ocean (Bhamidipati, Souza & Flierl Reference Bhamidipati, Souza and Flierl2020; Chor Reference Chor2020), and chemical reactions in industrial flows (Hill Reference Hill1976; Dimotakis Reference Dimotakis2005). Scalar transport is also important from the perspective of fundamental turbulence research, with previous studies showing that the scalar field is a sensitive detector of the structures in turbulent flows, such that their study has yielded insights into the physics of turbulent flows themselves (Tong & Warhaft Reference Tong and Warhaft1994). The scalar field may feedback on the velocity field under certain conditions, such as for stratified turbulence or thermally driven turbulence (Lohse & Xia Reference Lohse and Xia2010; Zhang et al. Reference Zhang, Dhariwal, Portwood, de Bruyn Kops and Bragg2022). The focus of this paper is, however, on the case of passive scalars.
The transport of scalars in turbulent flows is challenging to understand both because of the complexity of the underlying turbulent flow that advects, stretches and compresses the scalar field, and also because of the molecular diffusion to which it is subject that leads to non-trivial differences compared to the transport of fluid particles (Ottino Reference Ottino1989; Warhaft Reference Warhaft2000). Indeed, while it has often been assumed that the statistical properties of passive scalars in turbulent flows should reflect the analogous properties of the underlying velocity field, e.g. a similarity in the statistical distribution of the turbulent kinetic energy and scalar dissipation rates, this is not in general the case. For example, it has been found that Kolmogorov's hypothesis of local isotropy of the small scales of a turbulent flow is strongly violated when applied to passive scalars, with both experiments and direct numerical simulations (DNS) finding that the skewness of the scalar derivative remains of the order of unity when a large-scale mean scalar gradient is imposed, while it would be zero for a locally isotropic flow (Mestayer et al. Reference Mestayer, Gibson, Coantic and Patel1976; Sreenivasan & Antonia Reference Sreenivasan and Antonia1977; Sreenivasan Reference Sreenivasan1991; Pumir Reference Pumir1994). This strong violation of small-scale isotropy of the scalar field is often attributed to the presence of ramp–cliff structures in the scalar field through which large and small scales of the scalar field are directly connected (Shraiman & Siggia Reference Shraiman and Siggia2000; Buaria et al. Reference Buaria, Clay, Sreenivasan and Yeung2021a). It has also been found that intermittency in the scalar field is even stronger than that for the velocity field (Watanabe & Gotoh Reference Watanabe and Gotoh2004). Indeed, even for a stochastic model where the velocity field has Gaussian statistics, the scalar field has non-Gaussian statistics (Kraichnan Reference Kraichnan1994; Tong & Warhaft Reference Tong and Warhaft1994; Antonia, Zhou & Zhu Reference Antonia, Zhou and Zhu1998; Mi et al. Reference Mi, Antonia, Nathan and Luxton1998; Falkovich, Gawedzki & Vergassola Reference Falkovich, Gawedzki and Vergassola2001). Another profound difference is that while the velocity field exhibits a dissipation anomaly (i.e. the averaged turbulent kinetic energy dissipation rate is independent of viscosity for high Reynolds numbers), the scalar field does not, with the scalar dissipation rate decreasing as  ${\sim }1/\log (Sc)$ as the Schmidt number
${\sim }1/\log (Sc)$ as the Schmidt number  $Sc$ is increased (Buaria et al. Reference Buaria, Clay, Sreenivasan and Yeung2021b). Interestingly, however, recent DNS results have shown that while the expected correspondence between the analogous velocity and scalar statistics is not observed for
$Sc$ is increased (Buaria et al. Reference Buaria, Clay, Sreenivasan and Yeung2021b). Interestingly, however, recent DNS results have shown that while the expected correspondence between the analogous velocity and scalar statistics is not observed for  $Sc\leqslant 1$, it is recovered for sufficiently large
$Sc\leqslant 1$, it is recovered for sufficiently large  $Sc$ (even for
$Sc$ (even for  $Sc=7$) where a viscous-convective sub-range emerges in the scalar field (Shete et al. Reference Shete, Boucher, Riley and de Bruyn Kops2022).
$Sc=7$) where a viscous-convective sub-range emerges in the scalar field (Shete et al. Reference Shete, Boucher, Riley and de Bruyn Kops2022).
In general, the properties of a passive scalar field depend upon both the Reynolds number  $\textit {Re}$ and Schmidt number
$\textit {Re}$ and Schmidt number  $Sc$, and in many practical problems, both
$Sc$, and in many practical problems, both  $\textit {Re}$ and
$\textit {Re}$ and  $Sc$ are large. For
$Sc$ are large. For  $Sc>1$, the smallest scale (in a mean field sense) in the scalar field is thought to be the Batchelor scale (Batchelor Reference Batchelor1959)
$Sc>1$, the smallest scale (in a mean field sense) in the scalar field is thought to be the Batchelor scale (Batchelor Reference Batchelor1959)  $\eta _B=Sc^{-1/2}\,\eta$, where
$\eta _B=Sc^{-1/2}\,\eta$, where  $\eta$ is the Kolmogorov length scale, therefore resolving flows with high
$\eta$ is the Kolmogorov length scale, therefore resolving flows with high  $\textit {Re}$ and
$\textit {Re}$ and  $Sc$ is very challenging using DNS (as well as experiments) due to the spatial and temporal resolution constraints. For problems where the small-scale properties of the scalar field are important, large eddy simulations are not helpful. It is therefore highly desirable to develop models for the small scales of the scalar field that are capable of handling large ranges of
$Sc$ is very challenging using DNS (as well as experiments) due to the spatial and temporal resolution constraints. For problems where the small-scale properties of the scalar field are important, large eddy simulations are not helpful. It is therefore highly desirable to develop models for the small scales of the scalar field that are capable of handling large ranges of  $\textit {Re}$ and
$\textit {Re}$ and  $Sc$, as well as being computationally efficient. One possibility is to develop Lagrangian models for the scalar gradients in turbulent flows, inspired by the corresponding models for the velocity gradient that have been highly successful both in terms of making predictions and leading to new insights into the small-scale dynamics of turbulent flows (Meneveau Reference Meneveau2011). Analogous models for scalars could be used to explore and understand the small-scale dynamics of scalar fields at
$Sc$, as well as being computationally efficient. One possibility is to develop Lagrangian models for the scalar gradients in turbulent flows, inspired by the corresponding models for the velocity gradient that have been highly successful both in terms of making predictions and leading to new insights into the small-scale dynamics of turbulent flows (Meneveau Reference Meneveau2011). Analogous models for scalars could be used to explore and understand the small-scale dynamics of scalar fields at  $\textit {Re}$ and
$\textit {Re}$ and  $Sc$ that are currently far out of reach using either DNS or experiments.
$Sc$ that are currently far out of reach using either DNS or experiments.
Lagrangian models for the velocity gradients are derived from the Navier–Stokes equations, but they require modelling/approximations for the pressure Hessian and viscous terms that are unclosed in the reference frame of a single fluid particle trajectory. Various models have been proposed, including the restricted Euler model (Vieillefosse Reference Vieillefosse1982), the stochastic diffusion model (Girimaji & Pope Reference Girimaji and Pope1990), the tetrad model (Chertkov, Pumir & Shraiman Reference Chertkov, Pumir and Shraiman1999), the recent fluid deformation model (Chevillard & Meneveau Reference Chevillard and Meneveau2006) and multifractal models (Borgas Reference Borgas1993; Pereira, Moriconi & Chevillard Reference Pereira, Moriconi and Chevillard2018), as well as closures based on random Gaussian fields (Wilczek & Meneveau Reference Wilczek and Meneveau2014; Johnson & Meneveau Reference Johnson and Meneveau2016) and, more generally, on tensor function representation of the unclosed terms (Leppin & Wilczek Reference Leppin and Wilczek2020). With the exception of the restricted Euler model, these models predict the steady-state, non-trivial properties of the velocity gradients in turbulent flows, including the preferential alignment of the vorticity with the intermediate strain-rate eigenvector, intermittency, and the multifractal scaling of the moments of the velocity gradients. Unfortunately, most of the models are capable of predicting flows only with low to moderate  $\textit {Re}$. Recently, the multi-level recent deformation of Gaussian fields (ML-RDGF) model has been developed, which was shown to predict DNS data accurately for arbitrary Reynolds numbers (Johnson & Meneveau Reference Johnson and Meneveau2017).
$\textit {Re}$. Recently, the multi-level recent deformation of Gaussian fields (ML-RDGF) model has been developed, which was shown to predict DNS data accurately for arbitrary Reynolds numbers (Johnson & Meneveau Reference Johnson and Meneveau2017).
In the equation for a passive scalar gradient along a fluid particle trajectory, the scalar gradient diffusion term is unclosed. A closed model for scalar gradients in turbulent flows was derived previously based on a simple linear relaxation model for the scalar gradient diffusion (Martín, Dopazo & Valiño Reference Martín, Dopazo and Valiño2005), with the velocity gradient in the equation specified using a restricted Euler model that was modified to include a linear damping term to model viscous effects (Martın, Dopazo & Valiño Reference Martın, Dopazo and Valiño1998). Although the model showed general qualitative agreement with DNS data, there were significant quantitative inaccuracies for a number of key quantities, including significant errors in the predictions for the alignments of the scalar gradients with the strain-rate eigenvectors, and significant underprediction of large fluctuations of the scalar gradients. More advanced models have also been proposed that use the recent fluid deformation approximation (Chevillard & Meneveau Reference Chevillard and Meneveau2006) to model the scalar gradient diffusion term (Gonzalez Reference Gonzalez2009; Hater, Homann & Grauer Reference Hater, Homann and Grauer2011). These models also yielded qualitatively reasonable predictions, but suffered from quantitative inaccuracies and can make predictions for only relatively low Reynolds numbers due to their use of the recent fluid deformation approximation (Chevillard & Meneveau Reference Chevillard and Meneveau2006). Our work significantly advances these models in two ways. First, the velocity gradients will be specified using the much more sophisticated ML-RDGF model that also allows for predictions to be made at arbitrarily large  $\textit {Re}$. Second, the recent deformation of Gaussian fields closure (Johnson & Meneveau Reference Johnson and Meneveau2016) will be used to provide a more sophisticated closure for the scalar gradient diffusion term. This closure leads to nonlinear terms that can regulate the growth of the scalar gradients in regions of intense stretching, which can be vital to preventing blow-ups from occurring in the model. The closure also accounts for a dependence on
$\textit {Re}$. Second, the recent deformation of Gaussian fields closure (Johnson & Meneveau Reference Johnson and Meneveau2016) will be used to provide a more sophisticated closure for the scalar gradient diffusion term. This closure leads to nonlinear terms that can regulate the growth of the scalar gradients in regions of intense stretching, which can be vital to preventing blow-ups from occurring in the model. The closure also accounts for a dependence on  $Sc$ by incorporating
$Sc$ by incorporating  $Sc$ into the model formulation.
$Sc$ into the model formulation.
Our model for the scalar gradients uses a forcing that generates a statistically stationary, isotropic flow. Depending on  $\textit {Re}$ and
$\textit {Re}$ and  $Sc$, the small scales of the scalar field that are associated with scalar gradients may or may not be sensitive to the details of the forcing of the scalar field (Sreenivasan Reference Sreenivasan2019; Shete et al. Reference Shete, Boucher, Riley and de Bruyn Kops2022). For regimes where the properties of the forcing are important, our model is easily adapted by replacing the random forcing term with the production term associated with the mean scalar gradient (which would be an input to our model, and our model would then describe the fluctuating component of the scalar gradients). Our model could then be applied quite generally to investigate fundamental questions regarding the intermittency of the small scales of a scalar (Watanabe & Gotoh Reference Watanabe and Gotoh2004), scalar dissipation anomalies (Buaria et al. Reference Buaria, Clay, Sreenivasan and Yeung2021b), and potential violations of small-scale isotropy (Mestayer et al. Reference Mestayer, Gibson, Coantic and Patel1976; Sreenivasan & Antonia Reference Sreenivasan and Antonia1977; Sreenivasan Reference Sreenivasan1991; Pumir Reference Pumir1994). It could also be employed for practical calculations of passive scalar mixing in numerous applications, including contaminants and gases in industrial, oceanic and atmospheric flows.
$Sc$, the small scales of the scalar field that are associated with scalar gradients may or may not be sensitive to the details of the forcing of the scalar field (Sreenivasan Reference Sreenivasan2019; Shete et al. Reference Shete, Boucher, Riley and de Bruyn Kops2022). For regimes where the properties of the forcing are important, our model is easily adapted by replacing the random forcing term with the production term associated with the mean scalar gradient (which would be an input to our model, and our model would then describe the fluctuating component of the scalar gradients). Our model could then be applied quite generally to investigate fundamental questions regarding the intermittency of the small scales of a scalar (Watanabe & Gotoh Reference Watanabe and Gotoh2004), scalar dissipation anomalies (Buaria et al. Reference Buaria, Clay, Sreenivasan and Yeung2021b), and potential violations of small-scale isotropy (Mestayer et al. Reference Mestayer, Gibson, Coantic and Patel1976; Sreenivasan & Antonia Reference Sreenivasan and Antonia1977; Sreenivasan Reference Sreenivasan1991; Pumir Reference Pumir1994). It could also be employed for practical calculations of passive scalar mixing in numerous applications, including contaminants and gases in industrial, oceanic and atmospheric flows.
2. Model for scalar gradients
2.1. Governing equations for instantaneous and characteristic variables
For an incompressible, Newtonian fluid, the equations governing the evolution of the fluid velocity gradient  $\boldsymbol{\mathsf{A}}\equiv \boldsymbol {\nabla } \boldsymbol {u}$ and scalar gradient
$\boldsymbol{\mathsf{A}}\equiv \boldsymbol {\nabla } \boldsymbol {u}$ and scalar gradient  $\boldsymbol{B}\equiv \boldsymbol {\nabla }\phi$ are
$\boldsymbol{B}\equiv \boldsymbol {\nabla }\phi$ are
 $$\begin{gather} D_t\boldsymbol{\mathsf{A}}={-}\boldsymbol{\mathsf{A}}\boldsymbol{\cdot} \boldsymbol{\mathsf{A}}-\boldsymbol{\mathsf{H}}+\nu\,\nabla^2 \boldsymbol{\mathsf{A}}+\boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}, \end{gather}$$
$$\begin{gather} D_t\boldsymbol{\mathsf{A}}={-}\boldsymbol{\mathsf{A}}\boldsymbol{\cdot} \boldsymbol{\mathsf{A}}-\boldsymbol{\mathsf{H}}+\nu\,\nabla^2 \boldsymbol{\mathsf{A}}+\boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}, \end{gather}$$ $$\begin{gather}D_t\boldsymbol{B}={-}\boldsymbol{\mathsf{A}}^{\rm T}\boldsymbol{\cdot} \boldsymbol{B}+\kappa\,\nabla^2\boldsymbol{B}+{\boldsymbol{F}}_{\boldsymbol{B}}, \end{gather}$$
$$\begin{gather}D_t\boldsymbol{B}={-}\boldsymbol{\mathsf{A}}^{\rm T}\boldsymbol{\cdot} \boldsymbol{B}+\kappa\,\nabla^2\boldsymbol{B}+{\boldsymbol{F}}_{\boldsymbol{B}}, \end{gather}$$
where  $D_t\equiv \partial _t +\boldsymbol {u}\boldsymbol {\cdot }\boldsymbol {\nabla }$ is the Lagrangian derivative,
$D_t\equiv \partial _t +\boldsymbol {u}\boldsymbol {\cdot }\boldsymbol {\nabla }$ is the Lagrangian derivative,  $\boldsymbol{\mathsf{H}}\equiv \boldsymbol {\nabla }\boldsymbol {\nabla }p$ is the pressure Hessian,
$\boldsymbol{\mathsf{H}}\equiv \boldsymbol {\nabla }\boldsymbol {\nabla }p$ is the pressure Hessian,  $p$ is the fluid pressure (divided by the fluid density),
$p$ is the fluid pressure (divided by the fluid density),  $\nu$ is the fluid kinematic viscosity,
$\nu$ is the fluid kinematic viscosity,  $\kappa$ is the scalar diffusivity, and
$\kappa$ is the scalar diffusivity, and  $\boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}, {\boldsymbol{F}}_{\boldsymbol{B}}$ are forcing terms that permit statistically stationary states to be obtained. In the Lagrangian frame, the spatial derivative terms in (2.1) and (2.2) are unknown, therefore these terms must be modelled in terms of functionals of the associated quantity, e.g.
$\boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}, {\boldsymbol{F}}_{\boldsymbol{B}}$ are forcing terms that permit statistically stationary states to be obtained. In the Lagrangian frame, the spatial derivative terms in (2.1) and (2.2) are unknown, therefore these terms must be modelled in terms of functionals of the associated quantity, e.g.  $\nu \,\nabla ^2\boldsymbol{\mathsf{A}}$ must be modelled as some functional of
$\nu \,\nabla ^2\boldsymbol{\mathsf{A}}$ must be modelled as some functional of  $\boldsymbol{\mathsf{A}}$.
$\boldsymbol{\mathsf{A}}$.
Concerning (2.1), various closure approaches have been developed, including the recent fluid deformation approximation (RFDA) (Chevillard & Meneveau Reference Chevillard and Meneveau2006), the random Gaussian fields closure (RGFC) model (Wilczek & Meneveau Reference Wilczek and Meneveau2014), and the recent deformation of Gaussian fields (RDGF) closure model (Johnson & Meneveau Reference Johnson and Meneveau2016). More recently, a multi-level version of the RDGF model has emerged (referred to as ML-RDGF) that provides a model for  $D_t\boldsymbol{\mathsf{A}}$ that is valid for arbitrary Reynolds numbers. These closures for (2.1) all lead to a model for
$D_t\boldsymbol{\mathsf{A}}$ that is valid for arbitrary Reynolds numbers. These closures for (2.1) all lead to a model for  $\boldsymbol{\mathsf{A}}$ that can generate steady-state statistics. This is in contrast to the restricted Euler (RE) model (Vieillefosse Reference Vieillefosse1982; Meneveau Reference Meneveau2011) that ignores the anisotropic contribution to
$\boldsymbol{\mathsf{A}}$ that can generate steady-state statistics. This is in contrast to the restricted Euler (RE) model (Vieillefosse Reference Vieillefosse1982; Meneveau Reference Meneveau2011) that ignores the anisotropic contribution to  $\boldsymbol{\mathsf{H}}$ and sets
$\boldsymbol{\mathsf{H}}$ and sets  $\nu =0$, leading to a model for
$\nu =0$, leading to a model for  $\boldsymbol{\mathsf{A}}$ that exhibits a finite-time singularity. Subsequent studies found that the addition of viscous effects to the RE model is not sufficient to prevent a finite-time singularity; the anisotropic pressure Hessian must also be accounted for. This could point to a potential challenge in closing (2.2); if the closure approximation for
$\boldsymbol{\mathsf{A}}$ that exhibits a finite-time singularity. Subsequent studies found that the addition of viscous effects to the RE model is not sufficient to prevent a finite-time singularity; the anisotropic pressure Hessian must also be accounted for. This could point to a potential challenge in closing (2.2); if the closure approximation for  $\kappa \,\nabla ^2\boldsymbol{B}$ is not sufficiently accurate, then the predictions from the resulting model could also generate finite-time singular solutions for
$\kappa \,\nabla ^2\boldsymbol{B}$ is not sufficiently accurate, then the predictions from the resulting model could also generate finite-time singular solutions for  $\boldsymbol{B}$ since the equation for
$\boldsymbol{B}$ since the equation for  $\boldsymbol{B}$ contains no pressure Hessian to regulate the amplification term
$\boldsymbol{B}$ contains no pressure Hessian to regulate the amplification term  $\boldsymbol{B}\boldsymbol {\cdot }\boldsymbol{\mathsf{A}}$ that causes the scalar gradient magnitude
$\boldsymbol{B}\boldsymbol {\cdot }\boldsymbol{\mathsf{A}}$ that causes the scalar gradient magnitude  $\|\boldsymbol{B}\|$ to grow when
$\|\boldsymbol{B}\|$ to grow when  $\boldsymbol{B}\boldsymbol {\cdot }(\boldsymbol{B}\boldsymbol {\cdot } \boldsymbol{\mathsf{A}})<0$. In this sense, developing a suitable closure for (2.2) may be more challenging than that for (2.1).
$\boldsymbol{B}\boldsymbol {\cdot }(\boldsymbol{B}\boldsymbol {\cdot } \boldsymbol{\mathsf{A}})<0$. In this sense, developing a suitable closure for (2.2) may be more challenging than that for (2.1).
The RGFC model (and also the RDGF and ML-RDGF models, since they are extensions of the RGFC model) does not approximate directly the unclosed terms in (2.1) (unlike the RFDA model) but instead closes the equation for  $d_t\boldsymbol {\mathcal {A}}$, which is defined as
$d_t\boldsymbol {\mathcal {A}}$, which is defined as  $D_t\boldsymbol{\mathsf{A}}$ averaged over the subset of fluid particles that experience the same value of
$D_t\boldsymbol{\mathsf{A}}$ averaged over the subset of fluid particles that experience the same value of  $\boldsymbol{\mathsf{A}}$. The probability density function (p.d.f.) of
$\boldsymbol{\mathsf{A}}$. The probability density function (p.d.f.) of  $\boldsymbol {\mathcal {A}}$ corresponds to the p.d.f. of
$\boldsymbol {\mathcal {A}}$ corresponds to the p.d.f. of  $\boldsymbol{\mathsf{A}}$; however, the advantage is that the terms requiring closure in the equation for
$\boldsymbol{\mathsf{A}}$; however, the advantage is that the terms requiring closure in the equation for  $d_t\boldsymbol {\mathcal {A}}$ are conditionally averaged quantities, therefore statistical approaches based on the properties of random Gaussian fields may be employed to close the terms in the equation. Such a procedure cannot be done when directly closing the terms in (2.1) since these involve instantaneous quantities.
$d_t\boldsymbol {\mathcal {A}}$ are conditionally averaged quantities, therefore statistical approaches based on the properties of random Gaussian fields may be employed to close the terms in the equation. Such a procedure cannot be done when directly closing the terms in (2.1) since these involve instantaneous quantities.
