


I. INTRODUCTION
Offering greater efficiency, reduced costs, and new insights into current and predicted behaviour or trends,Footnote 1 the use of algorithms to make or support decisions is increasingly central to many areas of public and private life.Footnote 2 However, the use of algorithms is not new. An algorithm, as defined by the Oxford English Dictionary, is simply ‘[a] process or set of rules to be followed in calculations or other problem-solving operations, especially by a computer’.Footnote 3 An early example is the use of handwritten algorithms to count votes and determine a winner in the electoral process. What accounts for the increasing centrality of algorithms in contemporary society is their transformational potential. For example, advances in computational power mean that modern algorithms can execute complex tasks beyond human capability and speed, self-learn to improve performance, and conduct sophisticated analysis to predict likely future outcomes. Modern algorithms are fuelled by easily accessible large and/or diverse datasets that can be aggregated and processed efficiently (often labelled ‘big data’).Footnote 4 These algorithms exist in a complex, interdependent, global data ecosystem whereby algorithmically produced outputs can be used as new input data for other algorithmic processes.Footnote 5
The interaction and interdependence of algorithms, including artificial intelligence (AI) or machine-learning algorithms, and big data have enabled their deployment in many key areas of decision-making, such that many functions traditionally carried out by humans have become increasingly automated. For example, algorithms are used to: assist in sentencing and parole decisions; predict crime ‘hotspots’ to allocate police resources; personalize search engine results, electronic newsfeeds and advertisements; detect fraud; determine credit ratings; facilitate recruitment; and deliver healthcare and legal services. The advent of self-driving cars underscores the speed at which technology is developing to enable more complex autonomous decision-making.Footnote 6
Given the extent of their societal impact, it is perhaps unsurprising that the use of algorithms in decision-making raises a number of human rights concerns. The risk of discrimination arising from the use of algorithms in a wide range of decisions from credit scoring to recidivism models has already been well documented.Footnote 7 The range of contexts in which algorithms are used also generates other less studied threats to human rights. For instance, automated credit scoring can affect employment and housing rights; the increasing use of algorithms to inform decisions on access to social security potentially impacts a range of social rights; the use of algorithms to assist with identifying children at risk may impact upon family life; algorithms used to approve or reject medical intervention may affect the right to health; while algorithms used in sentencing decisions affect the right to liberty.Footnote 8
In recent years a multi-disciplinary literature has developed on ‘algorithmic accountability’.Footnote 9 Proposals for achieving better accountability for decisions made or supported by algorithms have focused either on technical solutions, such as blockchain,Footnote 10 or modalities for improving the transparency of algorithmic systems, making their decision-making process more understandable and explainable, and creating rules in algorithmic programmes to prevent or detect unfair outcomes.Footnote 11 While each of these approaches constitutes a necessary element of accountability, in our view, they are incomplete due to their focus on specific aspects of the overall algorithmic process. Instead, the complex nature of algorithmic decision-making necessitates that accountability proposals be set within a wider framework, addressing the overall algorithmic life cycle, from the conception and design phase, to actual deployment and use of algorithms in decision-making. In light of the diverse range of actors involved, this framework also needs to take into account the rights and responsibilities of all relevant actors.
This article contributes to the literature on algorithmic accountability by proposing an approach based on international human rights law (IHRL) as a means to address the gaps we identify in current proposals for ‘algorithmic accountability’.Footnote 12 Under IHRL, States are required to put in place a framework that prevents human rights violations from taking place, establishes monitoring and oversight mechanisms as safeguards, holds those responsible to account, and provides a remedy to individuals and groups who claim that their rights have been violated.Footnote 13 These obligations apply directly to State actions or omissions and, through the principle of due diligence, the State is also required to protect individuals from harm by third parties, including business enterprises.Footnote 14 IHRL also establishes an expectation that business enterprises themselves respect human rights, for instance by undertaking ongoing human rights due diligence ‘to identify, prevent, mitigate and account for how they address their impact on human rights’.Footnote 15
Some studies have started to emerge that identify the potential impact of AI on human rights.Footnote 16 As part of a wider discussion on regulation of the AI sector, some commentators now also propose human rights as an addition or alternative to ethical principles to address some of the (potential) harm posed by the development and use of AI.Footnote 17 However, these studies—and existing literature on algorithmic accountability—have not engaged in a detailed examination of whether and how the international human rights law framework might itself offer a response to the overall risks to human rights posed by algorithms. This is problematic as IHRL applies to big data and new technologies just as in any other area of life and, as argued here, offers a framework through which algorithmic accountability can be situated. This article is one of the first to examine ‘algorithmic accountability’ from the perspective of IHRL and to detail how human rights can inform the algorithm design, development and deployment process.
This article does not suggest that IHRL offers an exclusive or ready-made, fully developed, solution to the issue of algorithmic accountability. The framework itself has limitations. For example, businesses, particularly large technology companies, are central actors in this area. However, the scope and content of businesses’ human rights responsibilities are still in a process of development under IHRL. While States have direct obligations to prevent and protect human rights from third-party harm, including that caused by businesses, the fact that global businesses operate across multiple jurisdictions inevitably gives rise to regulatory and enforcement gaps and inconsistencies.Footnote 18 IHRL also only establishes ‘expectations’ as to how businesses should operate, it does not currently establish direct obligations under international law.Footnote 19 Within this context, holding businesses to account for harm caused to human rights and ensuring access to an effective remedy against global businesses, in particular, continues to be a challenge.Footnote 20 The IHRL framework also cannot resolve all the challenges related to algorithmic accountability, some of which are addressed by other fields of law such as data protection.
This article does not suggest that IHRL offers a panacea. Rather, our argument is that a human rights-based approach to algorithmic accountability offers an organizing framework for the design, development and deployment of algorithms, and identifies the factors that States and businesses should take into consideration in order to avoid undermining, or violating, human rights. This is a framework which is capable of accommodating other approaches to algorithmic accountability—including technical solutions—and which can grow and be built on as IHRL itself develops, particularly in the field of business and human rights.
Some commentators have suggested that the ‘vastness, never-ending growth and complexity of algorithmic systems’ mean that effective oversight and accountability for their use is not possible.Footnote 21 Others have argued that it is too late to develop an effective oversight model, particularly in ‘an environment dominated by corporate and government interests’.Footnote 22 In our view, space remains to address the existing and potential harm to human rights arising from the use of algorithms in decision-making. However, the pace of technological change and the increasingly prominent and determinative role of algorithms mean that this task is urgent.
Part II examines existing proposals for ‘algorithmic accountability’. It does so by first explaining in more detail the nature of algorithms and how they can adversely impact human rights and pose challenges for accountability. The majority of proposals for accountability have focused on addressing the complexity and sophistication of modern algorithms through greater transparency and explainability. We argue that these approaches are necessary but not sufficient to address the overall risks to human rights. Greater focus on the scope and implementation of States’ obligations and the expectations placed on businesses in relation to prevention, oversight, accountability, and remedies is needed.