Mathematically, this procedure may be formalized as follows. Suppose that  $\boldsymbol{\mathsf{A}}$ evolves in a phase-space with time-independent coordinates
$\boldsymbol{\mathsf{A}}$ evolves in a phase-space with time-independent coordinates  $\boldsymbol{\mathsf{a}}\in \mathbb {R}^{3\times 3}$, and consider an infinite ensemble of realizations of
$\boldsymbol{\mathsf{a}}\in \mathbb {R}^{3\times 3}$, and consider an infinite ensemble of realizations of  $\boldsymbol{\mathsf{A}}$, each of which is governed by (2.1) but corresponds to a different initial condition
$\boldsymbol{\mathsf{A}}$, each of which is governed by (2.1) but corresponds to a different initial condition  $\boldsymbol{\mathsf{A}}_0$. By averaging over the ensemble, we can construct the p.d.f. of
$\boldsymbol{\mathsf{A}}_0$. By averaging over the ensemble, we can construct the p.d.f. of  $\boldsymbol{\mathsf{A}}$ as
$\boldsymbol{\mathsf{A}}$ as  $\mathcal {P}(\boldsymbol{\mathsf{a}},t)\equiv \langle \delta (\boldsymbol{\mathsf{A}}-\boldsymbol{\mathsf{a}})\rangle$, which solves the Liouville equation
$\mathcal {P}(\boldsymbol{\mathsf{a}},t)\equiv \langle \delta (\boldsymbol{\mathsf{A}}-\boldsymbol{\mathsf{a}})\rangle$, which solves the Liouville equation
 \begin{equation} \partial_t\mathcal{P}={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot} (\mathcal{P}\left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} ),\end{equation}
\begin{equation} \partial_t\mathcal{P}={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot} (\mathcal{P}\left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} ),\end{equation}
where  $\langle {\cdot }\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ denotes an ensemble average conditioned on
$\langle {\cdot }\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ denotes an ensemble average conditioned on  $\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}$. We now introduce the time-dependent characteristic variable
$\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}$. We now introduce the time-dependent characteristic variable  $\boldsymbol {\mathcal {A}}$ defined via
$\boldsymbol {\mathcal {A}}$ defined via
 \begin{equation} d_t\boldsymbol{\mathcal{A}}\equiv\boldsymbol{\mathsf{G}}(\boldsymbol{\mathcal{A}},t), \end{equation}
\begin{equation} d_t\boldsymbol{\mathcal{A}}\equiv\boldsymbol{\mathsf{G}}(\boldsymbol{\mathcal{A}},t), \end{equation}
in which  $\boldsymbol{\mathsf{G}}$ is defined by
$\boldsymbol{\mathsf{G}}$ is defined by
 \begin{equation} \boldsymbol{\mathsf{G}}(\boldsymbol{\mathsf{a}},t)\equiv\left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}; \end{equation}
\begin{equation} \boldsymbol{\mathsf{G}}(\boldsymbol{\mathsf{a}},t)\equiv\left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}; \end{equation}
whereas  $\boldsymbol{\mathsf{A}}$ evolves according to the instantaneous Navier–Stokes equation,
$\boldsymbol{\mathsf{A}}$ evolves according to the instantaneous Navier–Stokes equation,  $\boldsymbol {\mathcal {A}}$ evolves according to the conditionally averaged Navier–Stokes equation. Nevertheless, since
$\boldsymbol {\mathcal {A}}$ evolves according to the conditionally averaged Navier–Stokes equation. Nevertheless, since  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ involves only a partial average over the ensemble, the field
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ involves only a partial average over the ensemble, the field  $\boldsymbol{\mathsf{G}}$ will in general exhibit nonlinear dependence on
$\boldsymbol{\mathsf{G}}$ will in general exhibit nonlinear dependence on  $\boldsymbol{\mathsf{a}}$ and
$\boldsymbol{\mathsf{a}}$ and  $t$, hence the trajectories
$t$, hence the trajectories  $\boldsymbol {\mathcal {A}}$ generated by (2.4) will still vary chaotically in time for a turbulent flow.
$\boldsymbol {\mathcal {A}}$ generated by (2.4) will still vary chaotically in time for a turbulent flow.
We may then define the p.d.f.  $\varrho (\boldsymbol{\mathsf{a}},t)\equiv \langle \delta (\boldsymbol {\mathcal {A}}-\boldsymbol{\mathsf{a}})\rangle$ that solves
$\varrho (\boldsymbol{\mathsf{a}},t)\equiv \langle \delta (\boldsymbol {\mathcal {A}}-\boldsymbol{\mathsf{a}})\rangle$ that solves
 \begin{equation} \partial_t\varrho={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\varrho \left\langle d_t\boldsymbol{\mathcal{A}}\right\rangle_{\boldsymbol{\mathcal{A}}=\boldsymbol{\mathsf{a}}}).\end{equation}
\begin{equation} \partial_t\varrho={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\varrho \left\langle d_t\boldsymbol{\mathcal{A}}\right\rangle_{\boldsymbol{\mathcal{A}}=\boldsymbol{\mathsf{a}}}).\end{equation}From the definition of the characteristic variable, we have
 \begin{equation} \left\langle d_t\boldsymbol{\mathcal{A}}\right\rangle_{\boldsymbol{\mathcal{A}}=\boldsymbol{\mathsf{a}}}=\left\langle \boldsymbol{\mathsf{G}}(\boldsymbol{\mathcal{A}},t)\right\rangle_{\boldsymbol{\mathcal{A}}=\boldsymbol{\mathsf{a}}}=\boldsymbol{\mathsf{G}}(\boldsymbol{\mathsf{a}},t)= \left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}, \end{equation}
\begin{equation} \left\langle d_t\boldsymbol{\mathcal{A}}\right\rangle_{\boldsymbol{\mathcal{A}}=\boldsymbol{\mathsf{a}}}=\left\langle \boldsymbol{\mathsf{G}}(\boldsymbol{\mathcal{A}},t)\right\rangle_{\boldsymbol{\mathcal{A}}=\boldsymbol{\mathsf{a}}}=\boldsymbol{\mathsf{G}}(\boldsymbol{\mathsf{a}},t)= \left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}, \end{equation}
where the second equality follows since  $\boldsymbol{\mathsf{G}}(\boldsymbol{\mathsf{a}},t)$ is not random. In view of this, the operators of (2.3) and (2.6) are the same, such that if
$\boldsymbol{\mathsf{G}}(\boldsymbol{\mathsf{a}},t)$ is not random. In view of this, the operators of (2.3) and (2.6) are the same, such that if  $\varrho (\boldsymbol{\mathsf{a}},0)=\mathcal {P}(\boldsymbol{\mathsf{a}},0)$, then it follows that
$\varrho (\boldsymbol{\mathsf{a}},0)=\mathcal {P}(\boldsymbol{\mathsf{a}},0)$, then it follows that  $\varrho (\boldsymbol{\mathsf{a}},t)=\mathcal {P}(\boldsymbol{\mathsf{a}},t)$ for all
$\varrho (\boldsymbol{\mathsf{a}},t)=\mathcal {P}(\boldsymbol{\mathsf{a}},t)$ for all  $t$, hence the p.d.f. of
$t$, hence the p.d.f. of  $\boldsymbol{\mathsf{A}}$ may be generated via solutions to either (2.1) or (2.4).
$\boldsymbol{\mathsf{A}}$ may be generated via solutions to either (2.1) or (2.4).
Based on the definitions above, we have
 \begin{equation} d_t\boldsymbol{\mathcal{A}}={-}\boldsymbol{\mathcal{A}}\boldsymbol{\cdot} \boldsymbol{\mathcal{A}}-\langle\boldsymbol{\mathsf{H}}\rangle_{\boldsymbol{\mathcal{A}}}+ \nu\,\langle\nabla^2\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathcal{A}}}+\langle \boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}\rangle_{\boldsymbol{\mathcal{A}}},\end{equation}
\begin{equation} d_t\boldsymbol{\mathcal{A}}={-}\boldsymbol{\mathcal{A}}\boldsymbol{\cdot} \boldsymbol{\mathcal{A}}-\langle\boldsymbol{\mathsf{H}}\rangle_{\boldsymbol{\mathcal{A}}}+ \nu\,\langle\nabla^2\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathcal{A}}}+\langle \boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}\rangle_{\boldsymbol{\mathcal{A}}},\end{equation}where we have used the short-hand notation
 \begin{equation} \langle{\cdot}\rangle_{\boldsymbol{\mathcal{A}}}\equiv\langle{\cdot}\rangle_{\boldsymbol{\mathsf{A}}= \boldsymbol{\mathcal{A}}}. \end{equation}
\begin{equation} \langle{\cdot}\rangle_{\boldsymbol{\mathcal{A}}}\equiv\langle{\cdot}\rangle_{\boldsymbol{\mathsf{A}}= \boldsymbol{\mathcal{A}}}. \end{equation}
While closing the equation for  $D_t\boldsymbol{\mathsf{A}}$ requires approximating instantaneous quantities, closing
$D_t\boldsymbol{\mathsf{A}}$ requires approximating instantaneous quantities, closing  $d_t\boldsymbol {\mathcal {A}}$ requires approximating conditionally averaged quantities. This is a major advantage since it means that powerful statistical approaches can be used to develop systematic closures for
$d_t\boldsymbol {\mathcal {A}}$ requires approximating conditionally averaged quantities. This is a major advantage since it means that powerful statistical approaches can be used to develop systematic closures for  $d_t\boldsymbol {\mathcal {A}}$. This then is the approach adopted in the RGFC and RDGF models, where
$d_t\boldsymbol {\mathcal {A}}$. This then is the approach adopted in the RGFC and RDGF models, where  $\langle \boldsymbol{\mathsf{H}}\rangle _{\boldsymbol {\mathcal {A}}}$ and
$\langle \boldsymbol{\mathsf{H}}\rangle _{\boldsymbol {\mathcal {A}}}$ and  $\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ are closed under the approximation that the velocity field
$\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ are closed under the approximation that the velocity field  $\boldsymbol {u}$ has Gaussian statistics.
$\boldsymbol {u}$ has Gaussian statistics.
A point worth emphasizing is that constructing the p.d.f. of  $\boldsymbol{\mathsf{A}}$ using
$\boldsymbol{\mathsf{A}}$ using  $d_t\boldsymbol {\mathcal {A}}$ instead of
$d_t\boldsymbol {\mathcal {A}}$ instead of  $D_t\boldsymbol{\mathsf{A}}$ does not require the assumption that the contribution from the fluctuations
$D_t\boldsymbol{\mathsf{A}}$ does not require the assumption that the contribution from the fluctuations  $D_t\boldsymbol{\mathsf{A}}'\equiv D_t\boldsymbol{\mathsf{A}}-\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ are negligible. As proven above, the p.d.f. of
$D_t\boldsymbol{\mathsf{A}}'\equiv D_t\boldsymbol{\mathsf{A}}-\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ are negligible. As proven above, the p.d.f. of  $\boldsymbol{\mathsf{A}}$ may be constructed exactly using either
$\boldsymbol{\mathsf{A}}$ may be constructed exactly using either  $d_t\boldsymbol {\mathcal {A}}$ or
$d_t\boldsymbol {\mathcal {A}}$ or  $D_t\boldsymbol{\mathsf{A}}$ This subtle point is discussed in detail in Appendix A. Another important point is that while this proof relates to the p.d.f. of
$D_t\boldsymbol{\mathsf{A}}$ This subtle point is discussed in detail in Appendix A. Another important point is that while this proof relates to the p.d.f. of  $\boldsymbol{\mathsf{A}}$, since the p.d.f. of any well-behaved function of
$\boldsymbol{\mathsf{A}}$, since the p.d.f. of any well-behaved function of  $\boldsymbol{\mathsf{A}}$ may be transformed into the p.d.f. of
$\boldsymbol{\mathsf{A}}$ may be transformed into the p.d.f. of  $\boldsymbol{\mathsf{A}}$ using a change of variables, it also follows that
$\boldsymbol{\mathsf{A}}$ using a change of variables, it also follows that  $d_t\boldsymbol {\mathcal {A}}$ can be used to construct exactly not only the p.d.f. of
$d_t\boldsymbol {\mathcal {A}}$ can be used to construct exactly not only the p.d.f. of  $\boldsymbol{\mathsf{A}}$, but also the p.d.f. of any well-behaved function of
$\boldsymbol{\mathsf{A}}$, but also the p.d.f. of any well-behaved function of  $\boldsymbol{\mathsf{A}}$. The argument does not extend, however, to p.d.f.s involving multi-time information, e.g. the joint p.d.f. of
$\boldsymbol{\mathsf{A}}$. The argument does not extend, however, to p.d.f.s involving multi-time information, e.g. the joint p.d.f. of  $\boldsymbol{\mathsf{A}}(t)$ and
$\boldsymbol{\mathsf{A}}(t)$ and  $\boldsymbol{\mathsf{A}}(t')$ with
$\boldsymbol{\mathsf{A}}(t')$ with  $t'\neq t$ does depend on the contribution from the fluctuations
$t'\neq t$ does depend on the contribution from the fluctuations  $D_t\boldsymbol{\mathsf{A}}'\equiv D_t\boldsymbol{\mathsf{A}}-\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$.
$D_t\boldsymbol{\mathsf{A}}'\equiv D_t\boldsymbol{\mathsf{A}}-\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$.
An approach similar to this may be adopted for (2.2), but now the averaging must be conditional on both  $\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}$ and
$\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}$ and  $\boldsymbol{B}=\boldsymbol {b}$, where
$\boldsymbol{B}=\boldsymbol {b}$, where  $(\boldsymbol{\mathsf{a}},\boldsymbol {b})\in (\mathbb {R}^{3\times 3},\mathbb {R}^3)$ are the time-independent coordinates of the phase-space in which
$(\boldsymbol{\mathsf{a}},\boldsymbol {b})\in (\mathbb {R}^{3\times 3},\mathbb {R}^3)$ are the time-independent coordinates of the phase-space in which  $\boldsymbol{\mathsf{A}}$ and
$\boldsymbol{\mathsf{A}}$ and  $\boldsymbol{B}$ evolve. We define
$\boldsymbol{B}$ evolve. We define
 $$\begin{gather} d_t\boldsymbol{\mathcal{A}}\equiv\boldsymbol{\mathsf{J}}(\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}},t), \end{gather}$$
$$\begin{gather} d_t\boldsymbol{\mathcal{A}}\equiv\boldsymbol{\mathsf{J}}(\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}},t), \end{gather}$$ $$\begin{gather}d_t\boldsymbol{\mathcal{B}}\equiv\boldsymbol{K}(\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}},t), \end{gather}$$
$$\begin{gather}d_t\boldsymbol{\mathcal{B}}\equiv\boldsymbol{K}(\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}},t), \end{gather}$$ $$\begin{gather}\boldsymbol{\mathsf{J}}(\boldsymbol{\mathsf{a}},\boldsymbol{b},t)\equiv\left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol{b}}, \end{gather}$$
$$\begin{gather}\boldsymbol{\mathsf{J}}(\boldsymbol{\mathsf{a}},\boldsymbol{b},t)\equiv\left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol{b}}, \end{gather}$$ $$\begin{gather}\boldsymbol{K}(\boldsymbol{\mathsf{a}},\boldsymbol{b},t)\equiv\left\langle D_t\boldsymbol{B}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol{b}}, \end{gather}$$
$$\begin{gather}\boldsymbol{K}(\boldsymbol{\mathsf{a}},\boldsymbol{b},t)\equiv\left\langle D_t\boldsymbol{B}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol{b}}, \end{gather}$$and then based on (2.2), this leads to
 $$\begin{gather} d_t\boldsymbol{\mathcal{B}}={-}\boldsymbol{\mathcal{A}}^{\rm T} \boldsymbol{\cdot}\boldsymbol{\mathcal{B}}+\kappa\,\langle\nabla^2\boldsymbol{B}\rangle_{ \boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}}+\langle \boldsymbol{F}_{\boldsymbol{B}} \rangle_{\boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}}, \end{gather}$$
$$\begin{gather} d_t\boldsymbol{\mathcal{B}}={-}\boldsymbol{\mathcal{A}}^{\rm T} \boldsymbol{\cdot}\boldsymbol{\mathcal{B}}+\kappa\,\langle\nabla^2\boldsymbol{B}\rangle_{ \boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}}+\langle \boldsymbol{F}_{\boldsymbol{B}} \rangle_{\boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}}, \end{gather}$$ $$\begin{gather}\langle{\cdot}\rangle_{\boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}} \equiv\langle{\cdot}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathcal{A}},\boldsymbol{B}=\boldsymbol{\mathcal{B}}}. \end{gather}$$
$$\begin{gather}\langle{\cdot}\rangle_{\boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}} \equiv\langle{\cdot}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathcal{A}},\boldsymbol{B}=\boldsymbol{\mathcal{B}}}. \end{gather}$$
An approach based on the RGFC or RDGF model may then be used to close the term  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ under the assumption that the scalar field
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ under the assumption that the scalar field  $\phi$ has Gaussian statistics. Just as the solutions to (2.4) can be used to construct the p.d.f. of
$\phi$ has Gaussian statistics. Just as the solutions to (2.4) can be used to construct the p.d.f. of  $\boldsymbol{\mathsf{A}}$, so also can the solutions to (2.11) be used to construct the p.d.f. of
$\boldsymbol{\mathsf{A}}$, so also can the solutions to (2.11) be used to construct the p.d.f. of  $\boldsymbol{B}$.
$\boldsymbol{B}$.
A subtle point concerns the difference between (2.4) and (2.10), with the former defined in terms of  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$, while the latter is defined in terms of
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$, while the latter is defined in terms of  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}$. It might be thought that since for constant density flows
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}$. It might be thought that since for constant density flows  $D_t\boldsymbol{\mathsf{A}}$ does not explicitly depend on
$D_t\boldsymbol{\mathsf{A}}$ does not explicitly depend on  $\boldsymbol{B}$ (see (2.1)), we should have
$\boldsymbol{B}$ (see (2.1)), we should have  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. However, this is not the case because
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. However, this is not the case because  $\boldsymbol{B}$ is a functional of
$\boldsymbol{B}$ is a functional of  $\boldsymbol{\mathsf{A}}$. In particular, by definition we can write
$\boldsymbol{\mathsf{A}}$. In particular, by definition we can write
 \begin{equation} \left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}= \boldsymbol{b}}=\frac{1}{\langle\delta(\boldsymbol{B}-\boldsymbol{b})\rangle}\left\langle \delta(\boldsymbol{B}-\boldsymbol{b}) D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}. \end{equation}
\begin{equation} \left\langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}= \boldsymbol{b}}=\frac{1}{\langle\delta(\boldsymbol{B}-\boldsymbol{b})\rangle}\left\langle \delta(\boldsymbol{B}-\boldsymbol{b}) D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}. \end{equation}
If  $\boldsymbol{B}$ were uncorrelated with
$\boldsymbol{B}$ were uncorrelated with  $\boldsymbol{\mathsf{A}}$, then we could write
$\boldsymbol{\mathsf{A}}$, then we could write
 \begin{equation} \left\langle \delta(\boldsymbol{B}-\boldsymbol{b}) D_t\boldsymbol{\mathsf{A}}\right \rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}=\left\langle \delta(\boldsymbol{B}-\boldsymbol{b})\right\rangle\left \langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}, \end{equation}
\begin{equation} \left\langle \delta(\boldsymbol{B}-\boldsymbol{b}) D_t\boldsymbol{\mathsf{A}}\right \rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}=\left\langle \delta(\boldsymbol{B}-\boldsymbol{b})\right\rangle\left \langle D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}, \end{equation}
leading to  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. However,
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. However,  $\boldsymbol{B}$ is not uncorrelated with
$\boldsymbol{B}$ is not uncorrelated with  $\boldsymbol{\mathsf{A}}$ in view of the fact that the equation governing
$\boldsymbol{\mathsf{A}}$ in view of the fact that the equation governing  $D_t\boldsymbol{B}$ involves
$D_t\boldsymbol{B}$ involves  $\boldsymbol{\mathsf{A}}$ through the amplification term
$\boldsymbol{\mathsf{A}}$ through the amplification term  $\boldsymbol{\mathsf{A}}^{\rm T}\boldsymbol {\cdot } \boldsymbol{B}$.
$\boldsymbol{\mathsf{A}}^{\rm T}\boldsymbol {\cdot } \boldsymbol{B}$.
Notwithstanding this point of rigour, in our model we will use the existing ML-RDGF model to specify  $d_t\boldsymbol {\mathcal {A}}$, which in the present context means that we are implicitly invoking the approximation
$d_t\boldsymbol {\mathcal {A}}$, which in the present context means that we are implicitly invoking the approximation  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}\approx \langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. While this is not justified formally, it is adopted for simplicity because while ML-RDGF could in principle be used to construct a model for
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}\approx \langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. While this is not justified formally, it is adopted for simplicity because while ML-RDGF could in principle be used to construct a model for  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}$, its derivation would be extremely complicated, far more so than the derivation of the ML-RDGF model for
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\boldsymbol{B}=\boldsymbol {b}}$, its derivation would be extremely complicated, far more so than the derivation of the ML-RDGF model for  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$, which is already very involved.
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$, which is already very involved.
2.2. Model for the velocity gradients
In our model for  $\boldsymbol {\mathcal {B}}$, the ML-RDGF model will be used to prescribe
$\boldsymbol {\mathcal {B}}$, the ML-RDGF model will be used to prescribe  $\boldsymbol {\mathcal {A}}$, and since our model for
$\boldsymbol {\mathcal {A}}$, and since our model for  $\boldsymbol {\mathcal {B}}$ will be based on the RDGF approach, we summarize the key ideas in this modelling approach before applying them to deriving a closed equation for
$\boldsymbol {\mathcal {B}}$ will be based on the RDGF approach, we summarize the key ideas in this modelling approach before applying them to deriving a closed equation for  $d_t\boldsymbol {\mathcal {B}}$.
$d_t\boldsymbol {\mathcal {B}}$.