In Part III, we propose that IHRL offers an appropriate framework. It does so by setting out a number of internationally agreed substantive and procedural rights which, if violated, constitute harm. It also provides the means to analyse when the use of algorithms in decision-making could contribute to, or result in, harm, even if unintentionally, and establishes a range of obligations and requirements in relation to the identification of, and protection against, such effects. This framework can apply holistically across the full algorithmic life cycle from conception and design to deployment. By incorporating and building on existing models of accountability it provides a deeper way in which to respond to and protect against risks to human rights.
Part IV analyses the impact of this framework on the use of algorithms in decision-making, reaching three key findings. First, IHRL may rule out the use of algorithms in certain decision-making processes. Second, it may require modifications or the building in of additional safeguards in order to ensure rights compliance and thus may create a delay in deployment. Third, it may shift debates on the unpredictability of algorithms, particularly in the future where greater autonomy is anticipated, from a perceived reduced responsibility to a greater responsibility for actors that deploy algorithms in the knowledge that they cannot predict effects, including to human rights. While these three findings act as restrictions on the use of algorithms, in our view, they constitute appropriate checks and balances. They are not intended to be ‘anti-innovation’. Instead algorithmic decision-making is addressed in the same way as human decision-making. The objective is to ensure that algorithms contribute to society, while safeguarding against risks.
II. THE NATURE OF ALGORITHMS AND CURRENT ALGORITHMIC ACCOUNTABILITY DEBATES
This part begins by discussing certain characteristics associated with algorithmic decision-making and how these pose challenges when identifying the impact on human rights and for accountability. Existing ‘algorithmic accountability’ proposals are then examined. Although these proposals constitute a necessary baseline, we identify a number of remaining gaps and challenges.
A. How the Nature of Algorithms Impacts Human Rights
At their simplest, algorithms are formulas designed to calculate a particular result.Footnote 23 Today, algorithms are typically understood as either a piece of code or a computer application that can be used to support human decision-making or to take actions independent of human input. There are many different types of algorithms. Relatively straightforward algorithms may be used to perform mathematical calculations to compute an equation; to sort data, which can be useful for finding patterns and connections; or to classify data on the basis of specified criteria. These ‘traditional’ algorithms run on computer code written by human programmers who understand their logical underpinnings and, if required, can explain how a particular decision was reached by demonstrating the inner workings of the system. However, modern algorithms and the manner in which they are used are becoming increasingly sophisticated.Footnote 24
Modern algorithms are used to support a range of decisions. Some of the most reported examples involve the use of algorithms within decision-making processes that directly affect human rights. The use of algorithmically-produced risk scores in sentencing decisions is one of the most frequently cited examples in this respect,Footnote 25 given that the risk score may have a direct bearing on an individual's right to liberty and the prohibition of discrimination. Algorithmic risk assessments are also used in other sectors. For example, an automated algorithmic-based social security system is currently being implemented in the UK with the aim of streamlining and improving the cost-efficiency of the social security payment system. The system risks discrimination by imposing digital barriers to accessing social security and may therefore exclude individuals with lower levels of digital literacy or without connectivity.Footnote 26 The accessibility of the system as well as the use of risk assessments have the potential to affect the human rights of those in vulnerable positions in key areas of life, such as food, housing and work.Footnote 27 Predictive analytics may also be used in child safeguarding.Footnote 28 For instance, a tool reportedly used by London Councils, in collaboration with private providers, combines data from multiple agencies and applies risk scores to determine the likelihood of neglect or abuse. This raises privacy and data protection concerns as well as issues relating to the right to family life and discrimination.Footnote 29 When algorithms are used to support a decision, such as a risk assessment, they may introduce or accentuate existing human rights challenges and pose new issues for accountability.
Considering these examples, the first issue to address is whether an algorithm may be used to make or support a decision in a particular context. Big data-driven algorithms—such as AI or machine-learning algorithms—typically operate on the basis of correlation and statistical probability. Algorithms analyse large volumes of data to identify relationships between particular inputs and a specific output, and make predictions on this basis. In this context, a larger dataset provides a bigger sample size, which can contribute to lower margins of error and a more accurate model. However, the nature of big data-driven algorithms means that they generate results that describe group behaviour, but which are not tailored to specific individuals within that group, irrespective of the size or quality of the input dataset.Footnote 30 Yet, big data-driven algorithmic models may be used to make individually-focused decisions. For instance, risk assessment tools, such as COMPAS in the US or HART in the UK, are used to predict factors such as an individual's likely recidivism rate. These algorithms calculate individuals’ risk factor using data particular to the individual such as their criminal history and interactions with law enforcement but also variables such as where they live, and their associations with others who have a criminal record.Footnote 31 In effect, these tools make determinations about the likelihood of a particular individual reoffending on the basis of others who share similarities to them. It is foreseeable that these tools could be applied not only to inform, but to actually make decisions in areas such as sentencing, parole or entry into rehabilitation or diversion programmes. Outside the criminal justice context and the social security and social care contexts discussed in the previous paragraph, it is equally foreseeable that algorithms could be used to made decisions regarding an individual's suitability for medical intervention, or for employment. As we discuss further below, the nature of how algorithms work points to risks of arbitrariness, discrimination and a range of human rights issues depending on the context. These types of examples raise questions of whether they could ever be used to make decisions on their own since that decision cannot be individualized.
At the moment, algorithms are typically used to support or inform decision-making, particularly with respect to decisions that explicitly and directly involve human rights, as in the types of examples above. The argument is often made that any shortcomings related to the actual operation of an algorithm may be mitigated by requiring that the algorithm only inform and not make the decision; ie a human ‘in the loop’ acts a safeguard. However, this gives rise to numerous issues regarding the human ‘in the loop's’ ability to understand how the algorithm functions and therefore to assign appropriate weight to any recommendation. The degree of deference granted to an automated recommendation is also at issue, as there is a risk that individuals may be reluctant to go against an algorithmic recommendation. This may be because of a perception that an algorithm is neutral or more accurate, or because of the difficulty in explaining why the algorithmic recommendation was overturned. This may render the human ‘in the loop’ ineffective.
Second, even if the human ‘in the loop’ is an effective safeguard and the algorithm is only used to inform decisions about sentencing or children at risk, an issue of potential algorithmic bias arises. If the input data is itself biased, say as a result of over-policing of a specific community, or if the algorithm operates in such a way as to produce biased results, then this may give rise to unlawful discrimination. In this regard, modern algorithms depend on good quality input data, but this may not always be available. If particular input data cannot be quantified or obtained, ‘proxies’ may be used instead. However, as proxies are not an exact substitute they may be inappropriate, inaccurate, or unreliable, affecting the quality and reliability of the results.Footnote 32 One example that illustrates the pitfalls of data-driven algorithms is credit scoring. Traditionally, credit scores were calculated on the basis of defined factors such as credit repayment history.Footnote 33 With the advent of ‘big data’, the availability of data used to inform credit decisions has widened, and evaluation can now include information such as social media activity and online shopping patterns.Footnote 34 The argument for including these factors is that they may provide more accurate predictions because of ‘fuller’ data profiles. However, these proxies for creditworthiness are problematic and their incorporation may result in human rights harm. For instance, these new data points may be linked to race or gender and their use may therefore be discriminatory.Footnote 35
Third, there may be a lack of transparency as to the actual operation of the algorithm. For example, this may prevent an accused from challenging the recommendation or risk assessment produced by an algorithm in a sentencing decision, or may prevent a person whose level of social care or social security is to be reduced on the basis of an algorithmic assessment from appealing. Even if there is transparency and a person affected by an algorithmically-influenced decision wishes to challenge that decision, the nature of the algorithmic process may make that very difficult.