2.2.1. The RDGF closure
The deformation tensor  $\boldsymbol{\mathsf{D}}(t,s)$ for a fluid particle with position
$\boldsymbol{\mathsf{D}}(t,s)$ for a fluid particle with position  $\boldsymbol {x}^f(t\vert \boldsymbol {X},s)$ that satisfies
$\boldsymbol {x}^f(t\vert \boldsymbol {X},s)$ that satisfies  $\boldsymbol {x}^f(s\vert \boldsymbol {X},s)=\boldsymbol {X}$ is defined as
$\boldsymbol {x}^f(s\vert \boldsymbol {X},s)=\boldsymbol {X}$ is defined as
 \begin{equation} \boldsymbol{\mathsf{D}}(t,s)\equiv\frac{\partial}{\partial\boldsymbol{X}}\boldsymbol{x}^f(t\vert\boldsymbol{X},s),\quad s\in[0,t], \end{equation}
\begin{equation} \boldsymbol{\mathsf{D}}(t,s)\equiv\frac{\partial}{\partial\boldsymbol{X}}\boldsymbol{x}^f(t\vert\boldsymbol{X},s),\quad s\in[0,t], \end{equation}and evolves according to
 \begin{equation} \partial_t\boldsymbol{\mathsf{D}}=\boldsymbol{\mathsf{A}}\boldsymbol{\cdot} \boldsymbol{\mathsf{D}},\quad \boldsymbol{\mathsf{D}}(0,0)=\boldsymbol{\mathsf{I}}, \end{equation}
\begin{equation} \partial_t\boldsymbol{\mathsf{D}}=\boldsymbol{\mathsf{A}}\boldsymbol{\cdot} \boldsymbol{\mathsf{D}},\quad \boldsymbol{\mathsf{D}}(0,0)=\boldsymbol{\mathsf{I}}, \end{equation}
where  $\boldsymbol{\mathsf{I}}$ is the identity matrix. While the solution to this is given by a time-ordered exponential, the RFDA approximates the solution by assuming that
$\boldsymbol{\mathsf{I}}$ is the identity matrix. While the solution to this is given by a time-ordered exponential, the RFDA approximates the solution by assuming that  $\boldsymbol{\mathsf{A}}$ is constant over a recent deformation time scale
$\boldsymbol{\mathsf{A}}$ is constant over a recent deformation time scale  $\tau$, with the deformation at times
$\tau$, with the deformation at times  $s< t-\tau$ ignored. In this case, the approximate solution is
$s< t-\tau$ ignored. In this case, the approximate solution is
 \begin{equation} \boldsymbol{\mathsf{D}}(t,s)\approx \exp\left((t-s)\boldsymbol{\mathsf{A}} \right),\quad t-s\in[0,\tau].\end{equation}
\begin{equation} \boldsymbol{\mathsf{D}}(t,s)\approx \exp\left((t-s)\boldsymbol{\mathsf{A}} \right),\quad t-s\in[0,\tau].\end{equation}
The idea then is as follows. The quantities  $\boldsymbol{\mathsf{H}}\equiv \boldsymbol {\nabla }\boldsymbol {\nabla }p$ and
$\boldsymbol{\mathsf{H}}\equiv \boldsymbol {\nabla }\boldsymbol {\nabla }p$ and  $\nabla ^2\boldsymbol{\mathsf{A}}$ are evaluated along the fluid particle trajectory
$\nabla ^2\boldsymbol{\mathsf{A}}$ are evaluated along the fluid particle trajectory  $\boldsymbol {x}^f(t\vert \boldsymbol {X},s)$, and they may be related to their corresponding values at the reference configuration
$\boldsymbol {x}^f(t\vert \boldsymbol {X},s)$, and they may be related to their corresponding values at the reference configuration  $\boldsymbol {x}^f(s\vert \boldsymbol {X},s)=\boldsymbol {X}$ using
$\boldsymbol {x}^f(s\vert \boldsymbol {X},s)=\boldsymbol {X}$ using  $\boldsymbol{\mathsf{D}}$. Using the approximate solution for
$\boldsymbol{\mathsf{D}}$. Using the approximate solution for  $\boldsymbol{\mathsf{D}}$ in (2.20) and setting
$\boldsymbol{\mathsf{D}}$ in (2.20) and setting  $s=t-\tau$ leads to
$s=t-\tau$ leads to
 $$\begin{gather} \langle\boldsymbol{\mathsf{H}}\rangle_{\boldsymbol{\mathcal{A}}}\approx \left\langle\boldsymbol{\mathsf{D}}^{-{\rm T}}\boldsymbol{\cdot}\left(\frac{\partial^2}{\partial\boldsymbol{X}\, \partial\boldsymbol{X}}\,{p}\right)\boldsymbol{\cdot}\boldsymbol{\mathsf{D}}^{{-}1}\right\rangle_{ \boldsymbol{\mathcal{A}}}=\boldsymbol{\mathcal{D}}^{-{\rm T}}\boldsymbol{\cdot} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{p}\right\rangle_{ \boldsymbol{\mathcal{A}}}\boldsymbol{\cdot}\boldsymbol{\mathcal{D}}^{{-}1}, \end{gather}$$
$$\begin{gather} \langle\boldsymbol{\mathsf{H}}\rangle_{\boldsymbol{\mathcal{A}}}\approx \left\langle\boldsymbol{\mathsf{D}}^{-{\rm T}}\boldsymbol{\cdot}\left(\frac{\partial^2}{\partial\boldsymbol{X}\, \partial\boldsymbol{X}}\,{p}\right)\boldsymbol{\cdot}\boldsymbol{\mathsf{D}}^{{-}1}\right\rangle_{ \boldsymbol{\mathcal{A}}}=\boldsymbol{\mathcal{D}}^{-{\rm T}}\boldsymbol{\cdot} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{p}\right\rangle_{ \boldsymbol{\mathcal{A}}}\boldsymbol{\cdot}\boldsymbol{\mathcal{D}}^{{-}1}, \end{gather}$$ $$\begin{gather}\langle\nabla^2\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathcal{A}}}\approx \left\langle\boldsymbol{\mathsf{D}}^{-{\rm T}}\boldsymbol{\cdot}\left(\frac{\partial^2}{\partial\boldsymbol{X}\, \partial\boldsymbol{X}}\,{\boldsymbol{\mathsf{A}}}\right)\boldsymbol{\cdot}\boldsymbol{\mathsf{D}}^{{-}1}\right\rangle_{ \boldsymbol{\mathcal{A}}}=\boldsymbol{\mathcal{D}}^{-{\rm T}}\boldsymbol{\cdot} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{\mathsf{A}}} \right\rangle_{\boldsymbol{\mathcal{A}}}\boldsymbol{\cdot}\boldsymbol{\mathcal{D}}^{{-}1}, \end{gather}$$
$$\begin{gather}\langle\nabla^2\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathcal{A}}}\approx \left\langle\boldsymbol{\mathsf{D}}^{-{\rm T}}\boldsymbol{\cdot}\left(\frac{\partial^2}{\partial\boldsymbol{X}\, \partial\boldsymbol{X}}\,{\boldsymbol{\mathsf{A}}}\right)\boldsymbol{\cdot}\boldsymbol{\mathsf{D}}^{{-}1}\right\rangle_{ \boldsymbol{\mathcal{A}}}=\boldsymbol{\mathcal{D}}^{-{\rm T}}\boldsymbol{\cdot} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{\mathsf{A}}} \right\rangle_{\boldsymbol{\mathcal{A}}}\boldsymbol{\cdot}\boldsymbol{\mathcal{D}}^{{-}1}, \end{gather}$$
where  $\boldsymbol {\mathcal {D}}= \exp (\tau \boldsymbol {\mathcal {A}})$, and
$\boldsymbol {\mathcal {D}}= \exp (\tau \boldsymbol {\mathcal {A}})$, and  $({\cdot })^{-{\rm T}}$ denotes the transpose of the inverse of a tensor. The RDGF model then uses the RGFC approach (Wilczek & Meneveau Reference Wilczek and Meneveau2014) to approximate the conditional averages in (2.21) and (2.22).
$({\cdot })^{-{\rm T}}$ denotes the transpose of the inverse of a tensor. The RDGF model then uses the RGFC approach (Wilczek & Meneveau Reference Wilczek and Meneveau2014) to approximate the conditional averages in (2.21) and (2.22).
The basic motivation for the RDGF model is that the closure approximations for  $\langle \boldsymbol{\mathsf{H}}\rangle _{\boldsymbol {\mathcal {A}}}$ and
$\langle \boldsymbol{\mathsf{H}}\rangle _{\boldsymbol {\mathcal {A}}}$ and  $\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ can be improved by applying the RGFC at
$\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ can be improved by applying the RGFC at  $\boldsymbol {X},t-\tau$ rather than
$\boldsymbol {X},t-\tau$ rather than  $\boldsymbol {x},t$. This is because when the RGFC is applied at
$\boldsymbol {x},t$. This is because when the RGFC is applied at  $\boldsymbol {X},t-\tau$, it is then transformed under the flow map into something more realistic. For example, while the conditional averages in (2.21) and (2.22) are approximated assuming that
$\boldsymbol {X},t-\tau$, it is then transformed under the flow map into something more realistic. For example, while the conditional averages in (2.21) and (2.22) are approximated assuming that  $\boldsymbol {u}$ has Gaussian statistics, due to the Lagrangian transformation described by
$\boldsymbol {u}$ has Gaussian statistics, due to the Lagrangian transformation described by  $\boldsymbol {\mathcal {D}}$, the resulting approximations for
$\boldsymbol {\mathcal {D}}$, the resulting approximations for  $\langle \boldsymbol{\mathsf{H}}\rangle _{\boldsymbol {\mathcal {A}}}$ and
$\langle \boldsymbol{\mathsf{H}}\rangle _{\boldsymbol {\mathcal {A}}}$ and  $\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ obtained through (2.21) and (2.22) will, in general, correspond to those for a non-Gaussian field
$\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ obtained through (2.21) and (2.22) will, in general, correspond to those for a non-Gaussian field  $\boldsymbol {u}$.
$\boldsymbol {u}$.
The final closed equation obtained using the RDGF closure has the form (Johnson & Meneveau Reference Johnson and Meneveau2016)
 \begin{equation} {\rm d}\boldsymbol{\mathcal{A}}=\boldsymbol{\mathcal{N}}_{\mathcal{A}}\{\boldsymbol{\mathcal{A}},\tau,\tau_\eta\} \,{\rm d}t+\boldsymbol{\varSigma}\boldsymbol{\cdot}{\rm d}\boldsymbol{\mathcal{W}},\end{equation}
\begin{equation} {\rm d}\boldsymbol{\mathcal{A}}=\boldsymbol{\mathcal{N}}_{\mathcal{A}}\{\boldsymbol{\mathcal{A}},\tau,\tau_\eta\} \,{\rm d}t+\boldsymbol{\varSigma}\boldsymbol{\cdot}{\rm d}\boldsymbol{\mathcal{W}},\end{equation}
where the forcing term has been chosen to be  $\langle \boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}\rangle _{\boldsymbol {\mathcal {A}}}\,{\rm d}t=\boldsymbol {\varSigma }\boldsymbol {\cdot } {\rm d}\boldsymbol {\mathcal {W}}$, with
$\langle \boldsymbol{\mathsf{F}}_{\boldsymbol{\mathsf{A}}}\rangle _{\boldsymbol {\mathcal {A}}}\,{\rm d}t=\boldsymbol {\varSigma }\boldsymbol {\cdot } {\rm d}\boldsymbol {\mathcal {W}}$, with  ${\rm d}\boldsymbol {\mathcal {W}}$ denoting a tensor-valued Wiener process, and
${\rm d}\boldsymbol {\mathcal {W}}$ denoting a tensor-valued Wiener process, and  $\boldsymbol {\varSigma }$ denoting a diffusion tensor (see Appendix B for details) that depends on the coefficients
$\boldsymbol {\varSigma }$ denoting a diffusion tensor (see Appendix B for details) that depends on the coefficients  $D_s$ and
$D_s$ and  $D_a$ that determine the growth rate of the mean square values of the strain rate
$D_a$ that determine the growth rate of the mean square values of the strain rate  $\boldsymbol {\mathcal {S}}\equiv (\boldsymbol {\mathcal {A}}+\boldsymbol {\mathcal {A}}^{\rm T})/2$ and rotation rate
$\boldsymbol {\mathcal {S}}\equiv (\boldsymbol {\mathcal {A}}+\boldsymbol {\mathcal {A}}^{\rm T})/2$ and rotation rate  $\boldsymbol {\mathcal {R}}\equiv (\boldsymbol {\mathcal {A}}-\boldsymbol {\mathcal {A}}^{\rm T})/2$ tensors. The term
$\boldsymbol {\mathcal {R}}\equiv (\boldsymbol {\mathcal {A}}-\boldsymbol {\mathcal {A}}^{\rm T})/2$ tensors. The term  $\boldsymbol {\mathcal {N}}_{\mathcal {A}}\{{\cdot } \}$ denotes the nonlinear operator whose exact form is given in Appendix B.
$\boldsymbol {\mathcal {N}}_{\mathcal {A}}\{{\cdot } \}$ denotes the nonlinear operator whose exact form is given in Appendix B.
The three unknown parameters  $\tau, D_a, D_s$ are obtained by an optimization procedure that seeks those values for which the model satisfies known constraints for isotropic turbulence, namely the relation between strain rate and energy dissipation for isotropic turbulence
$\tau, D_a, D_s$ are obtained by an optimization procedure that seeks those values for which the model satisfies known constraints for isotropic turbulence, namely the relation between strain rate and energy dissipation for isotropic turbulence  $2\langle \|\boldsymbol {\mathcal {S}}\|^2\rangle =1/\tau _\eta ^2$ (where
$2\langle \|\boldsymbol {\mathcal {S}}\|^2\rangle =1/\tau _\eta ^2$ (where  $\tau _\eta$ is the Kolmogorov time scale, and
$\tau _\eta$ is the Kolmogorov time scale, and  $\|\,{\cdot }\,\|$ denotes the Frobenius norm), and the only two homogeneity relations involving solely the velocity gradient (Betchov Reference Betchov1956; Carbone & Wilczek Reference Carbone and Wilczek2022),
$\|\,{\cdot }\,\|$ denotes the Frobenius norm), and the only two homogeneity relations involving solely the velocity gradient (Betchov Reference Betchov1956; Carbone & Wilczek Reference Carbone and Wilczek2022),  $\langle \boldsymbol {\mathcal {A}}\boldsymbol {:}\boldsymbol {\mathcal {A}}\rangle =0$ and
$\langle \boldsymbol {\mathcal {A}}\boldsymbol {:}\boldsymbol {\mathcal {A}}\rangle =0$ and  $\langle (\boldsymbol {\mathcal {A}}\boldsymbol {\cdot }\boldsymbol {\mathcal {A}})\boldsymbol {:}\boldsymbol {\mathcal {A}}\rangle =0$. The values obtained by this procedure are
$\langle (\boldsymbol {\mathcal {A}}\boldsymbol {\cdot }\boldsymbol {\mathcal {A}})\boldsymbol {:}\boldsymbol {\mathcal {A}}\rangle =0$. The values obtained by this procedure are  $\tau =0.1302\tau _\eta$,
$\tau =0.1302\tau _\eta$,  $D_s=0.1014/\tau _\eta ^3$ and
$D_s=0.1014/\tau _\eta ^3$ and  $D_a=0.0505/\tau _\eta ^3$.
$D_a=0.0505/\tau _\eta ^3$.
In Johnson & Meneveau (Reference Johnson and Meneveau2016), the authors interpret the random term  $\boldsymbol {\varSigma }\boldsymbol {\cdot }{\rm d}\boldsymbol {\mathcal {W}}$ as capturing not merely the effect of forcing on the velocity gradients (needed for the model to generate stationary statistics) but also the fluctuating pressure Hessian and viscous terms, since these terms are approximated in the model as Gaussian, white-noise processes. Approximating these fluctuating terms in this way would be highly questionable, and would suggest a significant point of weakness in the model. However, in Appendix A, we provide an alternative interpretation according to which the RDGF model (and therefore also the ML-RDGF model) does not involve approximating the fluctuating pressure Hessian and viscous terms as Gaussian, white-noise processes, and the term
$\boldsymbol {\varSigma }\boldsymbol {\cdot }{\rm d}\boldsymbol {\mathcal {W}}$ as capturing not merely the effect of forcing on the velocity gradients (needed for the model to generate stationary statistics) but also the fluctuating pressure Hessian and viscous terms, since these terms are approximated in the model as Gaussian, white-noise processes. Approximating these fluctuating terms in this way would be highly questionable, and would suggest a significant point of weakness in the model. However, in Appendix A, we provide an alternative interpretation according to which the RDGF model (and therefore also the ML-RDGF model) does not involve approximating the fluctuating pressure Hessian and viscous terms as Gaussian, white-noise processes, and the term  $\boldsymbol {\varSigma }\boldsymbol {\cdot }{\rm d}\boldsymbol {\mathcal {W}}$ only describes the effect of forcing on the flow.
$\boldsymbol {\varSigma }\boldsymbol {\cdot }{\rm d}\boldsymbol {\mathcal {W}}$ only describes the effect of forcing on the flow.
2.2.2. The ML-RDGF closure
The RDGF model described by (2.23) does not contain any dependence on  $\textit {Re}_\lambda$. To address this, a multi-level version of the RDGF closure (called ML-RDGF) was developed (Johnson & Meneveau Reference Johnson and Meneveau2017). The key idea behind this model is that in a turbulent flow, there exist velocity gradients at different scales in the flow, and the velocity gradient dynamics at different scales are coupled because of the energy cascade. Moreover, this coupling will be influenced by the fact that the energy flux through the cascade is not constant, but fluctuates in time and space. The ML-RDGF model extends the RDGF model to take this into account by replacing (2.23) with
$\textit {Re}_\lambda$. To address this, a multi-level version of the RDGF closure (called ML-RDGF) was developed (Johnson & Meneveau Reference Johnson and Meneveau2017). The key idea behind this model is that in a turbulent flow, there exist velocity gradients at different scales in the flow, and the velocity gradient dynamics at different scales are coupled because of the energy cascade. Moreover, this coupling will be influenced by the fact that the energy flux through the cascade is not constant, but fluctuates in time and space. The ML-RDGF model extends the RDGF model to take this into account by replacing (2.23) with
 \begin{align} {\rm d}\boldsymbol{\mathcal{A}}^{[n]}=\boldsymbol{\mathcal{N}}_{\mathcal{A}} \{\boldsymbol{\mathcal{A}}^{[n]},\tau,\tau_n\}\,{\rm d}t - d_t(\ln\tau_n)\boldsymbol{\mathcal{A}}^{[n]} +\boldsymbol{\varSigma}^{[n]} \boldsymbol{\cdot}{\rm d}\boldsymbol{\mathcal{W}}^{[n]},\quad n=1,2,\ldots,N,\end{align}
\begin{align} {\rm d}\boldsymbol{\mathcal{A}}^{[n]}=\boldsymbol{\mathcal{N}}_{\mathcal{A}} \{\boldsymbol{\mathcal{A}}^{[n]},\tau,\tau_n\}\,{\rm d}t - d_t(\ln\tau_n)\boldsymbol{\mathcal{A}}^{[n]} +\boldsymbol{\varSigma}^{[n]} \boldsymbol{\cdot}{\rm d}\boldsymbol{\mathcal{W}}^{[n]},\quad n=1,2,\ldots,N,\end{align}
in which the  $\tau _\eta$ appearing in (2.23) has been replaced by the time-dependent time scale
$\tau _\eta$ appearing in (2.23) has been replaced by the time-dependent time scale  $\tau _n(t)$, so that now
$\tau _n(t)$, so that now  $\tau =0.1302\tau _n$,
$\tau =0.1302\tau _n$,  $D_s=0.1014/\tau _n^3$ and
$D_s=0.1014/\tau _n^3$ and  $D_a=0.0505/\tau _n^3$.
$D_a=0.0505/\tau _n^3$.
Equation (2.24) is actually a system of  $N$ coupled equations, and
$N$ coupled equations, and  $\boldsymbol {\mathcal {A}}^{[n]}$ represents the velocity gradient at the
$\boldsymbol {\mathcal {A}}^{[n]}$ represents the velocity gradient at the  $n{{\rm th}}$ level, corresponding to the velocity gradient filtered on some scale. For the first level,
$n{{\rm th}}$ level, corresponding to the velocity gradient filtered on some scale. For the first level,  $n=1$, the time scale is fixed at
$n=1$, the time scale is fixed at  $\tau _1=\beta ^{N-1}\tau _\eta$, where
$\tau _1=\beta ^{N-1}\tau _\eta$, where  $\beta =10$ is chosen in the model. For
$\beta =10$ is chosen in the model. For  $n\geq 2$,
$n\geq 2$,  $\tau _n(t)\equiv \beta ^{-1}\|\boldsymbol {\mathcal {S}}^{[n-1]}\|^{-1}$ (where
$\tau _n(t)\equiv \beta ^{-1}\|\boldsymbol {\mathcal {S}}^{[n-1]}\|^{-1}$ (where  $\boldsymbol {\mathcal {S}}^{[n-1]}$ is the strain rate associated with
$\boldsymbol {\mathcal {S}}^{[n-1]}$ is the strain rate associated with  $\boldsymbol {\mathcal {A}}^{[n-1]}$), such that the time evolution of
$\boldsymbol {\mathcal {A}}^{[n-1]}$), such that the time evolution of  $\boldsymbol {\mathcal {A}}^{[n]}$ is coupled to the evolution at the larger scale where the velocity gradient is
$\boldsymbol {\mathcal {A}}^{[n]}$ is coupled to the evolution at the larger scale where the velocity gradient is  $\boldsymbol {\mathcal {A}}^{[n-1]}$. The solution at level
$\boldsymbol {\mathcal {A}}^{[n-1]}$. The solution at level  $n=N$ then corresponds to the full (unfiltered) velocity gradient, i.e.
$n=N$ then corresponds to the full (unfiltered) velocity gradient, i.e.  $\boldsymbol {\mathcal {A}}^{[N]}=\boldsymbol {\mathcal {A}}$. This multi-level model is capable of predicting
$\boldsymbol {\mathcal {A}}^{[N]}=\boldsymbol {\mathcal {A}}$. This multi-level model is capable of predicting  $\boldsymbol {\mathcal {A}}$ for the discrete Reynolds numbers
$\boldsymbol {\mathcal {A}}$ for the discrete Reynolds numbers  $\textit {Re}_\lambda =\textit {Re}_\lambda ^{[n=1]}\,\beta ^{N-1}$, where
$\textit {Re}_\lambda =\textit {Re}_\lambda ^{[n=1]}\,\beta ^{N-1}$, where  $\textit {Re}_\lambda ^{[n=1]}$ is the Taylor Reynolds number corresponding to the first level
$\textit {Re}_\lambda ^{[n=1]}$ is the Taylor Reynolds number corresponding to the first level  $n=1$, which was chosen in previous studies (Johnson & Meneveau Reference Johnson and Meneveau2017) to be
$n=1$, which was chosen in previous studies (Johnson & Meneveau Reference Johnson and Meneveau2017) to be  $\textit {Re}_\lambda ^{[n=1]}=60$. Then a modified time scale for the second level,
$\textit {Re}_\lambda ^{[n=1]}=60$. Then a modified time scale for the second level,  $\tau _2$, enables the model to predict flows at arbitrary
$\tau _2$, enables the model to predict flows at arbitrary  $\textit {Re}_\lambda$.
$\textit {Re}_\lambda$.
The predictions for  $\boldsymbol {\mathcal {A}}^{[N]}=\boldsymbol {\mathcal {A}}$ were shown to be in excellent agreement with DNS and experimental data (Johnson & Meneveau Reference Johnson and Meneveau2017), and revealed that the model makes robust predictions for the intermittency of
$\boldsymbol {\mathcal {A}}^{[N]}=\boldsymbol {\mathcal {A}}$ were shown to be in excellent agreement with DNS and experimental data (Johnson & Meneveau Reference Johnson and Meneveau2017), and revealed that the model makes robust predictions for the intermittency of  $\boldsymbol {\mathcal {A}}$ up to the highest Reynolds number considered,
$\boldsymbol {\mathcal {A}}$ up to the highest Reynolds number considered,  $\textit {Re}_\lambda = {O}(10^6)$.
$\textit {Re}_\lambda = {O}(10^6)$.
2.3. Closure for scalar gradient equation based on RDGF
Based on its excellent performance, the ML-RDGF model will be used to specify  $\boldsymbol {\mathcal {A}}$ in the equation for the scalar gradient
$\boldsymbol {\mathcal {A}}$ in the equation for the scalar gradient  $\boldsymbol {\mathcal {B}}$. The RDGF closure scheme will be used to close the scalar gradient diffusion term
$\boldsymbol {\mathcal {B}}$. The RDGF closure scheme will be used to close the scalar gradient diffusion term  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$. A multi-level version is not required since the effect of
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$. A multi-level version is not required since the effect of  $\textit {Re}_\lambda$ on the model for
$\textit {Re}_\lambda$ on the model for  $\boldsymbol {\mathcal {B}}$ will already be accounted for through the use of ML-RDGF to specify
$\boldsymbol {\mathcal {B}}$ will already be accounted for through the use of ML-RDGF to specify  $\boldsymbol {\mathcal {A}}$ in the equation for
$\boldsymbol {\mathcal {A}}$ in the equation for  $\boldsymbol {\mathcal {B}}$.
$\boldsymbol {\mathcal {B}}$.
Analogous to (2.21) and (2.22), under the RFDA, the scalar gradient diffusion term may be expressed as
 \begin{equation} \langle\nabla^2\boldsymbol{B}\rangle_{\boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}} \approx\boldsymbol{\mathcal{D}}^{-{\rm T}}\boldsymbol{\cdot}\left \langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}} \right\rangle_{\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}}}\boldsymbol{\cdot}\boldsymbol{\mathcal{D}}^{{-}1}.\end{equation}
\begin{equation} \langle\nabla^2\boldsymbol{B}\rangle_{\boldsymbol{\mathcal{A}},\boldsymbol{\mathcal{B}}} \approx\boldsymbol{\mathcal{D}}^{-{\rm T}}\boldsymbol{\cdot}\left \langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}} \right\rangle_{\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}}}\boldsymbol{\cdot}\boldsymbol{\mathcal{D}}^{{-}1}.\end{equation}
The RGFC can be used to derive a closed expression for the conditional average appearing in this expression, leading through (2.25) to an RDGF closure for  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$.