One issue in this respect is that a typical application brings together a (potentially large) number of different algorithms that interact to perform a complex task. For instance, a number of different algorithms may be at play with output data from one algorithm providing input data for another. Tracing the factors that contribute to the final output is therefore complex. This complexity is compounded when the development of an application is distributed, either within an organization or through outsourcing, and when deployments utilize input data that is difficult to replicate in a test environment.Footnote 36 This diffuses the ability to comprehensively understand the overall operation of an application and thus identify where and/or how human rights issues arise.Footnote 37 Equally, machine-learning algorithms can self-learn, identify patterns, and make predictions unimagined by a human operator, and unexplainable by humans.Footnote 38 Machine-learning algorithms used to analyse handwriting and sort letters in a post office provide an example. The algorithm analyses a large number of handwriting samples to learn how to classify certain pen marks, infer rules for recognizing particular letters and digits, and develop its own system for doing so.Footnote 39 While a human may try to learn when a particular pattern represents the digit ‘2’ on the basis of the curvature of the strokes, etc, a machine-learning algorithm will analyse markedly different factors, such as the configuration and intensity of the shading of relevant pixels. As the algorithm's learning process does not replicate human logic, this creates challenges in understanding and explaining the process.Footnote 40 Machine-learning models may also ‘learn’ in real-time,Footnote 41 meaning that over time similar input data may result in different outputs. These systems can thus be unpredictable and opaque, which makes it challenging to meaningfully scrutinize and assess the impact of their use on human rights and thus to effectively challenge decisions made on the basis of algorithms. This was at issue in State of Wisconsin v Eric L Loomis,Footnote 42 where the defendant raised concerns regarding his inability to challenge the validity or accuracy of the risk assessment produced by the COMPAS tool, which was used to inform his sentencing decision. Issues raised by the defendant included the problem of looking inside the algorithm to determine what weight was given to particular information and how decisions were reached. Difficulties in effectively challenging the risk assessment were acknowledged by the Court,Footnote 43 which noted a number of factors suggesting caution vis-à-vis the tool's accuracy:
(1) the proprietary nature of COMPAS has been invoked to prevent disclosure of information relating to how factors are weighed or how risk scores are to be determined; (2) risk assessment compares defendants to a national sample, but no cross-validation study for a Wisconsin population has yet been completed; (3) some studies of COMPAS risk assessment scores have raised questions about whether they disproportionately classify minority offenders as having a higher risk of recidivism; and (4) risk assessment tools must be constantly monitored and re-normed for accuracy due to changing populations and subpopulations.Footnote 44
The above characteristics of the algorithmic decision-making process all pose human rights challenges and raise difficulties for accountability efforts. These difficulties are compounded when multiple characteristics are present in the same process, as will often be the case. Further complexities arise when the impact of an algorithm on an individual has knock-on effects for others. For instance, if credit decisions are based not only on data specific to an individual, but are expanded to include data relating to those with whom they interact and maintain relationships, it may amplify the discriminatory effect.Footnote 45 A poor credit score for a particular individual may result in a poorer score for those in their neighbourhood or social network.Footnote 46 This potential cascade effect is often referred to as ‘networked discrimination’,Footnote 47 which echoes the historically discriminatory practice of ‘redlining’, whereby entire neighbourhoods of ethnic minorities were denied loans by virtue of where they lived.Footnote 48
To counter the potential adverse effects of the way in which algorithms work on human rights, scholars and practitioners have focused on addressing the way in which algorithms function and their transparency, explainability and understandability, as discussed in the next section. We argue that although these approaches are necessary, in and of themselves they are not sufficient to address the overall risks posed to human rights.
B. Existing Proposals for Algorithmic Accountability and Their Ability to Address the Impact of Algorithms on Human Rights
The pursuit of ‘algorithmic transparency’ is a key focus of existing approaches to algorithmic accountability. This relates to the disclosure of information regarding how algorithms work and when they are used.Footnote 49 To achieve transparency, information must be both accessible and comprehensible.Footnote 50 Transparency in this context can relate to information regarding why and how algorithms are developed,Footnote 51 the logic of the model or the overall design,Footnote 52 the assumptions underpinning the design process, how the performance of the algorithm is monitored,Footnote 53 how the algorithm itself has changed over time,Footnote 54 and factors relevant to the functioning of the algorithm, such as data inputs (including proxies), and the relative weight attributed to inputs.Footnote 55 Transparency can also relate to the level of human involvement,Footnote 56 in order ‘to disentangle the roles and decisions of humans versus algorithms’.Footnote 57 This section discusses why transparency is valuable for accountability, addresses challenges in achieving transparency, and highlights remaining accountability gaps.
1. The value of transparency
The focus on transparency is a result of the nature and complexity of modern algorithms and the view that if algorithms cannot be scrutinized, any risks to human rights within decision-making processes will be difficult to identify and to rectify. Transparency is essential for trust, and to ensure that a system operates within appropriate bounds.Footnote 58 The ability to predict the behaviour of an algorithm and to explain the process by which it reasons is necessary to control, monitor, and correct the system,Footnote 59 and to audit and challenge decisions supported by algorithms.Footnote 60 Understanding how an algorithm works can also be useful in anticipating how it could perform if deployed in a different context.Footnote 61 Some authors have asserted that transparency should be the policy response for any governmental use of automated decision-making.Footnote 62
2. Transparency challenges
Notwithstanding the importance of transparency as a normative objective, some commentators have noted that it may be difficult to achieve in practice,Footnote 63 highlighting that of itself transparency may not be meaningful.Footnote 64 For example, certain algorithms can ‘learn’ and modify their operation during deployment,Footnote 65 and so the factors that inform a decision (and the resultant outputs) may vary over time, reducing the utility of transparency-induced disclosure.Footnote 66 Equally, transparency as to when an algorithm is deployed may not be meaningful unless it is possible to explain the underlying logic, or to interrogate the input data.
Blockchain, an open distributed ledger system that records transactions,Footnote 67 is one technical tool that has been suggested as a potential solution.Footnote 68 To date, blockchain has been used to reconcile transactions distributed across various entities within and between organisations. This existing ability to track items and specific financial transactions may be adapted and applied to the use of specific data points throughout an algorithmic decision-making process. For example, other authors have suggested that blockchain may be used to track data provenance and to improve accountability in the use of data, by verifying ‘if the data was accessed, used and transferred’ in compliance with users’ consent.Footnote 69 This could facilitate tracing back through a decision to see which data points informed it and the weight they were given.
Nonetheless, the extent to which transparency challenges can be overcome is a live debate, and a number of complicating factors arise. First, businesses have an understandable proprietary interest in the algorithms they develop and so may be unwilling to reveal the underlying code or logic.Footnote 70 To overcome this challenge, suggestions have been made that the algorithm does not have to be made publicly transparent but rather could be subject to independent review by an ombud for example.Footnote 71 Second, transparency regarding an algorithm's code or underlying logic may be undesirable.Footnote 72 This ‘inside’ knowledge may facilitate the ‘gaming’ of the system,Footnote 73 resulting in abuse, and improper results. The risk is particularly clear in the context of security screening or tax audits.Footnote 74 In other situations, such as those involving ‘sensitive data’, transparency may be legally restricted.Footnote 75 Third, the complex interaction between algorithms and human agents is another source of opacity. When algorithms assist human decision-making, it is difficult to determine the influence of the algorithm's results on the final decision, and to identify whether inappropriate deference is given to the algorithm.Footnote 76 As such, and irrespective of transparency issues, it is also necessary to evaluate how algorithmic outputs influence human decision-making within the context of the overall process. This is discussed in greater detail in Part IV. Fourth, even if it is possible to fully explain the system's reasoning, an important question arises regarding the resources and expertise required to do so.Footnote 77 Addressing this question will involve assessments of the cost of transparency against the reasons for using the algorithm in the first place (which may often relate to competitive pricing).
3. The gaps remaining in the accountability process
Transparency is essential to accountability but insufficient of itself. This section identifies five additional factors necessary for effective accountability, many of which have either not been addressed or have not been evaluated holistically in existing debates. First, a clear understanding of what constitutes ‘harm’ is a prerequisite to, and benchmark for, evaluating risks and effects of the use of algorithms in decision-making. In the absence of an agreed understanding, ‘harm’ is open to a number of different interpretations, and the understanding adopted by a particular actor may fail to effectively take into account the full human rights impact of their actions. For instance, a business’ ‘community values’ may not fully match IHRL. For example, they could focus on the right to privacy but not incorporate the right to freedom of expression or the prohibition of discrimination. Second, in order to prevent and protect against harm, the overall decision-making process and the full life cycle of an algorithm must be taken into account, and the specific role played by an algorithm in any final decision identified. Design, development and deployment of algorithms are interconnected phases within an overall process and decisions made in one phase may affect human rights compliance in another. For example, it may not be possible to monitor the potential discriminatory impact of an algorithm if this is not built in during the development phase. Equally, the role played by an algorithm in the final decision, such as whether it is used to make or inform that decision, will impact upon the human rights considerations. Third, the obligations and responsibilities of States and businesses respectively need to be ascertained from the outset, noting that these will depend on their specific role at different stages of the overall decision-making process. Fourth, remedies for harm caused must be addressed. To date, the concept of remedy has narrowly focused on fixing the operation of the algorithm where bias is identified, but the concept of an effective remedy under IHRL is much broader by focusing on the individual(s) affected as well as taking measures to ensure that the harm is not repeated in the future. Fifth, an overall shift in focus may be required. Existing approaches to accountability tend to focus on after-the-fact accountability. While this is important, it is also crucial that accountability measures are fully incorporated throughout the overall algorithmic life cycle, from conception and design, to development and deployment.Footnote 78 Discussion in this regard is emerging, for instance with respect to whether and how ‘ethical values’ can be built into algorithms in the design phase,Footnote 79 and whether algorithms can themselves monitor for ethical concerns. While this is a welcome start, the discussion needs to go further, and the operationalization of the IHRL framework can play a significant role in this regard.
Achieving effective accountability is therefore a complex problem that demands a comprehensive approach. Somewhat surprisingly, IHRL has been neglected in existing discourse until relatively recently.Footnote 80 While values such as dignity,Footnote 81 legal fairness, and procedural regularity in the design of algorithmsFootnote 82 are referenced in the literature, neither the range of substantive rights established under IHRL, nor the possibility that IHRL provides a framework capable of underpinning the overall algorithmic accountability process, have received significant attention. This is beginning to change with more actors starting to support a human rights-based approach to the development and use of artificial intelligence. The next part of this article contributes to these developments by clearly setting out the specific contribution that IHRL can make. This article advances an overall framework through which to address the issue of algorithmic accountability, and adds depth to existing discussion.
III. THE CONTRIBUTION OF THE HUMAN RIGHTS FRAMEWORK TO ALGORITHMIC ACCOUNTABILITY
IHRL contributes to the algorithmic accountability discussion in three key ways. First, it fills a gap in existing discourse by providing a means to define and assess harm. Second, it imposes specific obligations on States and expectations on businesses to prevent and protect human rights and sets out the mechanisms and processes required to give effect to or operationalize these obligations and responsibilities. Third, the IHRL framework can map on to the overall algorithmic life cycle and thus provides a means for assessing the distinct responsibilities of different actors across each stage of the process. IHRL therefore establishes a framework capable of capturing the full algorithmic life cycle from conception to deployment. Although we do not suggest that IHRL provides an exclusive approach, it does provide a key lens through which to analyse accountability. As such, it forms an important dimension and organizer for algorithmic accountability that fits together with existing approaches such as transparency, explainability, and technical solutions.Footnote 83 Necessarily, the specifics of the approach will need to be further developed and refined in a multi- and interdisciplinary way.
A. IHRL as a Means for Assessing Harm
In the current discourse on ‘algorithmic accountability’ harm is regularly referred to but often using vague or abstract terms such as unfairness, or by reference to voluntary corporate policies.Footnote 84 These terms make it difficult to pinpoint the exact nature of the harm and to assess whether and which legal obligations attach. There is also a risk that the extent of potential harm is underplayed or narrowly construed.Footnote 85
The focus on ‘bias’ illustrates the risks arising in this regard. Within the literature on algorithmic accountability, the term ‘bias’ (and less often ‘discrimination’) is used in a range of different ways, often without clarity on the meaning employed. It is sometimes used to convey a specific technical meaning, for example with reference to statistical bias.Footnote 86 In other contexts, it is employed as a general, ‘catch-all’ term to mean some form of preference or ‘unfairness’ (which itself has been criticized as a vague term). When used in such a broad way, actors may develop or gravitate to locally defined understandings as to what constitutes bias or discrimination, giving rise to a variety of meanings. This can also create uncertainty for actors designing, developing and using algorithms in decision-making as to whether a particular instance of bias is unlawful.
Scholars sometimes indicate that unlawful bias may constitute a narrower category under an overall heading of ‘bias’ but without concretely explaining how.Footnote 87 IHRL can make a central contribution in this regard as a counter to general descriptors of ‘bias’ or ‘discrimination’ by providing a method for understanding when bias and discrimination are unlawful. In this regard, IHRL provides a concrete and universally applicable definition of harm that is capable of identifying prohibited and unlawful forms of bias and discrimination.Footnote 88 This definition is accompanied by well-developed and sophisticated tests for establishing when the prohibition of discrimination has been violated, including what constitutes direct, indirect or intersectional discrimination as well as structural and unconscious bias. IHRL therefore not only provides a means to determine harm through its interpretation of how rights may be interfered with, it also provides established tests to assess when and how rights may have been violated.