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$.
In the present context of the scalar field, the RGFC begins with the assumption that  $\phi$ has Gaussian statistics defined in terms of the characteristic functional
$\phi$ has Gaussian statistics defined in terms of the characteristic functional
 \begin{equation} \varSigma^{\phi}[\lambda(\boldsymbol{x})]=\exp\left[-\tfrac{1}{2}\int_{\mathbb{R}^3}\int_{\mathbb{R}^3}\lambda(\boldsymbol{x})\,R^{\phi}(\boldsymbol{x},\boldsymbol{x}')\,\lambda(\boldsymbol{x}')\, {\rm d}\kern0.7pt\boldsymbol{x}\,\,{\rm d}\kern0.7pt\boldsymbol{x}' \right]\end{equation}
\begin{equation} \varSigma^{\phi}[\lambda(\boldsymbol{x})]=\exp\left[-\tfrac{1}{2}\int_{\mathbb{R}^3}\int_{\mathbb{R}^3}\lambda(\boldsymbol{x})\,R^{\phi}(\boldsymbol{x},\boldsymbol{x}')\,\lambda(\boldsymbol{x}')\, {\rm d}\kern0.7pt\boldsymbol{x}\,\,{\rm d}\kern0.7pt\boldsymbol{x}' \right]\end{equation}
(the time label is suppressed here and in what follows for simplicity), where  $\lambda (\boldsymbol {x})$ is the Fourier variable conjugate to
$\lambda (\boldsymbol {x})$ is the Fourier variable conjugate to  $\phi (\boldsymbol {x})$, and
$\phi (\boldsymbol {x})$, and  $R^{\phi }(\boldsymbol {x},\boldsymbol {x}')\equiv \langle \phi (\boldsymbol {x})\,\phi (\boldsymbol {x}')\rangle$, which for isotropic turbulence has the form
$R^{\phi }(\boldsymbol {x},\boldsymbol {x}')\equiv \langle \phi (\boldsymbol {x})\,\phi (\boldsymbol {x}')\rangle$, which for isotropic turbulence has the form
 \begin{equation} R^{\phi}(\boldsymbol{x},\boldsymbol{x}')=R^{\phi}(r)=\langle\phi^2\rangle\,f_\phi(r),\quad \boldsymbol{r}\equiv \boldsymbol{x}-\boldsymbol{x}',\quad r\equiv\|\boldsymbol{r}\|,\end{equation}
\begin{equation} R^{\phi}(\boldsymbol{x},\boldsymbol{x}')=R^{\phi}(r)=\langle\phi^2\rangle\,f_\phi(r),\quad \boldsymbol{r}\equiv \boldsymbol{x}-\boldsymbol{x}',\quad r\equiv\|\boldsymbol{r}\|,\end{equation}
where  $f_\phi (r)$ is the scalar spatial correlation function. Following the work of Wilczek & Meneveau (Reference Wilczek and Meneveau2014), the characteristic function for the scalar gradient
$f_\phi (r)$ is the scalar spatial correlation function. Following the work of Wilczek & Meneveau (Reference Wilczek and Meneveau2014), the characteristic function for the scalar gradient  $\boldsymbol{B}\equiv \boldsymbol {\nabla }\phi$ is obtained from (2.26) as
$\boldsymbol{B}\equiv \boldsymbol {\nabla }\phi$ is obtained from (2.26) as
 \begin{equation} \varSigma^{\boldsymbol{B}}[\boldsymbol{\mu}(\boldsymbol{x})]=\exp \left[-\tfrac{1}{2}\int_{\mathbb{R}^3}\int_{\mathbb{R}^3}\boldsymbol{\mu}(\boldsymbol{x}) \boldsymbol{\cdot}\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{x},\boldsymbol{x}') \boldsymbol{\cdot}\boldsymbol{\mu}(\boldsymbol{x}')\,{\rm d}\kern0.7pt\boldsymbol{x}\, {\rm d}\kern0.7pt\boldsymbol{x}' \right],\end{equation}
\begin{equation} \varSigma^{\boldsymbol{B}}[\boldsymbol{\mu}(\boldsymbol{x})]=\exp \left[-\tfrac{1}{2}\int_{\mathbb{R}^3}\int_{\mathbb{R}^3}\boldsymbol{\mu}(\boldsymbol{x}) \boldsymbol{\cdot}\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{x},\boldsymbol{x}') \boldsymbol{\cdot}\boldsymbol{\mu}(\boldsymbol{x}')\,{\rm d}\kern0.7pt\boldsymbol{x}\, {\rm d}\kern0.7pt\boldsymbol{x}' \right],\end{equation}
where  $\boldsymbol {\mu }$ is the Fourier variable conjugate to
$\boldsymbol {\mu }$ is the Fourier variable conjugate to  $\boldsymbol{B}$, and
$\boldsymbol{B}$, and  $\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol {x},\boldsymbol {x}')\equiv \langle \boldsymbol{B}(\boldsymbol {x})\,\boldsymbol{B}'(\boldsymbol {x}')\rangle$, which is related to
$\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol {x},\boldsymbol {x}')\equiv \langle \boldsymbol{B}(\boldsymbol {x})\,\boldsymbol{B}'(\boldsymbol {x}')\rangle$, which is related to  $R^{\phi }(\boldsymbol {x},\boldsymbol {x}')$ through
$R^{\phi }(\boldsymbol {x},\boldsymbol {x}')$ through
 \begin{equation} \boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{x},\boldsymbol{x}')=\langle\boldsymbol{\nabla} \phi(\boldsymbol{x})\,\boldsymbol{\nabla}'\phi(\boldsymbol{x}')\rangle = \boldsymbol{\nabla}\boldsymbol{\nabla}'R^{\phi}(\boldsymbol{x},\boldsymbol{x}'). \end{equation}
\begin{equation} \boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{x},\boldsymbol{x}')=\langle\boldsymbol{\nabla} \phi(\boldsymbol{x})\,\boldsymbol{\nabla}'\phi(\boldsymbol{x}')\rangle = \boldsymbol{\nabla}\boldsymbol{\nabla}'R^{\phi}(\boldsymbol{x},\boldsymbol{x}'). \end{equation}For an isotropic scalar field where (2.27) applies, we then have
 \begin{equation} \boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{x},\boldsymbol{x}')=\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{r})= \langle\phi^2\rangle\left[\left(\frac{f_\phi'(r)}{r}-f_\phi^{\prime\prime}(r)\right) \frac{\boldsymbol{rr}}{r^2}-\frac{f_\phi'(r)}{r}\,\boldsymbol{\mathsf{I}}\right],\end{equation}
\begin{equation} \boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{x},\boldsymbol{x}')=\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{r})= \langle\phi^2\rangle\left[\left(\frac{f_\phi'(r)}{r}-f_\phi^{\prime\prime}(r)\right) \frac{\boldsymbol{rr}}{r^2}-\frac{f_\phi'(r)}{r}\,\boldsymbol{\mathsf{I}}\right],\end{equation}
where prime superscripts denote differentiation with respect to  $r$.
$r$.
According to (2.28), the statistics of  $\boldsymbol{B}$ are described by a Gaussian characteristic functional when
$\boldsymbol{B}$ are described by a Gaussian characteristic functional when  $\phi$ is assumed to be Gaussian. Just as in previous works (Wilczek & Meneveau Reference Wilczek and Meneveau2014; Johnson & Meneveau Reference Johnson and Meneveau2016), when deriving a closure model for
$\phi$ is assumed to be Gaussian. Just as in previous works (Wilczek & Meneveau Reference Wilczek and Meneveau2014; Johnson & Meneveau Reference Johnson and Meneveau2016), when deriving a closure model for  $D_t\boldsymbol {\mathcal {A}}$, it is acknowledged that the statistics of
$D_t\boldsymbol {\mathcal {A}}$, it is acknowledged that the statistics of  $\boldsymbol{B}$ are not Gaussian in a real turbulent flow (nor are they Gaussian even when
$\boldsymbol{B}$ are not Gaussian in a real turbulent flow (nor are they Gaussian even when  $\boldsymbol {u}$ is Gaussian; Falkovich et al. Reference Falkovich, Gawedzki and Vergassola2001). The motivation for this choice is simply that it is the only option when deriving a statistical field closure. It must be appreciated, however, that only with respect to the closure of
$\boldsymbol {u}$ is Gaussian; Falkovich et al. Reference Falkovich, Gawedzki and Vergassola2001). The motivation for this choice is simply that it is the only option when deriving a statistical field closure. It must be appreciated, however, that only with respect to the closure of  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$, are the statistics of
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$, are the statistics of  $\boldsymbol{B}$ approximated as being Gaussian; the model that follows from this choice nevertheless generates statistics for
$\boldsymbol{B}$ approximated as being Gaussian; the model that follows from this choice nevertheless generates statistics for  $\boldsymbol {\mathcal {B}}$ that are highly non-Gaussian (as will be shown later).
$\boldsymbol {\mathcal {B}}$ that are highly non-Gaussian (as will be shown later).
The specific term to be closed using RGFC is
 \begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}\right\rangle_{\boldsymbol{\mathsf{a}},\boldsymbol{b}}= \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}(\boldsymbol{x}^f(t\vert\boldsymbol{X},s),t)\right\rangle_{{ \boldsymbol{\mathsf{A}}}(\boldsymbol{x}^f(t\vert\boldsymbol{X},s),t)= \boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{x}^f(t\vert\boldsymbol{X},s),t)=\boldsymbol{b}}, \end{equation}
\begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}\right\rangle_{\boldsymbol{\mathsf{a}},\boldsymbol{b}}= \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}(\boldsymbol{x}^f(t\vert\boldsymbol{X},s),t)\right\rangle_{{ \boldsymbol{\mathsf{A}}}(\boldsymbol{x}^f(t\vert\boldsymbol{X},s),t)= \boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{x}^f(t\vert\boldsymbol{X},s),t)=\boldsymbol{b}}, \end{equation}
which is evaluated at  $\boldsymbol{\mathsf{a}}=\boldsymbol {\mathcal {A}}$,
$\boldsymbol{\mathsf{a}}=\boldsymbol {\mathcal {A}}$,  $\boldsymbol {b}=\boldsymbol {\mathcal {B}}$ in (2.25). Just as the RFDA assumes
$\boldsymbol {b}=\boldsymbol {\mathcal {B}}$ in (2.25). Just as the RFDA assumes  ${\boldsymbol{\mathsf{A}}}(\boldsymbol {x}^f(t\vert \boldsymbol {X},s),t)\approx {\boldsymbol{\mathsf{A}}}(\boldsymbol {X},s)$ for
${\boldsymbol{\mathsf{A}}}(\boldsymbol {x}^f(t\vert \boldsymbol {X},s),t)\approx {\boldsymbol{\mathsf{A}}}(\boldsymbol {X},s)$ for  $t-s\in [0,\tau ]$, we also assume
$t-s\in [0,\tau ]$, we also assume  ${\boldsymbol{B}}(\boldsymbol {x}^f(t\vert \boldsymbol {X},s),t)\approx {\boldsymbol{B}}(\boldsymbol {X},s)$ for
${\boldsymbol{B}}(\boldsymbol {x}^f(t\vert \boldsymbol {X},s),t)\approx {\boldsymbol{B}}(\boldsymbol {X},s)$ for  $t-s\in [0,\tau ]$, and inserting this yields
$t-s\in [0,\tau ]$, and inserting this yields
 \begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}\right\rangle_{\boldsymbol{\mathsf{a}},\boldsymbol{b}}\approx \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}(\boldsymbol{X},s)\right\rangle_{{\boldsymbol{\mathsf{A}}}(\boldsymbol{X},s)= \boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}}, \end{equation}
\begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}\right\rangle_{\boldsymbol{\mathsf{a}},\boldsymbol{b}}\approx \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{ \boldsymbol{B}}(\boldsymbol{X},s)\right\rangle_{{\boldsymbol{\mathsf{A}}}(\boldsymbol{X},s)= \boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}}, \end{equation}which puts the conditional average into a form to which the RGFC procedure (Wilczek & Meneveau Reference Wilczek and Meneveau2014) can be applied.
Before proceeding, we note that although the argument of the conditional average
 \begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial \boldsymbol{X}}\,{\boldsymbol{B}}(\boldsymbol{X},s)\right\rangle_{{\boldsymbol{\mathsf{A}}}(\boldsymbol{X},s)= \boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}} \end{equation}
\begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial \boldsymbol{X}}\,{\boldsymbol{B}}(\boldsymbol{X},s)\right\rangle_{{\boldsymbol{\mathsf{A}}}(\boldsymbol{X},s)= \boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}} \end{equation}
does not contain  $\boldsymbol{\mathsf{A}}$ but only
$\boldsymbol{\mathsf{A}}$ but only  $\boldsymbol{B}$, the conditionality on
$\boldsymbol{B}$, the conditionality on  $\boldsymbol{\mathsf{A}}(\boldsymbol {X},s)=\boldsymbol{\mathsf{a}}$ cannot be removed formally. This is because since the evolution of
$\boldsymbol{\mathsf{A}}(\boldsymbol {X},s)=\boldsymbol{\mathsf{a}}$ cannot be removed formally. This is because since the evolution of  $\boldsymbol{B}$ depends upon
$\boldsymbol{B}$ depends upon  $\boldsymbol{\mathsf{A}}$ (see (2.2)), the value of
$\boldsymbol{\mathsf{A}}$ (see (2.2)), the value of
 \begin{equation} \frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}} \end{equation}
\begin{equation} \frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}} \end{equation}
will not be uncorrelated from  $\boldsymbol{\mathsf{A}}$, in general. While a closure for the full conditional average can be obtained using the RDGF approach, the analysis is very involved, so in order to simplify the closure, the following approximation is made:
$\boldsymbol{\mathsf{A}}$, in general. While a closure for the full conditional average can be obtained using the RDGF approach, the analysis is very involved, so in order to simplify the closure, the following approximation is made:
 \begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}}(\boldsymbol{X},s) \right\rangle_{{\boldsymbol{\mathsf{A}}}(\boldsymbol{X},s)=\boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{X},s)= \boldsymbol{b}}\approx \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}}( \boldsymbol{X},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}}.\end{equation}
\begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}}(\boldsymbol{X},s) \right\rangle_{{\boldsymbol{\mathsf{A}}}(\boldsymbol{X},s)=\boldsymbol{\mathsf{a}},\ {\boldsymbol{B}}(\boldsymbol{X},s)= \boldsymbol{b}}\approx \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}}( \boldsymbol{X},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}}.\end{equation}
It is crucial to note, however, that the overall closure for  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ does partially include the effect of the conditioning upon
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ does partially include the effect of the conditioning upon  $\boldsymbol {\mathcal {A}}$, since the right-hand side of (2.25) contains
$\boldsymbol {\mathcal {A}}$, since the right-hand side of (2.25) contains  $\boldsymbol {\mathcal {D}}$ and not
$\boldsymbol {\mathcal {D}}$ and not  $\boldsymbol{\mathsf{D}}$ precisely because of the conditionality in the averaging operator on the left-hand side of (2.25). Therefore, the closure for
$\boldsymbol{\mathsf{D}}$ precisely because of the conditionality in the averaging operator on the left-hand side of (2.25). Therefore, the closure for  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ captures some of the dependency of the scalar diffusion on the local velocity gradients in the flow.
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ captures some of the dependency of the scalar diffusion on the local velocity gradients in the flow.
With the statistics of  $\boldsymbol{B}$ prescribed using (2.28), and the covariance tensor for
$\boldsymbol{B}$ prescribed using (2.28), and the covariance tensor for  $\boldsymbol{B}$ prescribed using (2.30), a closure for (2.35), and hence
$\boldsymbol{B}$ prescribed using (2.30), a closure for (2.35), and hence  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$, may be obtained following the same steps as in Wilczek & Meneveau (Reference Wilczek and Meneveau2014). The basic steps are as follows. First, using the approach described in Appendix A of Wilczek & Meneveau (Reference Wilczek and Meneveau2014), the unclosed quantity is rewritten in terms of a two-point quantity:
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$, may be obtained following the same steps as in Wilczek & Meneveau (Reference Wilczek and Meneveau2014). The basic steps are as follows. First, using the approach described in Appendix A of Wilczek & Meneveau (Reference Wilczek and Meneveau2014), the unclosed quantity is rewritten in terms of a two-point quantity:
 \begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}} (\boldsymbol{X},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}}=\lim_{r\to 0}\frac{\partial^2}{\partial\boldsymbol{r}\,\partial\boldsymbol{r}}\left\langle \boldsymbol{B}(\boldsymbol{X}+\boldsymbol{r},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)= \boldsymbol{b}}. \end{equation}
\begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial\boldsymbol{X}}\,{\boldsymbol{B}} (\boldsymbol{X},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)=\boldsymbol{b}}=\lim_{r\to 0}\frac{\partial^2}{\partial\boldsymbol{r}\,\partial\boldsymbol{r}}\left\langle \boldsymbol{B}(\boldsymbol{X}+\boldsymbol{r},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)= \boldsymbol{b}}. \end{equation}Applying the steps outlined in Appendix B of Wilczek & Meneveau (Reference Wilczek and Meneveau2014) to the scalar field, we obtain
 \begin{equation} \left\langle \boldsymbol{B}(\boldsymbol{X}+\boldsymbol{r},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)= \boldsymbol{b}}=\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{r})\boldsymbol{\cdot} [\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{0})]^{{-}1}\boldsymbol{\cdot} \boldsymbol{b}, \end{equation}
\begin{equation} \left\langle \boldsymbol{B}(\boldsymbol{X}+\boldsymbol{r},s)\right\rangle_{{\boldsymbol{B}}(\boldsymbol{X},s)= \boldsymbol{b}}=\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{r})\boldsymbol{\cdot} [\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{0})]^{{-}1}\boldsymbol{\cdot} \boldsymbol{b}, \end{equation}where
 \begin{equation} [\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{0})]^{{-}1}=\frac{\boldsymbol{\mathsf{I}}}{\langle\phi^2\rangle\, f_\phi^{\prime\prime}(0)}. \end{equation}
\begin{equation} [\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{0})]^{{-}1}=\frac{\boldsymbol{\mathsf{I}}}{\langle\phi^2\rangle\, f_\phi^{\prime\prime}(0)}. \end{equation}The resulting expression
 \begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial \boldsymbol{X}}\,{\boldsymbol{B}}(\boldsymbol{X},s)\right\rangle_{{\boldsymbol{B}} (\boldsymbol{X},s)=\boldsymbol{b}}=\lim_{r\to 0}\left(\frac{\partial^2}{\partial\boldsymbol{r}\,\partial\boldsymbol{r}}\, \boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{r})\right)\boldsymbol{\cdot} [\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{0})]^{{-}1}\boldsymbol{\cdot}\boldsymbol{b} \end{equation}
\begin{equation} \left\langle\frac{\partial^2}{\partial\boldsymbol{X}\,\partial \boldsymbol{X}}\,{\boldsymbol{B}}(\boldsymbol{X},s)\right\rangle_{{\boldsymbol{B}} (\boldsymbol{X},s)=\boldsymbol{b}}=\lim_{r\to 0}\left(\frac{\partial^2}{\partial\boldsymbol{r}\,\partial\boldsymbol{r}}\, \boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{r})\right)\boldsymbol{\cdot} [\boldsymbol{\mathsf{R}}^{\boldsymbol{\mathsf{B}}}(\boldsymbol{0})]^{{-}1}\boldsymbol{\cdot}\boldsymbol{b} \end{equation}
may then be computed using (2.30), and when the result is evaluated at  $\boldsymbol {b}=\boldsymbol {\mathcal {B}}$ and substituted into (2.25), the closed expression obtained is
$\boldsymbol {b}=\boldsymbol {\mathcal {B}}$ and substituted into (2.25), the closed expression obtained is
 $$\begin{gather} \kappa\langle\nabla^2\,\boldsymbol{B}\rangle_{\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}}}\approx \delta_\mathcal{B}(\boldsymbol{\mathcal{C}}_R^{{-}1}\boldsymbol{\cdot}\boldsymbol{\mathcal{B}}+ \boldsymbol{\mathcal{C}}_R^{-{\rm T}}\boldsymbol{\cdot}\boldsymbol{\mathcal{B}} + \mathrm{tr}(\boldsymbol{\mathcal{C}}_R^{{-}1})\boldsymbol{\mathcal{B}}), \end{gather}$$
$$\begin{gather} \kappa\langle\nabla^2\,\boldsymbol{B}\rangle_{\boldsymbol{\mathcal{A}}, \boldsymbol{\mathcal{B}}}\approx \delta_\mathcal{B}(\boldsymbol{\mathcal{C}}_R^{{-}1}\boldsymbol{\cdot}\boldsymbol{\mathcal{B}}+ \boldsymbol{\mathcal{C}}_R^{-{\rm T}}\boldsymbol{\cdot}\boldsymbol{\mathcal{B}} + \mathrm{tr}(\boldsymbol{\mathcal{C}}_R^{{-}1})\boldsymbol{\mathcal{B}}), \end{gather}$$ $$\begin{gather}\delta_{\mathcal{B}}\equiv\frac{\kappa}{3}\,\frac{f_\phi^{\prime\prime\prime\prime}(0)}{f_\phi^{\prime\prime}(0)}, \end{gather}$$
$$\begin{gather}\delta_{\mathcal{B}}\equiv\frac{\kappa}{3}\,\frac{f_\phi^{\prime\prime\prime\prime}(0)}{f_\phi^{\prime\prime}(0)}, \end{gather}$$
where  $\boldsymbol {\mathcal {C}}_R^{-1}\equiv \boldsymbol {\mathcal {D}}^{-1}\boldsymbol {\cdot } \boldsymbol {\mathcal {D}}^{-{\rm T}}$ is the inverse of the right Cauchy–Green tensor.
$\boldsymbol {\mathcal {C}}_R^{-1}\equiv \boldsymbol {\mathcal {D}}^{-1}\boldsymbol {\cdot } \boldsymbol {\mathcal {D}}^{-{\rm T}}$ is the inverse of the right Cauchy–Green tensor.