The IHRL framework also offers a deeper and fuller means of analysing the overall effect of the use of algorithms. This moves beyond the current singular and narrow framings of harm which tend to focus on ‘bias’ or ‘privacy’ to look at the full impact of algorithms on the rights of individuals and groups. For example, the use of algorithms to aid sentencing and parole decisions have been reported to be ‘biased’ against certain ethnic minorities.Footnote 89 The IHRL framework not only assesses whether such use violates the prohibition of discrimination but also examines the impact from the perspective of the individual's right to a fair trial and to liberty. This broader approach is essential as it captures the overall impact of algorithms and may indicate, for example, that algorithms cannot be used in a particular context, even if discrimination-related concerns are addressed.Footnote 90
The IHRL framework therefore provides a means of categorizing and labelling harm through its establishment of an internationally agreed set of substantive and procedural rights which, if violated, constitute harm. Incorporating a means to assess (potential) harm is critical to developing an effective accountability framework for the use of algorithms in decision-making. Importantly, the IHRL framework not only describes the nature of harm but triggers an existing framework that attaches to these rights. As discussed in the next section, this framework connects directly to concrete legal obligations imposed on States to prevent and protect against such violations, including with respect to the regulation of business actors, and establishes clear expectations on businesses themselves as regards to the actions necessary to respect human rights. IHRL thus brings clarity regarding the actions that States and businesses are expected to take and the consequences of failing to act.
B. Clearly Defined Obligations and Expectations That Apply Across the Algorithmic Life Cycle
By identifying the range of rights brought into play by the use of algorithms in decision-making, IHRL establishes a clear set of obligations on States and expectations on businesses to prevent and protect human rights across the algorithmic life cycle. Focusing on existing legal obligations is critical as it emphasizes that addressing the (potential) harm caused by the use of algorithms in decision-making is not a voluntary exercise, as often appears to be the implication in existing discourse and debates.Footnote 91 This section analyses how the IHRL framework applies across the life cycle of algorithms in order to demonstrate its potential contribution to filling gaps in the current accountability debate.
1. Identifying roles and responsibilities attached to different entities across the full algorithmic life cycle
IHRL requires that States put in place an accountability framework that prevents violations from taking place, establishes monitoring and oversight mechanisms as safeguards, and provides a means to access justice for individuals and groups who claim that their rights have been violated.Footnote 92 The components of this accountability framework are necessarily interdependent, and apply across the full algorithmic life cycle. This is illustrated in general terms in the diagram below.
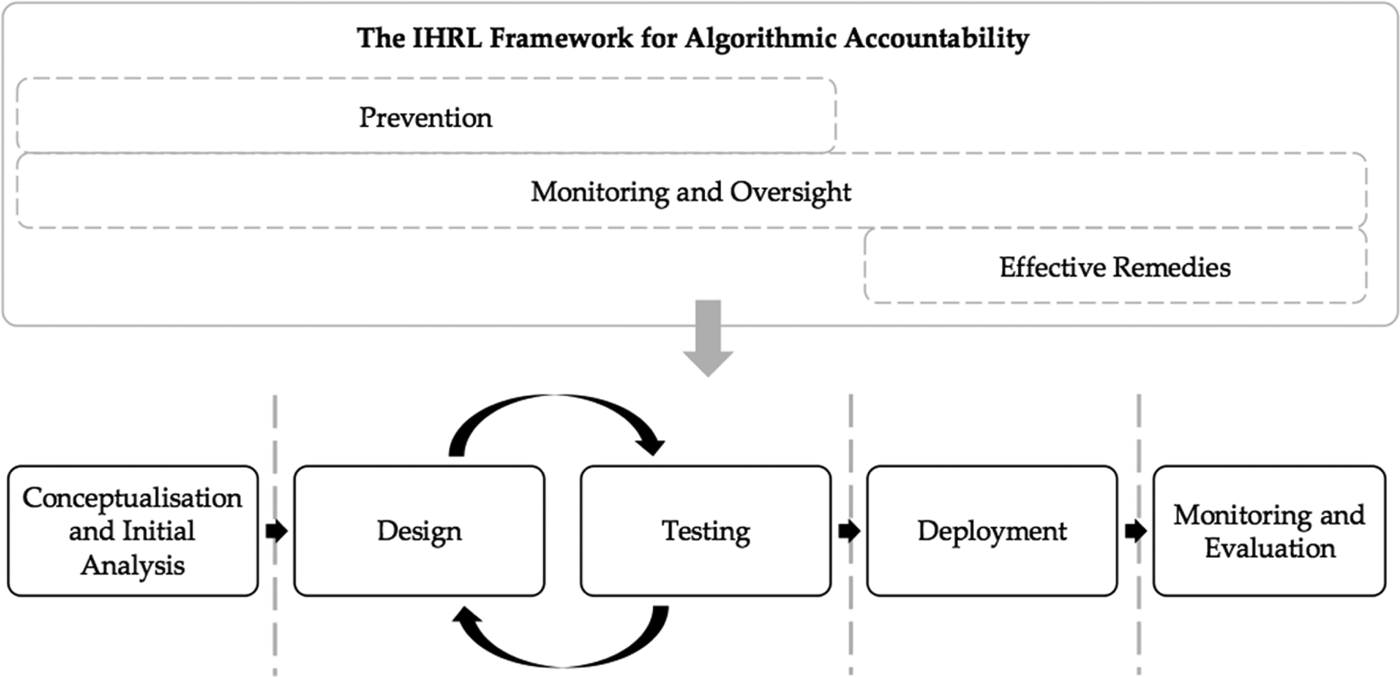
As IHRL traditionally focuses on State conduct, these obligations apply to the actions or omissions of the State directly. This is important as States are increasingly reported to be integrating algorithms within their decision-making processes across a range of sectors that may have significant consequences for individuals and groups in areas such as policing, sentencing, social security and the identification of children at risk, as noted above.Footnote 93 IHRL also addresses business activity, by requiring the State to protect against third-party harm, and by imposing specific expectations directly on businesses. The principle of due diligence requires States to prevent and protect individuals from harm by third parties, including business enterprises. For instance, States are required to devise ‘appropriate steps to prevent, investigate, punish and redress private actors’ abuse … [t]hey should consider the full range of permissible preventative and remedial measures, including policies, legislation, regulations and adjudication’.Footnote 94 Human rights standards and norms also apply directly to business enterprises, as articulated, for example, in the UN Guiding Principles on Business and Human Rights (the Ruggie Principles). These principles establish an expectation that businesses should prevent or mitigate ‘adverse human rights impact’, establish a means of access to justice where human rights violations are alleged, and provide remedies where rights are found to be breached. For both States and businesses, giving effect to these obligations or expectations requires establishing monitoring and oversight mechanisms that apply throughout the entire algorithmic process.
As discussed in the next sections, IHRL sets out the measures required if States or businesses are to comply with human rights law: IHRL details the actions that different actors should take at each point in the process, from conception to deployment. This facilitates a means of engaging with the overall picture, both in terms of the process of developing and deploying algorithms, and evaluating their impact. This portrayal of how to achieve a holistic approach to accountability is currently absent from the discourse.
2. Operationalizing the measures necessary to ensure rights compliance
IHRL provides a range of measures to guide States in the implementation and operationalisation of their obligations to prevent and protect human rights, and to guide businesses regarding the actions they should take to respect human rights. For example, the Office of the UN High Commissioner for Human Rights (OHCHR) defines ‘direct prevention’ as ‘aim[ing] to eliminate risk factors and establish a legal, administrative and policy framework which seeks to prevent violations’.Footnote 95 It notes that this obligation comprises a number of different elements, highlighting that some ‘provisions point to an obligation of negative result (prevention being successful when there is no violation), while in some cases prevention can be seen as an obligation of positive conduct (taking all necessary steps to adopt concrete and effective measures to prevent violations)’.Footnote 96 The prevention of harm is directly linked to the obligation to respect, whereby States must refrain from taking measures that will result in a human rights violation.Footnote 97 The UN Guiding Principles on Business and Human Rights apply this same requirement to businesses, in terms of ‘[t]he responsibility of business enterprises to respect human rights’.Footnote 98 As discussed above, in ensuring that they respect human rights, States and businesses need to ensure that policies and practices are in place to identify and assess any actual or potential risks to human rights posed by the use of algorithms in decision-making.
The IHRL framework provides further guidance as to the type of measures that can operationalize the respect principle. The full life cycle approach allows for existing algorithmic accountability proposals—relating, for example, to auditing or impact assessments—to be situated within a comprehensive process. This facilitates greater clarity and focus by setting out what the objectives underpinning specific measures should be, their scope and depth, what the indicators of effectiveness are, and when measures should be undertaken.
Impact assessments provide an example. As a result of a narrow conceptualization of harm, impact assessments in an algorithmic context have typically focused on issues relating to discrimination and privacy.Footnote 99 The IHRL framework contributes in three key ways. First, it clarifies the content of the right to privacy and the prohibition of discrimination. This ensures that all aspects of the rights—including indirect discrimination, for example—are taken into account, while also facilitating consistency across assessments. Second, the use of algorithms in decision-making can potentially affect all rights. The IHRL framework requires that impact assessments encompass the full set of substantive and procedural rights under IHRL, and that analysis not be unduly limited to privacy or discrimination. Third, the IHRL framework underscores the need for risks to be monitored at all stages of the algorithmic life cycle.Footnote 100
Applying this in practice means that impact assessments should be conducted during each phase of the algorithmic life cycle. During the design and development stage, impact assessments should evaluate how an algorithm is likely to work, ensure that it functions as intended and identify any problematic processes or assumptions. This provides an opportunity to modify the design of an algorithm at an early stage, to build in human rights compliance—including monitoring mechanisms—from the outset, or to halt development if human rights concerns cannot be addressed. Impact assessments should also be conducted at the deployment stage, in order to monitor effects during operation. As stated, this requires that, during design and development, the focus should not only be on testing but steps should also be taken to build in effective oversight and monitoring processes that will be able to identify and respond to human rights violations once the algorithm is deployed. This ability to respond to violations is key as IHRL requires that problematic processes must be capable of being reconsidered, revised or adjusted.Footnote 101
The establishment of internal monitoring and oversight bodies can play an important role in coordinating and overseeing the implementation of regular impact assessments and ensuring that findings are addressed. Some businesses in the AI sector have started to develop internal committees.Footnote 102 The nature and mandate of such committees has been subject to some commentary,Footnote 103 and reflects an evolving dimension to legal and policy debates on algorithmic accountability.
Notwithstanding the nature of any internal processes, independent oversight plays an important role in the AI sector as it does in other areas where decision-making by States or businesses has the potential to adversely affect human rights. For instance, independent oversight is a core requirement with respect to State surveillance activities.Footnote 104 To date, similar oversight models have not been introduced to the algorithmic decision-making context. However, independent oversight mechanisms may be central to ensuring that States and businesses comply with their respective human rights obligations and responsibilities. They may provide an appropriate means to assess the processes put in place by States and businesses, and may also provide expert input vis-à-vis potential risks. An independent oversight body may also play an essential role in determining whether algorithms can be used in certain contexts, and if so, under what conditions, as discussed in the next part of this article.Footnote 105 Independent oversight may take a number of different forms, dependent upon factors such as the public or private function of the algorithm during deployment. For algorithms deployed in a public decision-making context, an independent body, established in legislation, and sufficiently resourced (including with appropriate technical expertise) may be the most appropriate.Footnote 106 The newly established UK Centre for Data Ethics and Innovation is an interesting proposition in this regard. This body is intended to strengthen the existing algorithmic governance landscape,Footnote 107 but its role is limited to the provision of advice: it is an ‘advisory body that will investigate and advise on how [the UK] govern[s] the use of data and data-enabled technologies’.Footnote 108 As such, it cannot qualify as an effective oversight body. However, it is conceived, at least in part, as an interim measure to ‘allow the government time to test the value and utility of the Centre's functions ahead of the creation of a future statutory advisory body’.Footnote 109 Recently, Canada produced a white paper addressing ‘Responsible Artificial Intelligence in the Government of Canada’, which highlighted the need for an oversight body to review automated decision-making, and to provide advice to ministers during the design of AI systems.Footnote 110 Lessons learned from experiences such as these may provide valuable insight going forward. Independent oversight bodies established to monitor State surveillance activity and analysis of their effectiveness may also provide points of reference and comparison.Footnote 111 Other models being proposed include dedicated ombuds for the AI sector or the expansion of the mandate of existing ombuds to address these issues as well as industry regulatory bodies.Footnote 112
In the event that violations are found to have occurred, IHRL imposes a number of requirements: measures must be put in place to prevent any reoccurrences, those affected must be provided with effective reparation, and those responsible must be held to account. Within current accountability debates, however, there is often a narrow focus on addressing problems with the use of an algorithm, in order to fix the issue and prevent reoccurrences.Footnote 113 This is, of course, an important measure, and one that aligns with IHRL requirements, particularly those relating to the concept of guarantees of non-repetition. However, under the IHRL framework this is just one component of a larger process. In order for individuals and groups to challenge the impact of the use of algorithms in decision-making, IHRL requires that States and businesses provide a means to access justice for those with an arguable claim that their rights have been violated. Given the lack of transparency in this area, broad standing provisions may be necessary, in order to enable individuals to bring claims if they suspect but cannot prove that they have been adversely affected by an algorithmic decision-making process. States and businesses may develop internal processes for individuals to submit complaints to them directly, although there is currently debate on whether complainants should be required to use such processes, where they are not independent of the entity concerned.Footnote 114 What is critical, therefore, is that States establish complaints mechanisms such as ombuds and effective judicial remedies. Determining which entity (or entities) is responsible for a particular harm is equally essential in order to allocate responsibility for providing an effective remedy. The approach to remedy within the algorithmic accountability discussion needs much greater attention, including examination of the possibility that remedies could themselves be driven by algorithms.