In the work of Johnson & Meneveau (Reference Johnson and Meneveau2016), the coefficient analogous to  $\delta _\mathcal {B}$ in the closure for
$\delta _\mathcal {B}$ in the closure for  $\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$, namely
$\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$, namely  $\delta _\mathcal {A}$, was estimated based on the enstrophy production–dissipation balance at steady state. The same procedure can be applied to approximate
$\delta _\mathcal {A}$, was estimated based on the enstrophy production–dissipation balance at steady state. The same procedure can be applied to approximate  $\delta _\mathcal {B}$ based on the steady-state production–dissipation balance
$\delta _\mathcal {B}$ based on the steady-state production–dissipation balance  $\langle \boldsymbol{\mathsf{S}}\boldsymbol {:}\boldsymbol{BB}\rangle =$
$\langle \boldsymbol{\mathsf{S}}\boldsymbol {:}\boldsymbol{BB}\rangle =$  $-\kappa \,\langle \|\boldsymbol {\nabla } \boldsymbol{B}\|^2 \rangle$ (ignoring the contribution from the forcing since it is small), leading to
$-\kappa \,\langle \|\boldsymbol {\nabla } \boldsymbol{B}\|^2 \rangle$ (ignoring the contribution from the forcing since it is small), leading to
 $$\begin{gather} \delta_\mathcal{B}\approx \frac{1}{9\tau_\eta}\,\mathrm{tr} (\boldsymbol{\mathcal{C}}_L)\,\gamma_\mathcal{B}, \end{gather}$$
$$\begin{gather} \delta_\mathcal{B}\approx \frac{1}{9\tau_\eta}\,\mathrm{tr} (\boldsymbol{\mathcal{C}}_L)\,\gamma_\mathcal{B}, \end{gather}$$ $$\begin{gather}\gamma_\mathcal{B}\equiv \tau_\eta\,\frac{\langle\boldsymbol{\mathsf{S}}\boldsymbol{:}\boldsymbol{BB} \rangle}{\langle \|\boldsymbol{B}\|^2\rangle}, \end{gather}$$
$$\begin{gather}\gamma_\mathcal{B}\equiv \tau_\eta\,\frac{\langle\boldsymbol{\mathsf{S}}\boldsymbol{:}\boldsymbol{BB} \rangle}{\langle \|\boldsymbol{B}\|^2\rangle}, \end{gather}$$
where  $\boldsymbol {\mathcal {C}}_L\equiv \boldsymbol {\mathcal {D}}\boldsymbol {\cdot }\boldsymbol {\mathcal {D}}^{\rm T}$ is the left Cauchy–Green tensor.
$\boldsymbol {\mathcal {C}}_L\equiv \boldsymbol {\mathcal {D}}\boldsymbol {\cdot }\boldsymbol {\mathcal {D}}^{\rm T}$ is the left Cauchy–Green tensor.
Whereas the RDGF model for  $\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ is nonlinear in
$\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ is nonlinear in  $\boldsymbol {\mathcal {A}}$ due to the contributions from
$\boldsymbol {\mathcal {A}}$ due to the contributions from  $\boldsymbol {\mathcal {C}}_L$ and
$\boldsymbol {\mathcal {C}}_L$ and  $\boldsymbol {\mathcal {C}}_R$, the closure for
$\boldsymbol {\mathcal {C}}_R$, the closure for  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ in (2.40) is linear in
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ in (2.40) is linear in  $\boldsymbol {\mathcal {B}}$. This could potentially suggest an issue with (2.40) since it is known that models for
$\boldsymbol {\mathcal {B}}$. This could potentially suggest an issue with (2.40) since it is known that models for  $\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ that are linear in
$\langle \nabla ^2\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol {\mathcal {A}}}$ that are linear in  $\boldsymbol {\mathcal {A}}$ can suffer from finite-time singularities, depending on the initial conditions (Martın et al. Reference Martın, Dopazo and Valiño1998). However, given that the production term in the equation for
$\boldsymbol {\mathcal {A}}$ can suffer from finite-time singularities, depending on the initial conditions (Martın et al. Reference Martın, Dopazo and Valiño1998). However, given that the production term in the equation for  $\boldsymbol {\mathcal {B}}$ is
$\boldsymbol {\mathcal {B}}$ is  $-\boldsymbol {\mathcal {A}}^{\rm T}\boldsymbol {\cdot }\boldsymbol {\mathcal {B}}$, the dependence of the closure in (2.40) on
$-\boldsymbol {\mathcal {A}}^{\rm T}\boldsymbol {\cdot }\boldsymbol {\mathcal {B}}$, the dependence of the closure in (2.40) on  $\boldsymbol {\mathcal {C}}_L$ and
$\boldsymbol {\mathcal {C}}_L$ and  $\boldsymbol {\mathcal {C}}_R$ may indirectly prevent singular growth of
$\boldsymbol {\mathcal {C}}_R$ may indirectly prevent singular growth of  $\|\boldsymbol {\mathcal {B}}\|$, at least in regions where this growth is associated with large values of
$\|\boldsymbol {\mathcal {B}}\|$, at least in regions where this growth is associated with large values of  $\|\boldsymbol {\mathcal {A}}\|$, because in those regions, the growth of
$\|\boldsymbol {\mathcal {A}}\|$, because in those regions, the growth of  $\boldsymbol {\mathcal {B}}$ could be modulated through
$\boldsymbol {\mathcal {B}}$ could be modulated through  $\boldsymbol {\mathcal {C}}_L$ and
$\boldsymbol {\mathcal {C}}_L$ and  $\boldsymbol {\mathcal {C}}_R$. Moreover, we performed tests where in the closure for
$\boldsymbol {\mathcal {C}}_R$. Moreover, we performed tests where in the closure for  $\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$, we set
$\langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$, we set  $\boldsymbol {\mathcal {D}}=\boldsymbol{\mathsf{I}}$, i.e. so that the recent deformation mapping was removed. Simulations of the model using this blew up, showing that the contributions in (2.40) involving
$\boldsymbol {\mathcal {D}}=\boldsymbol{\mathsf{I}}$, i.e. so that the recent deformation mapping was removed. Simulations of the model using this blew up, showing that the contributions in (2.40) involving  $\boldsymbol {\mathcal {D}}$ do indeed play a key indirect role in preventing singular growth of
$\boldsymbol {\mathcal {D}}$ do indeed play a key indirect role in preventing singular growth of  $\boldsymbol {\mathcal {B}}$.
$\boldsymbol {\mathcal {B}}$.
In view of (2.42), any dependence of the closed expression for  $\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ on
$\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ on  $\kappa$ is contained within
$\kappa$ is contained within  $\gamma _\mathcal {B}$, and this term must be specified using data. However, in order for the model to depend upon
$\gamma _\mathcal {B}$, and this term must be specified using data. However, in order for the model to depend upon  $\kappa$ and hence
$\kappa$ and hence  $Sc$, the data must specify
$Sc$, the data must specify  $\gamma _\mathcal {B}$ as a function of
$\gamma _\mathcal {B}$ as a function of  $Sc$, which is not desirable. An alternative approach is as follows. The closure approximation in (2.40) is linear in
$Sc$, which is not desirable. An alternative approach is as follows. The closure approximation in (2.40) is linear in  $\boldsymbol {\mathcal {B}}$, and
$\boldsymbol {\mathcal {B}}$, and  $1/\delta _\mathcal {B}$ may be regarded as a linear relaxation time scale for
$1/\delta _\mathcal {B}$ may be regarded as a linear relaxation time scale for  $\boldsymbol {\mathcal {B}}$, describing how the diffusion term
$\boldsymbol {\mathcal {B}}$, describing how the diffusion term  $\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ causes
$\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ causes  $\boldsymbol {\mathcal {B}}$ to relax to its equilibrium value. In view of this,
$\boldsymbol {\mathcal {B}}$ to relax to its equilibrium value. In view of this,  $1/\delta _\mathcal {B}$ should scale with the small-scale scalar time scale
$1/\delta _\mathcal {B}$ should scale with the small-scale scalar time scale  $\tau _\phi$, and for
$\tau _\phi$, and for  $Sc\geq 1$, this time scale can be estimated using the Batchelor scale (Batchelor Reference Batchelor1959; Donzis, Sreenivasan & Yeung Reference Donzis, Sreenivasan and Yeung2005) as
$Sc\geq 1$, this time scale can be estimated using the Batchelor scale (Batchelor Reference Batchelor1959; Donzis, Sreenivasan & Yeung Reference Donzis, Sreenivasan and Yeung2005) as  $\tau _\phi \sim \tau _\eta \,Sc^{-1/3}$, while for
$\tau _\phi \sim \tau _\eta \,Sc^{-1/3}$, while for  $Sc<1$, the Corrsin scale (Corrsin Reference Corrsin1951) may be used to obtain
$Sc<1$, the Corrsin scale (Corrsin Reference Corrsin1951) may be used to obtain  $\tau _\phi \sim \tau _\eta \, Sc^{-1/2}$. In view of this, the
$\tau _\phi \sim \tau _\eta \, Sc^{-1/2}$. In view of this, the  $Sc$ dependence may be accounted for explicitly in
$Sc$ dependence may be accounted for explicitly in  $\delta _\mathcal {B}$ by using
$\delta _\mathcal {B}$ by using
 $$\begin{gather} \delta_\mathcal{B}\approx \frac{Sc^{\xi}}{9\tau_\eta}\,\mathrm{tr}(\boldsymbol{\mathcal{C}}_L)\,\alpha_\mathcal{B}, \end{gather}$$
$$\begin{gather} \delta_\mathcal{B}\approx \frac{Sc^{\xi}}{9\tau_\eta}\,\mathrm{tr}(\boldsymbol{\mathcal{C}}_L)\,\alpha_\mathcal{B}, \end{gather}$$ $$\begin{gather}\alpha_\mathcal{B}\equiv \left.\tau_\eta\,\frac{\langle\boldsymbol{\mathsf{S}}\boldsymbol{:}{\boldsymbol{BB}}\rangle}{\langle \|\boldsymbol{B}\|^2\rangle}\right\vert_{Sc=1}, \end{gather}$$
$$\begin{gather}\alpha_\mathcal{B}\equiv \left.\tau_\eta\,\frac{\langle\boldsymbol{\mathsf{S}}\boldsymbol{:}{\boldsymbol{BB}}\rangle}{\langle \|\boldsymbol{B}\|^2\rangle}\right\vert_{Sc=1}, \end{gather}$$
where  $\xi =1/2$ for
$\xi =1/2$ for  $Sc<1$, and
$Sc<1$, and  $\xi =1/3$ for
$\xi =1/3$ for  $Sc\geq 1$. From our DNS (see § 3) we obtain the value
$Sc\geq 1$. From our DNS (see § 3) we obtain the value  $\alpha _\mathcal {B}\approx -0.32$. However, in anticipation of results to be shown later, we note that using this fixed value for
$\alpha _\mathcal {B}\approx -0.32$. However, in anticipation of results to be shown later, we note that using this fixed value for  $\alpha _B$ yields a model whose predictions are not accurate (see figure 4). Therefore, a modification will be introduced wherein
$\alpha _B$ yields a model whose predictions are not accurate (see figure 4). Therefore, a modification will be introduced wherein  $\alpha _\mathcal {B}$ is specified based on the local scalar gradient production along the trajectory history of the particle, as in (4.1), which dramatically improves the predictions from the model (cf. figure 6).
$\alpha _\mathcal {B}$ is specified based on the local scalar gradient production along the trajectory history of the particle, as in (4.1), which dramatically improves the predictions from the model (cf. figure 6).
Analogous to the equation for  $\boldsymbol {\mathcal {A}}$, the forcing term in the scalar gradient equation is chosen to be
$\boldsymbol {\mathcal {A}}$, the forcing term in the scalar gradient equation is chosen to be  $\langle \boldsymbol {F_B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}\,{\rm d}t=\sigma \,{\rm d}\boldsymbol {\mathcal {W}}$, where now
$\langle \boldsymbol {F_B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}\,{\rm d}t=\sigma \,{\rm d}\boldsymbol {\mathcal {W}}$, where now  ${\rm d}\boldsymbol {\mathcal {W}}$ is a vector-valued Wiener process with increments defined by
${\rm d}\boldsymbol {\mathcal {W}}$ is a vector-valued Wiener process with increments defined by
 $$\begin{gather} \langle {\rm d}\boldsymbol{\mathcal{W}}\rangle=\boldsymbol{0}, \end{gather}$$
$$\begin{gather} \langle {\rm d}\boldsymbol{\mathcal{W}}\rangle=\boldsymbol{0}, \end{gather}$$ $$\begin{gather}\langle {\rm d}\boldsymbol{\mathcal{W}}\,{\rm d}\boldsymbol{\mathcal{W}}\rangle=\boldsymbol{\mathsf{I}}\,{\rm d}t. \end{gather}$$
$$\begin{gather}\langle {\rm d}\boldsymbol{\mathcal{W}}\,{\rm d}\boldsymbol{\mathcal{W}}\rangle=\boldsymbol{\mathsf{I}}\,{\rm d}t. \end{gather}$$
Since the equation for  $\boldsymbol {\mathcal {B}}$ is linear, the statistics scale with the forcing amplitude
$\boldsymbol {\mathcal {B}}$ is linear, the statistics scale with the forcing amplitude  $\sigma$, therefore
$\sigma$, therefore  $\sigma$ may be chosen arbitrarily if the results generated by the model are suitably normalized. Using this forcing term, the final form of the model equation is written as a stochastic differential equation
$\sigma$ may be chosen arbitrarily if the results generated by the model are suitably normalized. Using this forcing term, the final form of the model equation is written as a stochastic differential equation
 \begin{equation} {\rm d}\boldsymbol{\mathcal{B}}\approx{-}\boldsymbol{\mathcal{A}}^{\rm T}\boldsymbol{\cdot}\boldsymbol{\mathcal{B}} \,{\rm d}t+\delta_\mathcal{B}(\boldsymbol{\mathcal{C}}_R^{{-}1}\boldsymbol{\cdot}{\boldsymbol{\mathcal{B}}}+ \boldsymbol{\mathcal{C}}_R^{-{\rm T}}\boldsymbol{\cdot}{\boldsymbol{\mathcal{B}}} + \mathrm{tr}(\boldsymbol{\mathcal{C}}_R^{{-}1})\,\boldsymbol{\mathcal{B}}){\rm d}t+ \sigma \,{\rm d}\boldsymbol{\mathcal{W}}.\end{equation}
\begin{equation} {\rm d}\boldsymbol{\mathcal{B}}\approx{-}\boldsymbol{\mathcal{A}}^{\rm T}\boldsymbol{\cdot}\boldsymbol{\mathcal{B}} \,{\rm d}t+\delta_\mathcal{B}(\boldsymbol{\mathcal{C}}_R^{{-}1}\boldsymbol{\cdot}{\boldsymbol{\mathcal{B}}}+ \boldsymbol{\mathcal{C}}_R^{-{\rm T}}\boldsymbol{\cdot}{\boldsymbol{\mathcal{B}}} + \mathrm{tr}(\boldsymbol{\mathcal{C}}_R^{{-}1})\,\boldsymbol{\mathcal{B}}){\rm d}t+ \sigma \,{\rm d}\boldsymbol{\mathcal{W}}.\end{equation}For applications where there is a mean scalar gradient, the forcing term could be replaced by the term describing the production of fluctuating scalar gradients due to the imposed mean scalar gradient.
Finally, just as the ML-RDGF model replaces the constant time scale for  $\boldsymbol {\mathcal {A}}^{[N]}$ with the fluctuating time scale
$\boldsymbol {\mathcal {A}}^{[N]}$ with the fluctuating time scale  $\tau _N(t)$, the Kolmogorov time scale
$\tau _N(t)$, the Kolmogorov time scale  $\tau _\eta$ that appears in (2.44) should also, for consistency, be replaced by
$\tau _\eta$ that appears in (2.44) should also, for consistency, be replaced by  $\tau _N(t)$ (since the ML-RDGF model is being used to specify
$\tau _N(t)$ (since the ML-RDGF model is being used to specify  $\boldsymbol {\mathcal {A}}$ in (2.48)). In other words, (2.44) is to be replaced by
$\boldsymbol {\mathcal {A}}$ in (2.48)). In other words, (2.44) is to be replaced by
 \begin{equation} \delta_\mathcal{B}\approx \frac{Sc^{\xi}}{9\tau_N(t)}\,\mathrm{tr}(\boldsymbol{\mathcal{C}}_L)\,\alpha_\mathcal{B}.\end{equation}
\begin{equation} \delta_\mathcal{B}\approx \frac{Sc^{\xi}}{9\tau_N(t)}\,\mathrm{tr}(\boldsymbol{\mathcal{C}}_L)\,\alpha_\mathcal{B}.\end{equation}
This ensures that for  $Sc=1$, the local time scale on which both
$Sc=1$, the local time scale on which both  $\boldsymbol {\mathcal {B}}$ and
$\boldsymbol {\mathcal {B}}$ and  $\boldsymbol {\mathcal {A}}$ fluctuate is
$\boldsymbol {\mathcal {A}}$ fluctuate is  $O(\tau _N(t))$.
$O(\tau _N(t))$.
3. Numerical simulations
We test the model predictions against data from DNS of a passive scalar field advected by an incompressible, three-dimensional, statistically steady and isotropic turbulent velocity field. The DNS code uses a standard Fourier pseudo-spectral method (Canuto et al. Reference Canuto, Hussaini, Quarteroni and Zang1988) to solve the discretized Navier–Stokes and passive scalar equations on a triply periodic cubic domain, resolving  $N$ Fourier modes in each direction. The required Fourier transforms are executed in parallel using the P3DFFT library (Pekurovsky Reference Pekurovsky2012), and the aliasing error is removed via the
$N$ Fourier modes in each direction. The required Fourier transforms are executed in parallel using the P3DFFT library (Pekurovsky Reference Pekurovsky2012), and the aliasing error is removed via the  $3/2$ rule (Canuto et al. Reference Canuto, Hussaini, Quarteroni and Zang1988). The code is described in further detail in Carbone, Bragg & Iovieno (Reference Carbone, Bragg and Iovieno2019).
$3/2$ rule (Canuto et al. Reference Canuto, Hussaini, Quarteroni and Zang1988). The code is described in further detail in Carbone, Bragg & Iovieno (Reference Carbone, Bragg and Iovieno2019).
The non-dimensional governing equation for the passive scalar in Fourier space reads
 \begin{equation} \partial_t \hat{\phi} + \textrm{i} \boldsymbol{k}\boldsymbol{\cdot}\widehat{\boldsymbol{u}\phi} ={-}\kappa\|\boldsymbol{k}\|^2\hat{\phi}+ \hat{F}, \end{equation}
\begin{equation} \partial_t \hat{\phi} + \textrm{i} \boldsymbol{k}\boldsymbol{\cdot}\widehat{\boldsymbol{u}\phi} ={-}\kappa\|\boldsymbol{k}\|^2\hat{\phi}+ \hat{F}, \end{equation}
where the hat indicates a Fourier transform, ‘ $\textrm {i}$’ is the imaginary unit,
$\textrm {i}$’ is the imaginary unit,  $\boldsymbol {u}(\boldsymbol {x},t)$ is the turbulent velocity field,
$\boldsymbol {u}(\boldsymbol {x},t)$ is the turbulent velocity field,  $\phi (\boldsymbol {x},t)$ is the passive scalar field, and
$\phi (\boldsymbol {x},t)$ is the passive scalar field, and  $\hat {\phi }(\boldsymbol {k},t)$ denotes its spatial Fourier transform. For consistency with the stochastic model, the passive scalar field is driven by a stochastic forcing, such that the complex forcing
$\hat {\phi }(\boldsymbol {k},t)$ denotes its spatial Fourier transform. For consistency with the stochastic model, the passive scalar field is driven by a stochastic forcing, such that the complex forcing  $\hat {F}$ is Gaussian and white in time, with correlation
$\hat {F}$ is Gaussian and white in time, with correlation
 \begin{equation} \left\langle \hat{F}(\boldsymbol{k},t)\,\hat{F}(\boldsymbol{k}',t') \right\rangle = 2\sigma_0^2\, \|\boldsymbol{k}\|^2\,\delta(\boldsymbol{k}+\boldsymbol{k}')\,\delta(t-t'), \quad 0<\|\boldsymbol{k}\|< k_f. \end{equation}
\begin{equation} \left\langle \hat{F}(\boldsymbol{k},t)\,\hat{F}(\boldsymbol{k}',t') \right\rangle = 2\sigma_0^2\, \|\boldsymbol{k}\|^2\,\delta(\boldsymbol{k}+\boldsymbol{k}')\,\delta(t-t'), \quad 0<\|\boldsymbol{k}\|< k_f. \end{equation}
The forcing is confined to the wave vectors  $\boldsymbol {k}$ within a sphere of radius
$\boldsymbol {k}$ within a sphere of radius  $k_f$, and we choose
$k_f$, and we choose  $k_f=\sqrt {7}$ since it yields large-scale statistics that are close to being isotropic. Finally, the spectrum of the forcing
$k_f=\sqrt {7}$ since it yields large-scale statistics that are close to being isotropic. Finally, the spectrum of the forcing  $|\hat {F}|^2(k)$ scales as
$|\hat {F}|^2(k)$ scales as  $\|\boldsymbol {k}\|^2$, compatible with energy equipartition among the smallest Fourier modes. The constant parameter
$\|\boldsymbol {k}\|^2$, compatible with energy equipartition among the smallest Fourier modes. The constant parameter  $\sigma _0$ in (3.2) regulates the magnitude of the scalar fluctuations, and it can be arbitrarily chosen due to the linearity with respect to
$\sigma _0$ in (3.2) regulates the magnitude of the scalar fluctuations, and it can be arbitrarily chosen due to the linearity with respect to  $\hat {\phi }$ of (3.1). We simulate flows at
$\hat {\phi }$ of (3.1). We simulate flows at  $Sc=1$. The simulated Reynolds numbers are
$Sc=1$. The simulated Reynolds numbers are  $\textit {Re}_\lambda =100,250$, using
$\textit {Re}_\lambda =100,250$, using  $N=512,1024$ Fourier modes in each direction, with the results referred to as DNS1 and DNS2, respectively. The spatial resolution is
$N=512,1024$ Fourier modes in each direction, with the results referred to as DNS1 and DNS2, respectively. The spatial resolution is  $k_{max}\eta \approx 3$, with
$k_{max}\eta \approx 3$, with  $k_{max}=N/2$ being the maximum resolved wavenumber, for both simulations. The time integration of (3.1) is performed by means of a second-order Runge–Kutta scheme designed for stochastic differential equations (Honeycutt Reference Honeycutt1992), and the CFL number stays below 0.3.
$k_{max}=N/2$ being the maximum resolved wavenumber, for both simulations. The time integration of (3.1) is performed by means of a second-order Runge–Kutta scheme designed for stochastic differential equations (Honeycutt Reference Honeycutt1992), and the CFL number stays below 0.3.
Regarding the numerical simulations of the model, we solve the scalar gradient equation (2.48) using a second-order predictor–corrector method (Kloeden & Platen Reference Kloeden and Platen2018) with time step  ${\rm d}t=0.05\tau _{\eta }$. Each level of the ML-RDGF model equation was solved using its own appropriate time step, namely, level
${\rm d}t=0.05\tau _{\eta }$. Each level of the ML-RDGF model equation was solved using its own appropriate time step, namely, level  $n$ was solved using
$n$ was solved using  ${\rm d}t=0.05\langle \tau _n(t)\rangle$. Tests were performed using smaller time steps, and these tests indicated that the aforementioned time steps were small enough to achieve convergence of the results.
${\rm d}t=0.05\langle \tau _n(t)\rangle$. Tests were performed using smaller time steps, and these tests indicated that the aforementioned time steps were small enough to achieve convergence of the results.
We solve numerically the model equation (2.48) for  $\textit {Re}_\lambda =100, 250, 500$. The results from these runs will be referred to as M1, M2 and M3 in the results section, with M1 and M2 designed to match DNS1 and DNS2, respectively. Although we do not have DNS data for quantitative comparison with M3, these model results are also considered in order to explore more fully how the model predicts that
$\textit {Re}_\lambda =100, 250, 500$. The results from these runs will be referred to as M1, M2 and M3 in the results section, with M1 and M2 designed to match DNS1 and DNS2, respectively. Although we do not have DNS data for quantitative comparison with M3, these model results are also considered in order to explore more fully how the model predicts that  $\textit {Re}_\lambda$ impacts the scalar gradient statistics.