3. Integrating a rigorous accountability framework
By situating obligations and expectations across the life cycle of an algorithm, what is required of the different actors involved becomes clearer. This is particularly important given the number of different entities that may be involved across the algorithmic life cycle, and the fact that algorithms may be sold and deployed in a variety of different contexts. Indeed, various public-sector organizations have already integrated the use of algorithms into their decision-making processes. For example, in the UK the ‘Harm Assessment Risk Tool’ (also known as ‘HART’) is used by Durham Constabulary to determine which individuals are eligible for an out-of-court process, intended to reduce future offending. The tool was developed by statistical experts based at the University of Cambridge in collaboration with Durham Constabulary.Footnote 115 Elsewhere in the UK local governments have been using products and services developed by private companies in areas such as child safeguarding, welfare services, and education.Footnote 116 This dimension has been raised, but not adequately explored, in existing discourse. The IHRL framework incorporates the diversity of actors involved, and allows for nuance with respect to the obligations or expectations imposed on different actors.
For instance, the obligation/responsibility to respect requires that an entity developing an algorithm identify any potential harm to rights, and take measures to protect against that harm. If the algorithm is to be sold, the developer must also consider future third-party deployments. This may require clarification or elaboration of a number of requirements, such as the intended circumstances of use, the volume and quality of input data required, or the statistical accuracy of the results. This is a means of satisfying the developer's own human rights obligations/responsibilities and facilitating human rights compliance by any subsequent users. If an algorithm is sold, the purchaser's human rights obligations or responsibilities are also brought into play; ie the purchaser must perform their own impact assessment and deploy the algorithm in line with the developer's specifications. If the purchaser subsequently modifies the circumstances of use, they will necessarily have to carry out further impact assessments. The IHRL framework accordingly allows for a division and allocation of responsibilities. For instance, if the original developer fulfils their human rights obligations, then they cannot be held responsible for subsequent third-party misuse, and responsibility will accordingly lie with the purchaser. Equally, if the purchaser deploys the algorithm appropriately (ie in line with their human rights obligations) but a problem arises as a result of the developer's lack of compliance, then responsibility lies with the developer not the purchaser.Footnote 117
To summarize, IHRL defines harm in a universally accepted form and sets out the specific obligations or expectations that apply to the different actors involved across each stage of the algorithmic life cycle. IHRL also details the means necessary to ensure human rights compliance, setting out the different mechanisms that may be employed, and clarifying the objectives underpinning these measures. By looking at the overall algorithmic life cycle, and requiring that human rights obligations/expectations are taken into account from the conception stage, the IHRL framework also facilitates effective accountability and compliance. For instance, it may be difficult if not impossible to detect harm at the deployment stage if oversight mechanisms are not built in during development. Equally, if potential indirect discrimination is not identified by a pre-deployment impact assessment, the consequences for affected individuals or groups may be significant. Ultimately, the comprehensive full life cycle overview approach facilitated by the IHRL framework is essential in order to ensure that technology serves, rather than undermines, human and societal interests.
The IHRL framework clearly sets out the measures that all actors should take—and which States must take—in order to ensure that the design, development and deployment of algorithms is undertaken in a human-rights-compliant manner. It is a clear expectation of the international community that businesses fulfil their responsibility to respect human rights.Footnote 118 The framework elaborated above provides a road map in this regard.
IV. THE EFFECT OF APPLYING THE IHRL FRAMEWORK TO THE USE OF ALGORITHMS IN DECISION-MAKING
This part analyses how the application of the IHRL framework may affect decisions regarding the development and deployment of algorithms. To reiterate, the application of the IHRL framework is intended to ensure that the potential inherent in technology can be realized, while at the same time ensuring that technological developments serve society. As such, the increasing centrality of algorithms in public and private life should be underpinned by a framework that attends to human rights. This is not intended to be anti-technology or anti-innovation, it is directed at human-rights-compliant, socially beneficial, innovation.
A. Are There Red Lines That Prohibit the Use of Algorithms in Certain Instances?
Most of the debates on algorithmic accountability proceed from the assumption that the use of algorithms in decision-making is permissible. However, as noted at the outset of this article, a number of situations arise wherein the use of algorithms in decision-making may be prohibited. The IHRL framework assists in determining what those situations might be, and whether a prohibition on the use of algorithms in a particular decision-making context is absolute, or temporary, ie until certain deficiencies are remedied. This question should first be addressed during the conception phase, before actual design and development is undertaken, but should also be revisited as the algorithm develops through the design and testing phase and into deployment. In this regard, we envisage a number of scenarios in which the use of algorithms in decision-making would be contrary to IHRL.
1. Prohibition of the use of algorithms to circumvent IHRL
First, and most straightforwardly, IHRL prohibits the use of an algorithm in decision-making if the purpose or effect of its use would circumvent IHRL. This may occur if the intent of using an algorithm is to unlawfully discriminate against a particular group or if the effect of an algorithm is such that it results in indirect discrimination, even if unintentionally. In such scenarios, the use of the algorithm in decision-making would be prohibited as long as discriminatory effects exist. However, as discussed above, these effects could be overcome, if identified in the conceptualization and design phase or through internal and/or external oversight processes, and the algorithm modified and refined to remove any discriminatory bias, although a remedy would still be required to any individuals adversely affected.
A recent study conducted by researchers at Stanford University exemplifies this point. This study focused on how deep neural networks can extract facial features. The authors hypothesized that neural networks are better at detecting, interpreting, and perceiving facial cues than the human brain. The test involved comparing how deep neural networks performed compared to humans in determining sexual orientation from a set of facial images stored on a dating site. The study assumed that the sexual orientation of the individual could be inferred from the gender of the partners they were looking for on their dating profile. They concluded that ‘deep neural networks are more accurate than humans at detecting sexual orientation from facial images’.Footnote 119 The authors argued that they carried out the research to generate public awareness about the risks that technology could be used in this way.Footnote 120
The study was heavily criticized in the media, and by academics and civil society.Footnote 121 A key point was whether technology should be used for the purpose of determining a person's sexual orientation, particularly as it could result in individuals and communities being targeted for abuse, and possibly put their lives at risk.Footnote 122 In general, human determination regarding the sexual orientation of another person is prohibited since IHRL emphasizes self-identification regarding sexual orientation as integral to one's personality, and fundamental to self-determination, dignity and freedom.Footnote 123 If technology is deployed to carry out a task which would be prohibited if carried out by a human, it follows that the deployment of the technology would also be prohibited. Of course, in cases where discriminatory effects are identified and the algorithm can be modified accordingly to remove those effects, it is possible that the algorithm may then be deployed. Any affected individuals remain entitled to a remedy.