$\textit {Re}_\lambda$ impacts the scalar gradient statistics.
4. Results and discussion
4.1. Velocity gradients
In our scalar gradient model, the velocity gradients are specified using the ML-RDGF model (Johnson & Meneveau Reference Johnson and Meneveau2017). We therefore begin by comparing the predictions of this model against the DNS data in order to assess its accuracy in predicting the statistics  $\boldsymbol {\mathcal {A}}$, since any inaccuracies in this model will in turn lead to inaccuracies in our model for the scalar gradients.
$\boldsymbol {\mathcal {A}}$, since any inaccuracies in this model will in turn lead to inaccuracies in our model for the scalar gradients.
In figure 1, we compare the p.d.f.s of the longitudinal and transverse components of the velocity gradient predicted by the ML-RDGF model with the DNS results. (Recall that  $\boldsymbol{\mathsf{a}}$ and
$\boldsymbol{\mathsf{a}}$ and  $\boldsymbol {b}$ are the phase-space variables conjugate to
$\boldsymbol {b}$ are the phase-space variables conjugate to  $\boldsymbol {\mathcal {A}}$ and
$\boldsymbol {\mathcal {A}}$ and  $\boldsymbol {\mathcal {B}}$, respectively, and we use the subscripts ‘
$\boldsymbol {\mathcal {B}}$, respectively, and we use the subscripts ‘ $rms$’ and ‘
$rms$’ and ‘ $av$’ to denote the root-mean-square and averaged values of the variable under consideration). One can see that the p.d.f.s for the longitudinal gradients (figure 1a) are negatively skewed, while the p.d.f.s for the transverse gradients are symmetric (figure 1b). The former is associated with the self-amplification of the velocity gradients (Tsinober Reference Tsinober2001), while the latter is a constraint due to isotropy. The predictions from M1 and M2 are in excellent agreement with the DNS data, capturing the increased intermittency as
$av$’ to denote the root-mean-square and averaged values of the variable under consideration). One can see that the p.d.f.s for the longitudinal gradients (figure 1a) are negatively skewed, while the p.d.f.s for the transverse gradients are symmetric (figure 1b). The former is associated with the self-amplification of the velocity gradients (Tsinober Reference Tsinober2001), while the latter is a constraint due to isotropy. The predictions from M1 and M2 are in excellent agreement with the DNS data, capturing the increased intermittency as  $\textit {Re}_\lambda$ is increased, and the model also makes realistic predictions at the higher
$\textit {Re}_\lambda$ is increased, and the model also makes realistic predictions at the higher  $\textit {Re}_\lambda$ to which M3 corresponds. The ability of the ML-RDGF model to predict accurately the components of the velocity gradient, and realistic intermittency trends with increasing
$\textit {Re}_\lambda$ to which M3 corresponds. The ability of the ML-RDGF model to predict accurately the components of the velocity gradient, and realistic intermittency trends with increasing  $\textit {Re}_\lambda$ (and over a much larger range of
$\textit {Re}_\lambda$ (and over a much larger range of  $\textit {Re}_\lambda$ than considered here), were demonstrated previously in detail in the original ML-RDGF paper of Johnson & Meneveau (Reference Johnson and Meneveau2017).
$\textit {Re}_\lambda$ than considered here), were demonstrated previously in detail in the original ML-RDGF paper of Johnson & Meneveau (Reference Johnson and Meneveau2017).

Figure 1. The p.d.f.s of (a) longitudinal  $a_{11}/a_{11,rms}$ and (b) transverse
$a_{11}/a_{11,rms}$ and (b) transverse  $a_{12}/a_{12,rms}$ velocity gradients.
$a_{12}/a_{12,rms}$ velocity gradients.
Further insight into the ability of the ML-RDGF model to predict the velocity gradient dynamics can be obtained by considering its predictions for the velocity gradient invariants  $Q\equiv -\boldsymbol{\mathsf{a}}\boldsymbol {:}\boldsymbol{\mathsf{a}}/2$ and
$Q\equiv -\boldsymbol{\mathsf{a}}\boldsymbol {:}\boldsymbol{\mathsf{a}}/2$ and  $R\equiv -(\boldsymbol{\mathsf{a}}\boldsymbol {\cdot } \boldsymbol{\mathsf{a}}) \boldsymbol {:}\boldsymbol{\mathsf{a}}/3$. The invariant
$R\equiv -(\boldsymbol{\mathsf{a}}\boldsymbol {\cdot } \boldsymbol{\mathsf{a}}) \boldsymbol {:}\boldsymbol{\mathsf{a}}/3$. The invariant  $Q$ measures the relative strength of the local strain rate and vorticity in the flow, with
$Q$ measures the relative strength of the local strain rate and vorticity in the flow, with  $Q>0$ denoting vorticity-dominated regions of the flow, while
$Q>0$ denoting vorticity-dominated regions of the flow, while  $R$ measures the relative importance of the local strain self-amplification and enstrophy production, with
$R$ measures the relative importance of the local strain self-amplification and enstrophy production, with  $R<0$ denoting regions dominated by enstrophy production (Tsinober Reference Tsinober2001). The joint p.d.f.s of
$R<0$ denoting regions dominated by enstrophy production (Tsinober Reference Tsinober2001). The joint p.d.f.s of  $Q$ and
$Q$ and  $R$ from the ML-RDGF model for M1, M2 are presented in figure 2, along with the corresponding DNS results of the same Reynolds numbers for comparisons. As observed previously (Johnson & Meneveau Reference Johnson and Meneveau2017), the ML-RDGF model captures the main features of the
$R$ from the ML-RDGF model for M1, M2 are presented in figure 2, along with the corresponding DNS results of the same Reynolds numbers for comparisons. As observed previously (Johnson & Meneveau Reference Johnson and Meneveau2017), the ML-RDGF model captures the main features of the  $Q,R$ joint p.d.f. well, including the signature sheared-drop shape of the joint p.d.f., which is preserved by the model as
$Q,R$ joint p.d.f. well, including the signature sheared-drop shape of the joint p.d.f., which is preserved by the model as  $\textit {Re}_\lambda$ is increased. The joint p.d.f. contours extend along the right Viellefosse tail, and the p.d.f. is concentrated in the quadrants
$\textit {Re}_\lambda$ is increased. The joint p.d.f. contours extend along the right Viellefosse tail, and the p.d.f. is concentrated in the quadrants  $Q>0, R<0$ and
$Q>0, R<0$ and  $Q<0, R>0$, consistent with previous studies (Johnson & Meneveau Reference Johnson and Meneveau2016, Reference Johnson and Meneveau2017). For the model results M1 and M2, the joint p.d.f.s are more compact compared to the DNS, indicating that the model underpredicts the probability of large values of
$Q<0, R>0$, consistent with previous studies (Johnson & Meneveau Reference Johnson and Meneveau2016, Reference Johnson and Meneveau2017). For the model results M1 and M2, the joint p.d.f.s are more compact compared to the DNS, indicating that the model underpredicts the probability of large values of  $Q,R$. The agreement between the ML-RDGF model and DNS data was shown to be better in Johnson & Meneveau (Reference Johnson and Meneveau2017); however, their DNS data were for
$Q,R$. The agreement between the ML-RDGF model and DNS data was shown to be better in Johnson & Meneveau (Reference Johnson and Meneveau2017); however, their DNS data were for  $\textit {Re}_\lambda =430$, indicating that the quantitative accuracy of the model is better at higher
$\textit {Re}_\lambda =430$, indicating that the quantitative accuracy of the model is better at higher  $\textit {Re}_\lambda$. Considering the results for M2 shows that as
$\textit {Re}_\lambda$. Considering the results for M2 shows that as  $\textit {Re}_\lambda$ increases, the contours of the joint p.d.f. spread out in the
$\textit {Re}_\lambda$ increases, the contours of the joint p.d.f. spread out in the  $(Q,R)$ phase-space, showing that the model captures the effect of
$(Q,R)$ phase-space, showing that the model captures the effect of  $\textit {Re}_\lambda$ on the intermittency in the flow.
$\textit {Re}_\lambda$ on the intermittency in the flow.

Figure 2. Logarithms of joint p.d.f.s of  $Q/\tilde {Q}_{av}$ and
$Q/\tilde {Q}_{av}$ and  $R/\tilde {Q}_{av}^{3/2}$ (where
$R/\tilde {Q}_{av}^{3/2}$ (where  $\tilde {Q}_{av}\equiv \langle \|\mathcal {A}\|^2\rangle$) from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
$\tilde {Q}_{av}\equiv \langle \|\mathcal {A}\|^2\rangle$) from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
A more careful and quantitative comparison between the model predictions and DNS data for  $Q,R$ can be made by comparing the p.d.f.s of
$Q,R$ can be made by comparing the p.d.f.s of  $Q$ and
$Q$ and  $R$ separately. In figure 3(a), one can see that for DNS1 and DNS2, the p.d.f.s of
$R$ separately. In figure 3(a), one can see that for DNS1 and DNS2, the p.d.f.s of  $Q$ are strongly positively skewed, which is associated with the fact that the vorticity is more intermittent than the strain rate in turbulent flows (Yeung, Sreenivasan & Pope Reference Yeung, Sreenivasan and Pope2018). By contrast, the ML-RDGF model predicts p.d.f.s for
$Q$ are strongly positively skewed, which is associated with the fact that the vorticity is more intermittent than the strain rate in turbulent flows (Yeung, Sreenivasan & Pope Reference Yeung, Sreenivasan and Pope2018). By contrast, the ML-RDGF model predicts p.d.f.s for  $Q$ that are much more symmetric, with the model significantly underpredicting regions of intense vorticity, and slightly underpredicting regions of intense straining. These discrepancies are, however, mainly in the tails of the p.d.f., with the model predictions in good agreement with the DNS for values of the p.d.f. that are
$Q$ that are much more symmetric, with the model significantly underpredicting regions of intense vorticity, and slightly underpredicting regions of intense straining. These discrepancies are, however, mainly in the tails of the p.d.f., with the model predictions in good agreement with the DNS for values of the p.d.f. that are  ${\geq}O(10^{-2})$.
${\geq}O(10^{-2})$.

Figure 3. The p.d.f.s of (a)  $Q/\tilde {Q}_{av}$ and (b)
$Q/\tilde {Q}_{av}$ and (b)  $R/\tilde {Q}_{av}^{3/2}$, where
$R/\tilde {Q}_{av}^{3/2}$, where  $\tilde {Q}_{av}\equiv \langle \|\boldsymbol {\mathcal {A}}\|^2\rangle$.
$\tilde {Q}_{av}\equiv \langle \|\boldsymbol {\mathcal {A}}\|^2\rangle$.
In figure 3(b), it is seen that the model also predicts p.d.f.s of  $R$ that are relatively symmetric compared with the DNS data for which the p.d.f.s are negatively skewed. For both M1 and M2, the model significantly underpredicts regions of intense vorticity, and slightly underpredicts regions of intense straining, with the model showing good agreement with the DNS results at values of the p.d.f.s that are
$R$ that are relatively symmetric compared with the DNS data for which the p.d.f.s are negatively skewed. For both M1 and M2, the model significantly underpredicts regions of intense vorticity, and slightly underpredicts regions of intense straining, with the model showing good agreement with the DNS results at values of the p.d.f.s that are  ${\geq}O(10^{-2})$. For both
${\geq}O(10^{-2})$. For both  $Q$ and
$Q$ and  $R$ in figure 3, the model also captures well the trend of increased intermittency at higher
$R$ in figure 3, the model also captures well the trend of increased intermittency at higher  $\textit {Re}_\lambda$ shown from DNS1 and DNS2.
$\textit {Re}_\lambda$ shown from DNS1 and DNS2.
In view of these results, it is seen that while the ML-RDGF model predicts the components of the velocity gradients very accurately (as well as the alignments between the vorticity and strain-rate eigenvectors; see Johnson & Meneveau Reference Johnson and Meneveau2017), it does not predict the invariants of the velocity gradients accurately when compared with the DNS results, at least not for the  $\textit {Re}_\lambda$ considered here. This could in turn lead to inaccuracies in the scalar gradient model, above and beyond any arising from the closure approximations for the scalar gradient diffusion term. These results point to the need for further refinements in the ML-RDGF model.
$\textit {Re}_\lambda$ considered here. This could in turn lead to inaccuracies in the scalar gradient model, above and beyond any arising from the closure approximations for the scalar gradient diffusion term. These results point to the need for further refinements in the ML-RDGF model.
4.2. Scalar gradients
We now turn to consider the predictions from our new model for the scalar gradients. In figure 4, we plot the p.d.f.s of  $Q_b/Q_{b,av}$ (where
$Q_b/Q_{b,av}$ (where  $Q_b\equiv \|\boldsymbol {b}\|^2$), which is proportional to the scalar dissipation rate
$Q_b\equiv \|\boldsymbol {b}\|^2$), which is proportional to the scalar dissipation rate  $\epsilon _\phi \equiv \kappa \|\boldsymbol {b}\|^2$, as well as the p.d.f. of
$\epsilon _\phi \equiv \kappa \|\boldsymbol {b}\|^2$, as well as the p.d.f. of  $b_1$, the scalar gradient component in one of the (arbitrary, due to isotropy) directions. Concerning the p.d.f. of
$b_1$, the scalar gradient component in one of the (arbitrary, due to isotropy) directions. Concerning the p.d.f. of  $Q_b/Q_{b,av}$, the results show that while the model is in good qualitative agreement with the DNS data, capturing the slowly decaying tail of the p.d.f., it significantly underpredicts the values of the p.d.f. The model predictions for the p.d.f. of
$Q_b/Q_{b,av}$, the results show that while the model is in good qualitative agreement with the DNS data, capturing the slowly decaying tail of the p.d.f., it significantly underpredicts the values of the p.d.f. The model predictions for the p.d.f. of  $b_1$ are also in significant error, underpredicting small to intermediate values of
$b_1$ are also in significant error, underpredicting small to intermediate values of  $b_1/b_{1,rms}$, and significantly overpredicting large values of
$b_1/b_{1,rms}$, and significantly overpredicting large values of  $b_1/b_{1,rms}$, such that the overall shape of the p.d.f. is not captured well by the model.
$b_1/b_{1,rms}$, such that the overall shape of the p.d.f. is not captured well by the model.

Figure 4. The p.d.f.s of (a)  $Q_b/Q_{b,av}$ and (b)
$Q_b/Q_{b,av}$ and (b)  $b_1/b_{1,rms}$. The results from the model are obtained with the (uncorrected) model coefficient
$b_1/b_{1,rms}$. The results from the model are obtained with the (uncorrected) model coefficient  $\alpha _\mathcal {B}$ specified by (2.45).
$\alpha _\mathcal {B}$ specified by (2.45).
An investigation into the cause of these significant underpredictions revealed that the problem is due to the model generating extremely large values of  $\|\boldsymbol {\mathcal {B}}(t)\|^2$. An example of the time series of
$\|\boldsymbol {\mathcal {B}}(t)\|^2$. An example of the time series of  $\|\boldsymbol {\mathcal {B}}(t)\|^2/\langle \|\boldsymbol {\mathcal {B}}(t)\|^2\rangle$ generated by the model at
$\|\boldsymbol {\mathcal {B}}(t)\|^2/\langle \|\boldsymbol {\mathcal {B}}(t)\|^2\rangle$ generated by the model at  $\textit {Re}_\lambda =100$ is shown in figure 5, together with the time series of
$\textit {Re}_\lambda =100$ is shown in figure 5, together with the time series of  $\|\boldsymbol {\mathcal {S}}(t)\|^2/\langle \|\boldsymbol {\mathcal {S}}(t)\|^2\rangle$ for comparison. Although the signal
$\|\boldsymbol {\mathcal {S}}(t)\|^2/\langle \|\boldsymbol {\mathcal {S}}(t)\|^2\rangle$ for comparison. Although the signal  $\|\boldsymbol {\mathcal {S}}(t)\|^2$ exhibits significant fluctuations about the mean,
$\|\boldsymbol {\mathcal {S}}(t)\|^2$ exhibits significant fluctuations about the mean,  $\|\boldsymbol {\mathcal {B}}(t)\|^2$ exhibits infrequent but enormous fluctuations about the mean, which only get stronger as
$\|\boldsymbol {\mathcal {B}}(t)\|^2$ exhibits infrequent but enormous fluctuations about the mean, which only get stronger as  $\textit {Re}_\lambda$ is increased. Although
$\textit {Re}_\lambda$ is increased. Although  $\|\boldsymbol {\mathcal {B}}(t)\|^2$ would be expected to be more intermittent than
$\|\boldsymbol {\mathcal {B}}(t)\|^2$ would be expected to be more intermittent than  $\|\boldsymbol {\mathcal {S}}(t)\|^2$, one would not anticipate intermittent fluctuations in
$\|\boldsymbol {\mathcal {S}}(t)\|^2$, one would not anticipate intermittent fluctuations in  $\|\boldsymbol {\mathcal {B}}(t)\|^2$ as large as these, nor are they manifested in the DNS data, therefore they seem to indicate an issue with the model. The integral of the p.d.f. of
$\|\boldsymbol {\mathcal {B}}(t)\|^2$ as large as these, nor are they manifested in the DNS data, therefore they seem to indicate an issue with the model. The integral of the p.d.f. of  $Q_b$ over its sample space is 1, so because the model vastly overpredicts the probability of extremely large values of
$Q_b$ over its sample space is 1, so because the model vastly overpredicts the probability of extremely large values of  $\|\boldsymbol {\mathcal {B}}(t)\|^2$, it underpredicts the probability of values in the sample space range shown in figure 4.
$\|\boldsymbol {\mathcal {B}}(t)\|^2$, it underpredicts the probability of values in the sample space range shown in figure 4.

Figure 5. Time series of (a)  $\|\boldsymbol {\mathcal {B}}(t)\|^2$ and (b)
$\|\boldsymbol {\mathcal {B}}(t)\|^2$ and (b)  $\|\boldsymbol {\mathcal {S}}(t)\|^2$, normalized by their mean values, generated from the model with
$\|\boldsymbol {\mathcal {S}}(t)\|^2$, normalized by their mean values, generated from the model with  $\textit {Re}_\lambda =100$ and the (uncorrected) coefficient
$\textit {Re}_\lambda =100$ and the (uncorrected) coefficient  $\alpha _\mathcal {B}$ specified by (2.45).
$\alpha _\mathcal {B}$ specified by (2.45).
That the model vastly overpredicts the probability of extremely large values of  $\|\boldsymbol {\mathcal {B}}(t)\|^2/\langle \|\boldsymbol {\mathcal {B}}(t)\|^2\rangle$ must be due to deficiencies in the closure for
$\|\boldsymbol {\mathcal {B}}(t)\|^2/\langle \|\boldsymbol {\mathcal {B}}(t)\|^2\rangle$ must be due to deficiencies in the closure for  $\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$. In particular, the values of
$\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$. In particular, the values of  $\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ predicted by the closure approximation when
$\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ predicted by the closure approximation when  $\|\boldsymbol {\mathcal {B}}\|$ is large are too small to sufficiently counteract the scalar production term (although apparently, they are large enough to prevent singularities in the model, since simulations of the model do not blow up). A relatively simple modification to the model to address this deficiency is to modify its specification of the coefficient
$\|\boldsymbol {\mathcal {B}}\|$ is large are too small to sufficiently counteract the scalar production term (although apparently, they are large enough to prevent singularities in the model, since simulations of the model do not blow up). A relatively simple modification to the model to address this deficiency is to modify its specification of the coefficient  $\alpha _\mathcal {B}$ in (2.45) so that it includes information on the locally averaged scalar production, rather than simply the global mean value. This is achieved by replacing (2.45) with
$\alpha _\mathcal {B}$ in (2.45) so that it includes information on the locally averaged scalar production, rather than simply the global mean value. This is achieved by replacing (2.45) with
 \begin{equation} \alpha_\mathcal{B}(t)= \left.\tau_\eta\int^t_{t-\tau_1} \boldsymbol{\mathcal{S}}(t')\boldsymbol{:}\boldsymbol{\mathcal{B}}(t')\, \boldsymbol{\mathcal{B}}(t')\,{\rm d}t'\right/\int^t_{t-\tau_1} \|\boldsymbol{\mathcal{B}}(t')\|^2\,{\rm d}t',\end{equation}
\begin{equation} \alpha_\mathcal{B}(t)= \left.\tau_\eta\int^t_{t-\tau_1} \boldsymbol{\mathcal{S}}(t')\boldsymbol{:}\boldsymbol{\mathcal{B}}(t')\, \boldsymbol{\mathcal{B}}(t')\,{\rm d}t'\right/\int^t_{t-\tau_1} \|\boldsymbol{\mathcal{B}}(t')\|^2\,{\rm d}t',\end{equation}
which can be computed when solving the model since it depends on only  $\boldsymbol {\mathcal {S}}$ and
$\boldsymbol {\mathcal {S}}$ and  $\boldsymbol {\mathcal {B}}$ at previous times, which are known. With this, the global average involved in (2.45) is replaced with a local time average over the trajectory history of the particle. The time integral is chosen to span
$\boldsymbol {\mathcal {B}}$ at previous times, which are known. With this, the global average involved in (2.45) is replaced with a local time average over the trajectory history of the particle. The time integral is chosen to span  $[t-\tau _1,t]$ in view of the fact that
$[t-\tau _1,t]$ in view of the fact that  $\boldsymbol {\mathcal {S}}\boldsymbol {:}\boldsymbol {\mathcal {B}}\boldsymbol {\mathcal {B}}$ and
$\boldsymbol {\mathcal {S}}\boldsymbol {:}\boldsymbol {\mathcal {B}}\boldsymbol {\mathcal {B}}$ and  $\|\boldsymbol {\mathcal {B}}\|^2$ have time scales of the order of the integral time scale, which in the ML-RDGF model is specified by
$\|\boldsymbol {\mathcal {B}}\|^2$ have time scales of the order of the integral time scale, which in the ML-RDGF model is specified by  $\tau _1$.
$\tau _1$.
The advantage of using (4.1) is that the coefficient  $\delta _\mathcal {B}$ in (2.48) will then depend upon the local scalar gradient dynamics, and in regions where the production of
$\delta _\mathcal {B}$ in (2.48) will then depend upon the local scalar gradient dynamics, and in regions where the production of  $\|\boldsymbol {\mathcal {B}}\|^2$ is large,
$\|\boldsymbol {\mathcal {B}}\|^2$ is large,  $\delta _\mathcal {B}$ will also be large relative to its value in regions where the production of
$\delta _\mathcal {B}$ will also be large relative to its value in regions where the production of  $\|\boldsymbol {\mathcal {B}}\|^2$ is small. In other words, using (4.1) introduces nonlinearity into the closure for
$\|\boldsymbol {\mathcal {B}}\|^2$ is small. In other words, using (4.1) introduces nonlinearity into the closure for  $\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ with respect to its dependence on
$\kappa \langle \nabla ^2\boldsymbol{B}\rangle _{\boldsymbol {\mathcal {A}},\boldsymbol {\mathcal {B}}}$ with respect to its dependence on  $\boldsymbol {\mathcal {B}}$, and this may help to oppose the extremely large fluctuations predicted by the original form of the model. In practice, since (4.1) requires time history information, the model is solved for
$\boldsymbol {\mathcal {B}}$, and this may help to oppose the extremely large fluctuations predicted by the original form of the model. In practice, since (4.1) requires time history information, the model is solved for  $t\leqslant \tau _1$ using (2.45), and then for
$t\leqslant \tau _1$ using (2.45), and then for  $t>\tau _1$, (4.1) is used.
$t>\tau _1$, (4.1) is used.
Figure 6 shows once again the p.d.f.s of  $Q_b$ and
$Q_b$ and  $b_1$, but this time using (4.1) instead of (2.45) to specify
$b_1$, but this time using (4.1) instead of (2.45) to specify  $\alpha _\mathcal {B}$ in the model. Comparing the results to those in figure 4, it can be seen that the new specification of
$\alpha _\mathcal {B}$ in the model. Comparing the results to those in figure 4, it can be seen that the new specification of  $\alpha _\mathcal {B}$ dramatically improves the predictions from the model, being now in excellent agreement with the DNS data. The results also show the impact of
$\alpha _\mathcal {B}$ dramatically improves the predictions from the model, being now in excellent agreement with the DNS data. The results also show the impact of  $\textit {Re}_\lambda$ on
$\textit {Re}_\lambda$ on  $Q_b$ as predicted by the model, with the probability of intermediate values of
$Q_b$ as predicted by the model, with the probability of intermediate values of  $Q_b/Q_{b,av}$ and
$Q_b/Q_{b,av}$ and  $b_1/b_{1,rms}$ predicted to decrease as
$b_1/b_{1,rms}$ predicted to decrease as  $\textit {Re}_\lambda$ increases, while the probability of large
$\textit {Re}_\lambda$ increases, while the probability of large  $Q_b/Q_{b,av}$ and
$Q_b/Q_{b,av}$ and  $b_1/b_{1,rms}$ increases as
$b_1/b_{1,rms}$ increases as  $\textit {Re}_\lambda$ increases. The dependence on
$\textit {Re}_\lambda$ increases. The dependence on  $\textit {Re}_\lambda$ of the p.d.f.s predicted by the model is consistent with the trend in DNS results in figure 6 (or refer to figure 4 for a clearer comparison of DNS1 and DNS2 curves). However, further tests of the model revealed that when
$\textit {Re}_\lambda$ of the p.d.f.s predicted by the model is consistent with the trend in DNS results in figure 6 (or refer to figure 4 for a clearer comparison of DNS1 and DNS2 curves). However, further tests of the model revealed that when  $\textit {Re}_\lambda$ is increased much beyond
$\textit {Re}_\lambda$ is increased much beyond  $\textit {Re}_\lambda =500$, the predictions of the model become unrealistic, with extremely large values of the scalar gradient occurring in the model, and the model can even blow up. Therefore, although the use of (4.1) dramatically improves the performance of the model over the range of
$\textit {Re}_\lambda =500$, the predictions of the model become unrealistic, with extremely large values of the scalar gradient occurring in the model, and the model can even blow up. Therefore, although the use of (4.1) dramatically improves the performance of the model over the range of  $\textit {Re}_\lambda$ considered, it is not sufficient to guarantee that the model makes reasonable predictions for arbitrarily large
$\textit {Re}_\lambda$ considered, it is not sufficient to guarantee that the model makes reasonable predictions for arbitrarily large  $\textit {Re}_\lambda$. An investigation into the causes of the failure of the model at high
$\textit {Re}_\lambda$. An investigation into the causes of the failure of the model at high  $\textit {Re}_\lambda$ and possible remedies for this are left to future work.
$\textit {Re}_\lambda$ and possible remedies for this are left to future work.




In figure 7(a), we show the p.d.f. of the scalar gradient production  $R_b\equiv \boldsymbol{\mathsf{a}}\boldsymbol {:}\boldsymbol {bb}$. The results show that the model predictions are in good agreement with the DNS data, with some underpredictions for the largest fluctuations. The model captures the strong negative skewness of the p.d.f. (shown in DNS1 and DNS2) that is associated with the predominance of scalar gradient production over destruction. The model also predicts that the largest fluctuations in
$R_b\equiv \boldsymbol{\mathsf{a}}\boldsymbol {:}\boldsymbol {bb}$. The results show that the model predictions are in good agreement with the DNS data, with some underpredictions for the largest fluctuations. The model captures the strong negative skewness of the p.d.f. (shown in DNS1 and DNS2) that is associated with the predominance of scalar gradient production over destruction. The model also predicts that the largest fluctuations in  $R_b$ become more probable as
$R_b$ become more probable as  $\textit {Re}_\lambda$ is increased due to intermittency in the flow. In figure 7(b), we show the p.d.f. of the inner product between the unit vector
$\textit {Re}_\lambda$ is increased due to intermittency in the flow. In figure 7(b), we show the p.d.f. of the inner product between the unit vector  $\boldsymbol {e}_b\equiv \boldsymbol {b}/\|\boldsymbol {b}\|$ and the eigenvectors
$\boldsymbol {e}_b\equiv \boldsymbol {b}/\|\boldsymbol {b}\|$ and the eigenvectors  $\boldsymbol {e}_i$ (corresponding to the ordered eigenvalues) of
$\boldsymbol {e}_i$ (corresponding to the ordered eigenvalues) of  $\boldsymbol {\mathcal {S}}$. The model predicts these non-trivial alignments very well, capturing the strong preferential alignment with the compressional eigendirection
$\boldsymbol {\mathcal {S}}$. The model predicts these non-trivial alignments very well, capturing the strong preferential alignment with the compressional eigendirection  $\boldsymbol {e}_3$, and misalignment with the intermediate eigendirection
$\boldsymbol {e}_3$, and misalignment with the intermediate eigendirection  $\boldsymbol {e}_2$ and extensional eigendirection
$\boldsymbol {e}_2$ and extensional eigendirection  $\boldsymbol {e}_1$. However, the model predicts a misalignment with
$\boldsymbol {e}_1$. However, the model predicts a misalignment with  $\boldsymbol {e}_1$ that is a little too strong, and a misalignment with
$\boldsymbol {e}_1$ that is a little too strong, and a misalignment with  $\boldsymbol {e}_2$ that is a little too weak. Only the results for
$\boldsymbol {e}_2$ that is a little too weak. Only the results for  $\textit {Re}_\lambda =100$ are shown, as the results from both the DNS and model exhibit negligible
$\textit {Re}_\lambda =100$ are shown, as the results from both the DNS and model exhibit negligible  $\textit {Re}_\lambda$ dependence. The current model predictions for these alignment p.d.f.s are in much better agreement with the DNS data than those of the model of Martín et al. (Reference Martín, Dopazo and Valiño2005), which uses a much more simplistic closure approximation for the scalar diffusion term.
$\textit {Re}_\lambda$ dependence. The current model predictions for these alignment p.d.f.s are in much better agreement with the DNS data than those of the model of Martín et al. (Reference Martín, Dopazo and Valiño2005), which uses a much more simplistic closure approximation for the scalar diffusion term.

Figure 7. The p.d.f.s of (a)  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ and (b) the inner product between the unit vector
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ and (b) the inner product between the unit vector  $\boldsymbol {e}_b\equiv \boldsymbol {b}/\|\boldsymbol {b}\|$ and the eigenvectors
$\boldsymbol {e}_b\equiv \boldsymbol {b}/\|\boldsymbol {b}\|$ and the eigenvectors  $\boldsymbol {e}_i$ of
$\boldsymbol {e}_i$ of  $\boldsymbol {\mathcal {S}}$.
$\boldsymbol {\mathcal {S}}$.
4.3. Joint p.d.f.s of velocity and scalar gradients
We now turn to consider the relationship between the velocity and scalar gradients predicted by the model. In figure 8, we show the joint p.d.f.s of the velocity gradient invariant  $Q/\tilde {Q}_{av}$ and scalar invariant
$Q/\tilde {Q}_{av}$ and scalar invariant  $Q_b/Q_{b,av}$ from the DNS and model. For both M1 and M2 from our model predictions, there is an excellent qualitative agreement with the DNS data, with the model capturing the elongation of the p.d.f. (note, however, that the appearance of the elongation is somewhat exaggerated due to the different horizontal and vertical axis ranges) along the horizontal axis toward regions of large
$Q_b/Q_{b,av}$ from the DNS and model. For both M1 and M2 from our model predictions, there is an excellent qualitative agreement with the DNS data, with the model capturing the elongation of the p.d.f. (note, however, that the appearance of the elongation is somewhat exaggerated due to the different horizontal and vertical axis ranges) along the horizontal axis toward regions of large  $Q_b/Q_{b,av}$, indicating that large fluctuations in the scalar gradients are much more probable than they are for the velocity gradients. The model also captures the exponential-like behaviour of the isocontours of the p.d.f., whose shape indicates that large values of
$Q_b/Q_{b,av}$, indicating that large fluctuations in the scalar gradients are much more probable than they are for the velocity gradients. The model also captures the exponential-like behaviour of the isocontours of the p.d.f., whose shape indicates that large values of  $Q_b/Q_{b,av}$ tend to occur in regions where
$Q_b/Q_{b,av}$ tend to occur in regions where  $Q/\tilde {Q}_{av}$ is small, and vice versa. The quantitative errors are mainly associated with the variation of the joint p.d.f. along the
$Q/\tilde {Q}_{av}$ is small, and vice versa. The quantitative errors are mainly associated with the variation of the joint p.d.f. along the  $Q/\tilde {Q}_{av}$ axis, which can be understood in terms of the ML-RDGF model's underprediction of large fluctuations of
$Q/\tilde {Q}_{av}$ axis, which can be understood in terms of the ML-RDGF model's underprediction of large fluctuations of 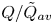 $Q/\tilde {Q}_{av}$ at
$Q/\tilde {Q}_{av}$ at  $\textit {Re}_\lambda =100$ and
$\textit {Re}_\lambda =100$ and  $250$, as already observed when considering the p.d.f. of
$250$, as already observed when considering the p.d.f. of  $Q/\tilde {Q}_{av}$ in figure 3. Comparing the results from M1 and M2 shows that the model predicts that as
$Q/\tilde {Q}_{av}$ in figure 3. Comparing the results from M1 and M2 shows that the model predicts that as  $\textit {Re}_\lambda$ is increased, the shape of the joint p.d.f. is preserved, which is consistent with DNS results. However, the model predicts a more stretched shape of the joint p.d.f.s along the two axes, corresponding to lower predicted probability of regions with comparable values of
$\textit {Re}_\lambda$ is increased, the shape of the joint p.d.f. is preserved, which is consistent with DNS results. However, the model predicts a more stretched shape of the joint p.d.f.s along the two axes, corresponding to lower predicted probability of regions with comparable values of  $Q/\tilde {Q}_{av}$ and
$Q/\tilde {Q}_{av}$ and  $Q_b/Q_{b,av}$.
$Q_b/Q_{b,av}$.

Figure 8. Logarithms of joint p.d.f.s of  $Q/\tilde {Q}_{av}$ and
$Q/\tilde {Q}_{av}$ and  $Q_b/Q_{b,av}$ from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
$Q_b/Q_{b,av}$ from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
In figure 9, we show the joint p.d.f.s of the velocity gradient invariant  $Q/\tilde {Q}_{av}$ and scalar production invariant
$Q/\tilde {Q}_{av}$ and scalar production invariant  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ from the DNS and model. These joint p.d.f.s provide insights into how straining and vortical regions of the flow might contribute differently to the scalar gradient production. The model reproduces accurately the qualitative behaviour of the p.d.f. seen in the DNS data, including the elongation of the p.d.f. along the
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ from the DNS and model. These joint p.d.f.s provide insights into how straining and vortical regions of the flow might contribute differently to the scalar gradient production. The model reproduces accurately the qualitative behaviour of the p.d.f. seen in the DNS data, including the elongation of the p.d.f. along the  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}<0$ direction, associated with the predominance of scalar gradient production over destruction. The results also show that events with strong scalar gradient production are more probable in regions where
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}<0$ direction, associated with the predominance of scalar gradient production over destruction. The results also show that events with strong scalar gradient production are more probable in regions where  $Q/\tilde {Q}_{av}<0$, despite the fact that
$Q/\tilde {Q}_{av}<0$, despite the fact that  $Q/\tilde {Q}_{av}$ itself has a positively skewed p.d.f. This is because the antisymmetric part of the velocity gradient, and therefore the vorticity, does not contribute directly to the invariant
$Q/\tilde {Q}_{av}$ itself has a positively skewed p.d.f. This is because the antisymmetric part of the velocity gradient, and therefore the vorticity, does not contribute directly to the invariant  $R_b$, but only contributes indirectly through its impact on the local alignment of
$R_b$, but only contributes indirectly through its impact on the local alignment of  $\boldsymbol {\mathcal {B}}(t)$ with
$\boldsymbol {\mathcal {B}}(t)$ with  $\boldsymbol {\mathcal {S}}(t)$, whereas the strain rate affects
$\boldsymbol {\mathcal {S}}(t)$, whereas the strain rate affects  $R_b$ directly. The model underpredicts the probability of the largest fluctuations, which again is principally due to the ML-RDGF model underpredicting the intermittency of
$R_b$ directly. The model underpredicts the probability of the largest fluctuations, which again is principally due to the ML-RDGF model underpredicting the intermittency of  $Q/\tilde {Q}_{av}$. Comparing the results from M1 and M2 shows that the model predicts that as
$Q/\tilde {Q}_{av}$. Comparing the results from M1 and M2 shows that the model predicts that as  $\textit {Re}_\lambda$ is increased, the shape of the joint p.d.f. is largely preserved, except for being more stretched along the axes due to the increased intermittency predicted by the model. The model does tend to predict, however, that the overall probability of the system being in the quadrant
$\textit {Re}_\lambda$ is increased, the shape of the joint p.d.f. is largely preserved, except for being more stretched along the axes due to the increased intermittency predicted by the model. The model does tend to predict, however, that the overall probability of the system being in the quadrant  $Q<0,R_b>0$ reduces as
$Q<0,R_b>0$ reduces as  $\textit {Re}_\lambda$ increases. Future comparisons with DNS at higher
$\textit {Re}_\lambda$ increases. Future comparisons with DNS at higher  $\textit {Re}_\lambda$ will be needed to assess the accuracy of this prediction. It is possible that this is a defect in the model that is in some way related to the failure of the model at higher
$\textit {Re}_\lambda$ will be needed to assess the accuracy of this prediction. It is possible that this is a defect in the model that is in some way related to the failure of the model at higher  $\textit {Re}_\lambda$.
$\textit {Re}_\lambda$.

Figure 9. Logarithms of joint p.d.f.s of  $Q/\tilde {Q}_{av}$ and
$Q/\tilde {Q}_{av}$ and  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
Finally, in figure 10, we show the joint p.d.f.s of the scalar gradient invariant  $Q_b/Q_{b,av}$ and scalar production invariant
$Q_b/Q_{b,av}$ and scalar production invariant  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$. The predictions from the model for M1 and M2 are in very good agreement with the DNS, both qualitatively and quantitatively, with only small deviations. By comparing the results for M1 and M2, the model is shown to predict that as
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$. The predictions from the model for M1 and M2 are in very good agreement with the DNS, both qualitatively and quantitatively, with only small deviations. By comparing the results for M1 and M2, the model is shown to predict that as  $\textit {Re}_\lambda$ is increased, the shape of the joint p.d.f.s of
$\textit {Re}_\lambda$ is increased, the shape of the joint p.d.f.s of  $Q_b/Q_{b,av}$ and
$Q_b/Q_{b,av}$ and  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ is preserved, except for being more stretched along the
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ is preserved, except for being more stretched along the  $Q_b/Q_{b,av}$ axis due to the increased intermittency in
$Q_b/Q_{b,av}$ axis due to the increased intermittency in  $Q_b/Q_{b,av}$.
$Q_b/Q_{b,av}$.

Figure 10. Logarithms of joint p.d.f.s of  $Q_b/Q_{b,av}$ and
$Q_b/Q_{b,av}$ and  $R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
$R_b/\tilde {Q}_{av}^{1/2}Q_{b,av}$ from (a) DNS1, (b) DNS2, (c) M1, and (d) M2. Colours indicate the values of the decimal logarithm of the p.d.f.
5. Conclusions
A Lagrangian model for passive scalar gradients in isotropic turbulence has been developed, with the scalar gradient diffusion term closed using the RDGF approach, which has recently been applied very successfully to close the equation for the fluid velocity gradients along fluid particle trajectories. This closure yields a diffusion term that is nonlinear in the velocity gradients, but linear in the scalar gradients, and comparisons of the statistics generated by the closed model with DNS data revealed large errors. An investigation revealed that these large errors were due to the scalar gradient model generating erroneously large fluctuations, possibly due to the diffusion term being linear in the scalar gradient under the RDGF closure. This defect was addressed by incorporating into the closure approximation information regarding the scalar gradient production along the local trajectory history of the particle. With this modification, the closed form of the diffusion term is now a nonlinear functional of the scalar gradients, and the resulting model is in very good agreement with the DNS data.
Since the ML-RDGF model of Johnson & Meneveau (Reference Johnson and Meneveau2017) is used to specify the velocity gradients in the scalar gradient equation, we begin by comparing its predictions with DNS data. In agreement with the results of Johnson & Meneveau (Reference Johnson and Meneveau2017), the model predicts very accurately the longitudinal and transverse components of the velocity gradients, and reproduces the key features of the joint p.d.f. of  $Q$ and
$Q$ and  $R$, the second and third invariants of the velocity gradient tensor. However, a more quantitative test of the model predictions for the p.d.f.s of
$R$, the second and third invariants of the velocity gradient tensor. However, a more quantitative test of the model predictions for the p.d.f.s of  $Q$ and
$Q$ and  $R$ individually against DNS data revealed that at least for
$R$ individually against DNS data revealed that at least for  $\textit {Re}_\lambda =100$ and
$\textit {Re}_\lambda =100$ and  $250$, the ML-RDGF significantly underpredicts the probability of large positive values of
$250$, the ML-RDGF significantly underpredicts the probability of large positive values of  $Q$ and large negative values of
$Q$ and large negative values of  $R$, which are associated primarily with regions of intense enstrophy and its production, respectively. These inaccuracies could then impact the accuracy of the scalar gradient model, and highlight the need for further improvements in the ML-RDGF model (although the model may predict the statistics of
$R$, which are associated primarily with regions of intense enstrophy and its production, respectively. These inaccuracies could then impact the accuracy of the scalar gradient model, and highlight the need for further improvements in the ML-RDGF model (although the model may predict the statistics of  $Q$ and
$Q$ and  $R$ more accurately at higher
$R$ more accurately at higher  $\textit {Re}_\lambda$).
$\textit {Re}_\lambda$).
Comparisons between the scalar gradient model and DNS data for  $\textit {Re}_\lambda =100$ and
$\textit {Re}_\lambda =100$ and  $250$ showed very good agreement. In particular, the model predicts accurately the squared magnitudes of the scalar gradients (which are proportional to the scalar dissipation rates), as well as the individual components of the scalar gradients. The model also captures well the p.d.f. of the scalar production, including its strong negative skewness that is associated with the predominance of scalar gradient destruction, but slightly underpredicts the most extreme fluctuations of the scalar gradient production and destruction. Next, the p.d.f.s of the inner product between the scalar gradient direction and the strain-rate eigendirections were considered, which provide insights into the non-trivial statistical geometry of the passive scalar and velocity gradient dynamics. The model is in excellent agreement with the DNS data regarding the strong preferential alignment between the scalar gradient and the compressional eigendirection. However, the model predicts a misalignment with the extensional eigendirection that is a little too strong, and a misalignment with the intermediate eigendirection that is a little too weak.
$250$ showed very good agreement. In particular, the model predicts accurately the squared magnitudes of the scalar gradients (which are proportional to the scalar dissipation rates), as well as the individual components of the scalar gradients. The model also captures well the p.d.f. of the scalar production, including its strong negative skewness that is associated with the predominance of scalar gradient destruction, but slightly underpredicts the most extreme fluctuations of the scalar gradient production and destruction. Next, the p.d.f.s of the inner product between the scalar gradient direction and the strain-rate eigendirections were considered, which provide insights into the non-trivial statistical geometry of the passive scalar and velocity gradient dynamics. The model is in excellent agreement with the DNS data regarding the strong preferential alignment between the scalar gradient and the compressional eigendirection. However, the model predicts a misalignment with the extensional eigendirection that is a little too strong, and a misalignment with the intermediate eigendirection that is a little too weak.
The ability of the model to capture the statistical relationship between the velocity and scalar dynamics was considered next, by considering various joint p.d.f.s of the velocity and scalar gradient tensors. The results showed excellent qualitative agreement with the DNS data, with some quantitative errors that seem to be rooted in the ML-RDGF model underpredicting the probability of extreme fluctuations in the  $Q$ and
$Q$ and  $R$ invariants. The joint p.d.f. of the squared magnitude of the scalar gradient with the scalar gradient production term predicted by the model was in excellent qualitative as well as quantitative agreement with the DNS.
$R$ invariants. The joint p.d.f. of the squared magnitude of the scalar gradient with the scalar gradient production term predicted by the model was in excellent qualitative as well as quantitative agreement with the DNS.
The predictions of the model at  $\textit {Re}_\lambda$ greater than that of the DNS were also considered, and the predictions are reasonable up to
$\textit {Re}_\lambda$ greater than that of the DNS were also considered, and the predictions are reasonable up to  $\textit {Re}_\lambda \approx 500$. However, beyond this, the model breaks down and leads to extremely large scalar gradients that can even cause the numerical simulations of the model to blow up. Therefore, while the modification to the scalar gradient diffusion term that incorporates the scalar gradient production along the local trajectory history of the particle leads to excellent predictions from the model at lower
$\textit {Re}_\lambda \approx 500$. However, beyond this, the model breaks down and leads to extremely large scalar gradients that can even cause the numerical simulations of the model to blow up. Therefore, while the modification to the scalar gradient diffusion term that incorporates the scalar gradient production along the local trajectory history of the particle leads to excellent predictions from the model at lower  $\textit {Re}_\lambda$, it is not sufficient to prevent the model from generating extremely large fluctuations at high
$\textit {Re}_\lambda$, it is not sufficient to prevent the model from generating extremely large fluctuations at high  $\textit {Re}_\lambda$ where intermittency in the velocity gradients can lead to very large local scalar gradient production events. Therefore, as anticipated earlier, developing an accurate model for scalar gradients in turbulence is in some ways more complicated than that for velocity gradients, because scalar gradient dynamics lacks a mechanism similar to the pressure Hessian that controls the growth of the velocity gradients. For scalar gradients, the closure for the diffusion term is a delicate matter since this term alone is dynamically responsible for preventing finite-time singularities of the scalar gradients. A crucial point for future work is therefore to understand in more detail how the diffusion term regulates the growth of the scalar gradients, and developing a closure model that is sufficiently sophisticated to capture this.
$\textit {Re}_\lambda$ where intermittency in the velocity gradients can lead to very large local scalar gradient production events. Therefore, as anticipated earlier, developing an accurate model for scalar gradients in turbulence is in some ways more complicated than that for velocity gradients, because scalar gradient dynamics lacks a mechanism similar to the pressure Hessian that controls the growth of the velocity gradients. For scalar gradients, the closure for the diffusion term is a delicate matter since this term alone is dynamically responsible for preventing finite-time singularities of the scalar gradients. A crucial point for future work is therefore to understand in more detail how the diffusion term regulates the growth of the scalar gradients, and developing a closure model that is sufficiently sophisticated to capture this.
A simplifying approximation was introduced into the derivation of the model, namely (2.35). While the RDGF approach could in principle be used to derive the scalar gradient model without invoking this approximation, the derivation of the model and its resulting form will be considerably more complicated. It is important for future work, however, to assess the impact of this approximation on the model performance by testing it against the form of the model that is constructed without the use of this simplifying approximation.
Another aspect to be explored is the influence of the Schmidt number  $Sc$ on the scalar gradients. While the model does include a
$Sc$ on the scalar gradients. While the model does include a  $Sc$ dependence in the scalar gradient diffusion term, given that the model breaks down for
$Sc$ dependence in the scalar gradient diffusion term, given that the model breaks down for  $Sc=1$ when
$Sc=1$ when  $\textit {Re}_\lambda >500$, it is likely that the model will also break down for
$\textit {Re}_\lambda >500$, it is likely that the model will also break down for  $\textit {Re}_\lambda <500$ when
$\textit {Re}_\lambda <500$ when  $Sc$ becomes sufficiently large, since both regimes promote the intensification of the scalar gradients.
$Sc$ becomes sufficiently large, since both regimes promote the intensification of the scalar gradients.
Acknowledgements
This work used the Extreme Science and Engineering Discovery Environment (XSEDE), which is supported by NSF grant number ACI-1548562 (Towns et al. Reference Towns2014). Specifically, the Expanse cluster was used under allocation CTS170009.
Funding
A.D.B. and X.Z. acknowledge support through a National Science Foundation (NSF) CAREER award no. 2042346.
Declaration of interests
The authors report no conflict of interest.
Appendix A. Role of fluctuations on the p.d.f. of  $\boldsymbol{\mathsf{A}}$
$\boldsymbol{\mathsf{A}}$

Johnson & Meneveau (Reference Johnson and Meneveau2016) discuss models for  $\boldsymbol{\mathsf{A}}$ that are based on evolving equations for conditional averages, such as the RGFC model of Wilczek & Meneveau (Reference Wilczek and Meneveau2014), and state that the modelling approach involves splitting
$\boldsymbol{\mathsf{A}}$ that are based on evolving equations for conditional averages, such as the RGFC model of Wilczek & Meneveau (Reference Wilczek and Meneveau2014), and state that the modelling approach involves splitting  $D_t\boldsymbol{\mathsf{A}}$ into the conditional average
$D_t\boldsymbol{\mathsf{A}}$ into the conditional average  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ and the fluctuation
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ and the fluctuation  $D_t\boldsymbol{\mathsf{A}}'$, defined such that
$D_t\boldsymbol{\mathsf{A}}'$, defined such that
 \begin{equation} D_t\boldsymbol{\mathsf{A}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} +D_t\boldsymbol{\mathsf{A}}'.\end{equation}
\begin{equation} D_t\boldsymbol{\mathsf{A}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} +D_t\boldsymbol{\mathsf{A}}'.\end{equation}
They then say that while  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ is modelled using either the RGFC or RDGF closure,
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ is modelled using either the RGFC or RDGF closure,  $D_t\boldsymbol{\mathsf{A}}'$ (associated with the fluctuating pressure Hessian and viscous terms) is approximated as Gaussian white-noise. The Gaussian white-noise forcing term in the velocity gradient model of Johnson & Meneveau (Reference Johnson and Meneveau2016) is therefore interpreted as capturing not only the effect of random forcing imposed on the flow (analogous to forcing terms used in DNS of isotropic turbulence), but also the contribution from
$D_t\boldsymbol{\mathsf{A}}'$ (associated with the fluctuating pressure Hessian and viscous terms) is approximated as Gaussian white-noise. The Gaussian white-noise forcing term in the velocity gradient model of Johnson & Meneveau (Reference Johnson and Meneveau2016) is therefore interpreted as capturing not only the effect of random forcing imposed on the flow (analogous to forcing terms used in DNS of isotropic turbulence), but also the contribution from  $D_t\boldsymbol{\mathsf{A}}'$. Such an approximation for
$D_t\boldsymbol{\mathsf{A}}'$. Such an approximation for  $D_t\boldsymbol{\mathsf{A}}'$ would be very crude and would suggest a significant weakness in the modelling approach based on conditional averages. In the following, it will be argued, however, that such interpretation of how
$D_t\boldsymbol{\mathsf{A}}'$ would be very crude and would suggest a significant weakness in the modelling approach based on conditional averages. In the following, it will be argued, however, that such interpretation of how  $D_t\boldsymbol{\mathsf{A}}'$ is handled in these models need not be adopted, placing the models on a better foundation.
$D_t\boldsymbol{\mathsf{A}}'$ is handled in these models need not be adopted, placing the models on a better foundation.
Introducing the decomposition (A1) into the right-hand side of (2.3), we obtain
 \begin{align}
\partial_t\mathcal{P}&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}
(\mathcal{P}\left\langle
D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
) ={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle \langle
D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
+D_t \boldsymbol{\mathsf{A}}'\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
)\nonumber\\ &={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle
D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
+\mathcal{P} \langle D_t\boldsymbol{\mathsf{A}}'
\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}})\nonumber\\
&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle
D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
), \end{align}
\begin{align}
\partial_t\mathcal{P}&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}
(\mathcal{P}\left\langle
D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
) ={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle \langle
D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
+D_t \boldsymbol{\mathsf{A}}'\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
)\nonumber\\ &={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle
D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
+\mathcal{P} \langle D_t\boldsymbol{\mathsf{A}}'
\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}})\nonumber\\
&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle
D_t\boldsymbol{\mathsf{A}}\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
), \end{align}
where we have used  $\langle D_t\boldsymbol{\mathsf{A}}'\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} =\boldsymbol {0}$, which follows from (A1). Hence the fluctuations make no contribution to the p.d.f. of
$\langle D_t\boldsymbol{\mathsf{A}}'\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} =\boldsymbol {0}$, which follows from (A1). Hence the fluctuations make no contribution to the p.d.f. of  $\boldsymbol{\mathsf{A}}$ when the fluctuations are defined using the decomposition in (A1). This then suggests that the p.d.f. of
$\boldsymbol{\mathsf{A}}$ when the fluctuations are defined using the decomposition in (A1). This then suggests that the p.d.f. of  $\boldsymbol{\mathsf{A}}$ could be constructed exactly using only
$\boldsymbol{\mathsf{A}}$ could be constructed exactly using only  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ instead of having to use the full quantity
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ instead of having to use the full quantity  $D_t\boldsymbol{\mathsf{A}}$, thereby bypassing the need to model
$D_t\boldsymbol{\mathsf{A}}$, thereby bypassing the need to model  $D_t\boldsymbol{\mathsf{A}}'$. This conclusion agrees with the proof in § 2.1 that the p.d.f. of
$D_t\boldsymbol{\mathsf{A}}'$. This conclusion agrees with the proof in § 2.1 that the p.d.f. of  $\boldsymbol{\mathsf{A}}$ can be constructed exactly based on either
$\boldsymbol{\mathsf{A}}$ can be constructed exactly based on either  $D_t\boldsymbol{\mathsf{A}}$ or the characteristic variable
$D_t\boldsymbol{\mathsf{A}}$ or the characteristic variable  $d_t\boldsymbol {\mathcal {A}}$ that is defined by
$d_t\boldsymbol {\mathcal {A}}$ that is defined by  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$.
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$.
In view of this, we see that the approach to modelling the p.d.f. of  $\boldsymbol{\mathsf{A}}$ in terms of conditional averages does not require approximating
$\boldsymbol{\mathsf{A}}$ in terms of conditional averages does not require approximating  $D_t\boldsymbol{\mathsf{A}}'$ as being Gaussian white-noise. Instead, this modelling approach states that the p.d.f. of
$D_t\boldsymbol{\mathsf{A}}'$ as being Gaussian white-noise. Instead, this modelling approach states that the p.d.f. of  $\boldsymbol{\mathsf{A}}$ can be constructed exactly using an equation for
$\boldsymbol{\mathsf{A}}$ can be constructed exactly using an equation for  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ instead of
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ instead of  $D_t\boldsymbol{\mathsf{A}}$, circumventing the need to model
$D_t\boldsymbol{\mathsf{A}}$, circumventing the need to model  $D_t\boldsymbol{\mathsf{A}}'$ at all.
$D_t\boldsymbol{\mathsf{A}}'$ at all.
That the fluctuations do not need to be modelled in order to predict the p.d.f. of  $\boldsymbol{\mathsf{A}}$ may seem surprising. However, it is really just a consequence of the particular choice of decomposition in (A1), and it does not hold for arbitrary decompositions. For example, if instead a Reynolds averaging (i.e. unconditioned) decomposition is used, i.e.
$\boldsymbol{\mathsf{A}}$ may seem surprising. However, it is really just a consequence of the particular choice of decomposition in (A1), and it does not hold for arbitrary decompositions. For example, if instead a Reynolds averaging (i.e. unconditioned) decomposition is used, i.e.
 \begin{equation} D_t\boldsymbol{\mathsf{A}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle +D_t\boldsymbol{\mathsf{A}}',\end{equation}
\begin{equation} D_t\boldsymbol{\mathsf{A}}=\langle D_t\boldsymbol{\mathsf{A}}\rangle +D_t\boldsymbol{\mathsf{A}}',\end{equation}then we would have
 \begin{align}
\partial_t\mathcal{P}={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}
(\mathcal{P}\left\langle
D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
)&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle \langle D_t\boldsymbol{\mathsf{A}}\rangle+D_t\boldsymbol{\mathsf{A}}'
\rangle_{\boldsymbol{\mathsf{A}}= \boldsymbol{\mathsf{a}}})\nonumber\\
&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle D_t\boldsymbol{\mathsf{A}}\rangle +\mathcal{P} \langle
D_t\boldsymbol{\mathsf{A}}' \rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}). \end{align}
\begin{align}
\partial_t\mathcal{P}={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}
(\mathcal{P}\left\langle
D_t\boldsymbol{\mathsf{A}}\right\rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}
)&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle \langle D_t\boldsymbol{\mathsf{A}}\rangle+D_t\boldsymbol{\mathsf{A}}'
\rangle_{\boldsymbol{\mathsf{A}}= \boldsymbol{\mathsf{a}}})\nonumber\\
&={-}\boldsymbol{\nabla}_{\boldsymbol{\mathsf{a}}}\boldsymbol{\cdot}(\mathcal{P}
\langle D_t\boldsymbol{\mathsf{A}}\rangle +\mathcal{P} \langle
D_t\boldsymbol{\mathsf{A}}' \rangle_{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}). \end{align}
In this case, the contribution from the fluctuations does not vanish, precisely because the fluctuations have been defined relative to the Reynolds average  $\langle {\cdot }\rangle$, rather than the conditional average
$\langle {\cdot }\rangle$, rather than the conditional average  $\langle {\cdot }\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. While
$\langle {\cdot }\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$. While  $\langle D_t\boldsymbol{\mathsf{A}}' \rangle =\boldsymbol {0}$ due to (A3), it does not follow that
$\langle D_t\boldsymbol{\mathsf{A}}' \rangle =\boldsymbol {0}$ due to (A3), it does not follow that  $\langle D_t\boldsymbol{\mathsf{A}}' \rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} =\boldsymbol {0}$ when
$\langle D_t\boldsymbol{\mathsf{A}}' \rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}} =\boldsymbol {0}$ when  $D_t\boldsymbol{\mathsf{A}}'$ is defined via (A3).
$D_t\boldsymbol{\mathsf{A}}'$ is defined via (A3).
In summary, if we wish to model the p.d.f. of  $\boldsymbol{\mathsf{A}}$, then all we need is a model for
$\boldsymbol{\mathsf{A}}$, then all we need is a model for  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ and not the full quantity
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ and not the full quantity  $D_t\boldsymbol{\mathsf{A}}$, because the fluctuations
$D_t\boldsymbol{\mathsf{A}}$, because the fluctuations  $D_t\boldsymbol{\mathsf{A}}'=D_t\boldsymbol{\mathsf{A}}-\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ make no contribution to the evolution of the p.d.f. of
$D_t\boldsymbol{\mathsf{A}}'=D_t\boldsymbol{\mathsf{A}}-\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ make no contribution to the evolution of the p.d.f. of  $\boldsymbol{\mathsf{A}}$. Therefore, in contrast to the interpretation given in Johnson & Meneveau (Reference Johnson and Meneveau2016), we see that modelling the p.d.f. of
$\boldsymbol{\mathsf{A}}$. Therefore, in contrast to the interpretation given in Johnson & Meneveau (Reference Johnson and Meneveau2016), we see that modelling the p.d.f. of  $\boldsymbol{\mathsf{A}}$ in terms of conditional averages does not require approximating the fluctuating contribution
$\boldsymbol{\mathsf{A}}$ in terms of conditional averages does not require approximating the fluctuating contribution  $D_t\boldsymbol{\mathsf{A}}'$ (associated with the fluctuating pressure Hessian and viscous terms) as a Gaussian white-noise process (or using any other approximation). Instead, we see that the approach states that the p.d.f. of
$D_t\boldsymbol{\mathsf{A}}'$ (associated with the fluctuating pressure Hessian and viscous terms) as a Gaussian white-noise process (or using any other approximation). Instead, we see that the approach states that the p.d.f. of  $\boldsymbol{\mathsf{A}}$ can be constructed exactly using an equation for
$\boldsymbol{\mathsf{A}}$ can be constructed exactly using an equation for  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ instead of
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ instead of  $D_t\boldsymbol{\mathsf{A}}$, circumventing the need to model
$D_t\boldsymbol{\mathsf{A}}$, circumventing the need to model  $D_t\boldsymbol{\mathsf{A}}'$ at all. Viewed this way, the Gaussian white-noise term in the equation for
$D_t\boldsymbol{\mathsf{A}}'$ at all. Viewed this way, the Gaussian white-noise term in the equation for  $\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ used in both Wilczek & Meneveau (Reference Wilczek and Meneveau2014) and Johnson & Meneveau (Reference Johnson and Meneveau2016) can be understood to simply capture the effect of a Gaussian, white-in-time forcing on the flow, such as is often used to force the Navier–Stokes equation in DNS of stationary, isotropic turbulence.
$\langle D_t\boldsymbol{\mathsf{A}}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}}}$ used in both Wilczek & Meneveau (Reference Wilczek and Meneveau2014) and Johnson & Meneveau (Reference Johnson and Meneveau2016) can be understood to simply capture the effect of a Gaussian, white-in-time forcing on the flow, such as is often used to force the Navier–Stokes equation in DNS of stationary, isotropic turbulence.
Similar arguments can also be applied in the context of the current model for the p.d.f. of  $\boldsymbol{B}$. Namely, the p.d.f. of
$\boldsymbol{B}$. Namely, the p.d.f. of  $\boldsymbol{B}$ can be constructed exactly using an equation for
$\boldsymbol{B}$ can be constructed exactly using an equation for  $\langle D_t\boldsymbol{B}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\ \boldsymbol{B}=\boldsymbol {b}}$ instead of
$\langle D_t\boldsymbol{B}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\ \boldsymbol{B}=\boldsymbol {b}}$ instead of  $D_t\boldsymbol{B}$, circumventing the need to model
$D_t\boldsymbol{B}$, circumventing the need to model  $D_t\boldsymbol{B}'$ at all. Similarly, in our model for
$D_t\boldsymbol{B}'$ at all. Similarly, in our model for  $\langle D_t\boldsymbol{B}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\ \boldsymbol{B}=\boldsymbol {b}}$, the Gaussian white-noise term is simply a term representing the forcing of the scalar field.
$\langle D_t\boldsymbol{B}\rangle _{\boldsymbol{\mathsf{A}}=\boldsymbol{\mathsf{a}},\ \boldsymbol{B}=\boldsymbol {b}}$, the Gaussian white-noise term is simply a term representing the forcing of the scalar field.
Appendix B. Details of the nonlinear term $\boldsymbol {\mathcal {N}}_{\mathcal {A}}$

The Cartesian components of the nonlinear term  $\boldsymbol {\mathcal {N}}_{\mathcal {A}}\{\boldsymbol {\mathcal {A}},\tau,\tau _\eta \}$ appearing in (2.23) are
$\boldsymbol {\mathcal {N}}_{\mathcal {A}}\{\boldsymbol {\mathcal {A}},\tau,\tau _\eta \}$ appearing in (2.23) are
 \begin{equation} (\boldsymbol{\mathcal{N}}_{\mathcal{A}}\{\boldsymbol{\mathcal{A}},\tau,\tau_\eta\})_{ij} ={-}\left[\mathcal{A}_{ik} \mathcal{A}_{kj}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{A}^2})\right] - \left[\mathcal{G}_{ij}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{G}})\right] - \mathcal{V}_{ij}, \end{equation}
\begin{equation} (\boldsymbol{\mathcal{N}}_{\mathcal{A}}\{\boldsymbol{\mathcal{A}},\tau,\tau_\eta\})_{ij} ={-}\left[\mathcal{A}_{ik} \mathcal{A}_{kj}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{A}^2})\right] - \left[\mathcal{G}_{ij}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{G}})\right] - \mathcal{V}_{ij}, \end{equation}
where  $\mathcal {G}_{ij}$ is the deviatoric part of the pressure Hessian,
$\mathcal {G}_{ij}$ is the deviatoric part of the pressure Hessian,
 \begin{align} \mathcal{G}_{ij} &= \mathcal{D}_{mi}^{{-}1} \left[-\tfrac{2}{7}\left(\mathcal{S}_{mk} \mathcal{S}_{kn} - \tfrac{1}{3} \mathcal{S}_{kl} \mathcal{S}_{lk} \delta_{mn}\right) - \tfrac{2}{5}\left(\mathcal{R}_{mk} \mathcal{R}_{kn} - \tfrac{1}{3} \mathcal{R}_{kl} \mathcal{R}_{lk} \delta_{mn}\right)\right.\nonumber\\ &\quad \left. {}+ \tfrac{86}{1365}(\mathcal{S}_{mk} \mathcal{R}_{kn} - \mathcal{R}_{mk} \mathcal{S}_{kn})\right] \mathcal{D}_{nj}^{{-}1}, \end{align}
\begin{align} \mathcal{G}_{ij} &= \mathcal{D}_{mi}^{{-}1} \left[-\tfrac{2}{7}\left(\mathcal{S}_{mk} \mathcal{S}_{kn} - \tfrac{1}{3} \mathcal{S}_{kl} \mathcal{S}_{lk} \delta_{mn}\right) - \tfrac{2}{5}\left(\mathcal{R}_{mk} \mathcal{R}_{kn} - \tfrac{1}{3} \mathcal{R}_{kl} \mathcal{R}_{lk} \delta_{mn}\right)\right.\nonumber\\ &\quad \left. {}+ \tfrac{86}{1365}(\mathcal{S}_{mk} \mathcal{R}_{kn} - \mathcal{R}_{mk} \mathcal{S}_{kn})\right] \mathcal{D}_{nj}^{{-}1}, \end{align}
and  $\mathcal {V}_{ij}$ is the contribution from the viscous Laplacian,
$\mathcal {V}_{ij}$ is the contribution from the viscous Laplacian,
 \begin{equation} \mathcal{V}_{ij} = \frac{7}{6 \sqrt{15}}\,\frac{\mathcal{C}_{kk}}{3}\,\frac{\mathcal{K}}{\tau_\eta} \left(\mathcal{T}_{ij} \mathcal{C}_{kk}^{{-}1} + 2 \mathcal{T}_{ik} \mathcal{J}_{kj}^{{-}1} - \frac{4}{21}\,\mathcal{J}_{ik}^{{-}1} \mathcal{S}_{kj} - \frac{2}{21}\,\mathcal{J}_{kl}^{{-}1} \mathcal{S}_{kl} \delta_{ij}\right), \end{equation}
\begin{equation} \mathcal{V}_{ij} = \frac{7}{6 \sqrt{15}}\,\frac{\mathcal{C}_{kk}}{3}\,\frac{\mathcal{K}}{\tau_\eta} \left(\mathcal{T}_{ij} \mathcal{C}_{kk}^{{-}1} + 2 \mathcal{T}_{ik} \mathcal{J}_{kj}^{{-}1} - \frac{4}{21}\,\mathcal{J}_{ik}^{{-}1} \mathcal{S}_{kj} - \frac{2}{21}\,\mathcal{J}_{kl}^{{-}1} \mathcal{S}_{kl} \delta_{ij}\right), \end{equation}
where  $\mathcal {K}=-0.6$ is the velocity gradient skewness, and
$\mathcal {K}=-0.6$ is the velocity gradient skewness, and
 \begin{equation} \mathcal{S}_{ij} = \tfrac{1}{2}(\mathcal{A}_{ij} + \mathcal{A}_{ji}), \quad \mathcal{R}_{ij} = \tfrac{1}{2}(\mathcal{A}_{ij} - \mathcal{A}_{ji}), \quad \mathcal{T}_{ij} = \tfrac{23}{105} \mathcal{A}_{ij} + \tfrac{2}{105} \mathcal{A}_{ji}. \end{equation}
\begin{equation} \mathcal{S}_{ij} = \tfrac{1}{2}(\mathcal{A}_{ij} + \mathcal{A}_{ji}), \quad \mathcal{R}_{ij} = \tfrac{1}{2}(\mathcal{A}_{ij} - \mathcal{A}_{ji}), \quad \mathcal{T}_{ij} = \tfrac{23}{105} \mathcal{A}_{ij} + \tfrac{2}{105} \mathcal{A}_{ji}. \end{equation}The full form of (2.23) is therefore
 \begin{equation} {\rm d}\mathcal{A}_{ij} ={-}\left[ \left(\mathcal{A}_{ik} \mathcal{A}_{kj}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{A}^2}) \right) - \left(\mathcal{G}_{ij}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{G}}) \right) - \mathcal{V}_{ij} \right]{\rm d}t + \varSigma_{ijkl}\,{\rm d}W_{kl}, \end{equation}
\begin{equation} {\rm d}\mathcal{A}_{ij} ={-}\left[ \left(\mathcal{A}_{ik} \mathcal{A}_{kj}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{A}^2}) \right) - \left(\mathcal{G}_{ij}-\frac{\mathcal{C}_{ij}^{{-}1}}{\mathcal{C}_{kk}^{{-}1}}\, \mathrm{tr}(\boldsymbol{\mathcal{G}}) \right) - \mathcal{V}_{ij} \right]{\rm d}t + \varSigma_{ijkl}\,{\rm d}W_{kl}, \end{equation}
where the components of the diffusion tensor  $\varSigma _{ijkl}$ are given by
$\varSigma _{ijkl}$ are given by
 \begin{equation} \varSigma_{ijkl} ={-}\frac{1}{3}\,\sqrt{\frac{D_s}{5}}\,\delta_{ij} \delta_{kl} + \frac{1}{2} \left(\sqrt{\frac{D_s}{5}} + \sqrt{\frac{D_a}{3}}\right) \delta_{ik} \delta_{jl} + \frac{1}{2} \left(\sqrt{\frac{D_s}{5}} - \sqrt{\frac{D_a}{3}}\right) \delta_{il} \delta_{jk}. \end{equation}
\begin{equation} \varSigma_{ijkl} ={-}\frac{1}{3}\,\sqrt{\frac{D_s}{5}}\,\delta_{ij} \delta_{kl} + \frac{1}{2} \left(\sqrt{\frac{D_s}{5}} + \sqrt{\frac{D_a}{3}}\right) \delta_{ik} \delta_{jl} + \frac{1}{2} \left(\sqrt{\frac{D_s}{5}} - \sqrt{\frac{D_a}{3}}\right) \delta_{il} \delta_{jk}. \end{equation}






































 Open access
Open access