2. Prohibition of the exclusive use of algorithms to make certain decisions
Second, IHRL may prohibit certain decisions that are made exclusively on the basis of an algorithm, without the possibility of human intervention. In cases where an individual's rights are interfered with by a decision involving algorithms, the underlying reasoning must be made on the basis of factors specific and relevant to that individual. This derives from the prohibition of arbitrary rights interference as a core principle underpinning IHRL and is therefore relevant to all decisions that have the potential to interfere with particular rights.Footnote 124
Modern algorithms raise issues in the context of arbitrariness as, given the nature of big data-driven algorithms, (a) decisions may be based on group-level characteristics, ie x members of a group are likely to behave in a particular way, as opposed to individually-focused characteristics, ie a specific individual is likely to act in a particular way because of factors specific to that individual, and (b) decisions are often based on correlation and not causation. These two factors are interrelated. They indicate that analysis vis-à-vis likely future behaviour is valid only at the group and not at the individual level, and that predictions are not determinative as to how a specific individual will act.Footnote 125 These models fail to account for individual agency, and the relevance of individual choice. This raises concerns that algorithmic decisions applied to individuals may, in certain cases, be inherently inconsistent with the prohibition of arbitrary interference with rights.Footnote 126
These characteristics suggest that while algorithms may be used as a piece of evidence within a decision, they cannot provide the sole basis for a decision that directly affects an individual's rights: some form of human involvement or oversight is necessary. For instance, the application of IHRL indicates that a sentencing, bail or parole decision can never be decided exclusively by an algorithm. These decisions directly affect an individual's right to liberty, a central component of which is the prohibition of the arbitrary deprivation of liberty.Footnote 127 This requires, amongst other factors, that detention, or continued detention, be based upon reasons specific to the individual in question.Footnote 128 The nature of algorithmic decision-making inherently precludes this possibility as analysis is conducted on the basis of group behaviour, and correlation not causation.Footnote 129 Exclusive reliance on algorithmic decision-making in this context must be considered arbitrary and therefore prohibited.Footnote 130
B. Safeguards Required to Permit the Use of Algorithms
In other situations, whether the use of an algorithm within a decision is compatible with IHRL may depend upon the safeguards embedded within the process, including the level and type of human involvement. These safeguards are centred on ensuring that an algorithm operates effectively, within acceptable parameters. For instance, social media companies are currently engaged in efforts to moderate content in light of the alleged use of their platforms to promote terrorism or propagate hate speech.Footnote 131 This is a difficult task that directly brings the right to freedom of expression into play; there is a danger that the removal of posts may be inconsistent with IHRL—a post may be offensive but not illegal—and therefore violate the poster's right to freedom of expression.Footnote 132 Given the complexity of rights at issue, algorithms are used to flag, filter and classify certain content, but teams of human moderators ultimately decide how content or a particular user account should be managed. In this case, human input acts as a form of safeguard intended to ensure that content is not wrongly restricted or removed by algorithms.
Another key consideration is not only whether safeguards are in place but also whether they are able to operate effectively. This issue may be demonstrated by considering the role of the ‘human in the loop’. A human decision-maker is considered to be ‘in the loop’ when they are involved in the decision-making process, for instance when they make a decision informed by an algorithmic output or when they provide oversight in relation to the algorithmic decision-making process.Footnote 133 However, the presence of a human operator does not guarantee that safeguards are effective. For example, questions arise about the operator's ability to meaningfully understand the algorithmic decision-making process, their capacity to determine whether and how any human rights have been affected, and the extent to which they automatically or subconsciously defer to the algorithmic decision. Deference may arise, for example, due to perceptions of the neutrality and accuracy of technology and concerns about going against the findings of such technology.Footnote 134 This creates a risk that algorithms become the de facto sole decision-maker, even if there is apparently some human input.
A recent decision of the Wisconsin Supreme Court in the USA regarding the use of algorithmic risk assessments in sentencing decisions demonstrates this point. In State of Wisconsin v Eric L. Loomis, the Court had to assess whether the use of an algorithmic risk assessment tool to determine if the defendant could be supervised within the community rather than detained violated the defendant's right to due process.Footnote 135 As the Court noted,
risk scores are intended to predict the general likelihood that those with a similar history of offending are either less likely or more likely to commit another crime following release from custody. However, the COMPAS risk assessment does not predict the specific likelihood that an individual offender will reoffend. Instead, it provides a prediction based on a comparison of information about the individual to a similar data group.Footnote 136
The defendant challenged the use of the risk assessment tool on the basis that the proprietary interest in the algorithm meant that he could not challenge its ‘scientific validity’Footnote 137 or ‘accuracy’ because Northpointe (the company that owned the algorithm) ‘does not disclose how the risk scores are determined or how the factors are weighed’.Footnote 138 He argued that this denied him ‘an individualized sentence’, and ‘it improperly uses gendered assessments’.Footnote 139
In this case, the Court found that a risk assessment tool could be used to inform a decision, but it could not be determinative.Footnote 140 On its face, this appears to be compatible with IHRL and the ‘red line’ test outlined above. However, the level of scrutiny applied when analysing how the algorithm reached its conclusions must also be addressed to determine if the safeguards were in fact effective.Footnote 141 As noted above, this relates to both the nature of the data inputs and how the algorithm uses that data.
The first key point is that the use of risk assessment tools was considered by the Court as part of a move towards evidence-based sentencing.Footnote 142 Framing risk assessment tools as evidence-based already presents the use of algorithms in decision-making as something more objective than other types of judgments, such as a judge's intuition or a correctional officer's standard practice.Footnote 143 Without entering into a wider discussion on the merits of this approach, it raises the perceived objectivity of algorithmic outcomes which is relevant when considering the risk that judges and other decision-makers might defer to algorithms because they are technologically produced.Footnote 144
Second, the Court acknowledged that a proprietary interest prevented the defendant understanding how the algorithm weighed and analysed the input data.Footnote 145 However, it found that the opportunity to challenge the risk score itself, as well as the input data (as relevant to him) was sufficient,Footnote 146 provided certain safeguards were in place such as information being provided to the Court on whether (1) a cross-validation study had been conducted, (2) the scores ‘raised questions about whether they disproportionately classify minority offenders as having a higher risk of recidivism’, and (3) the tools are ‘monitored and re-normed for accuracy due to changing populations and subpopulations’.Footnote 147 The Court asserted that this would enable courts to ‘better assess the accuracy of the assessment and the appropriate weight to be given to the risk score’.Footnote 148
The information sought by the Court about potential bias appears to introduce levels of scrutiny to how the risk scores will be weighted. However, it provides no indication regarding how this will be conducted in a way that ensures objectivity. It thus potentially undermines the evidence-based approach the Court seeks to achieve.Footnote 149 Moreover, the safeguards only introduce the potential of less weight being given to the risk score rather than excluding it as evidence. They still do not enable the defendant—or another body—to assess how information about him and other persons with similar profiles were weighed and what inferences were made to produce an eventual risk score. Therefore, the Court appeared to consider only the input data and the overall outcome relevant to due process. However, as argued above, the way in which the algorithm itself functions can lead to violations of human rights, and must be addressed.
Thus, even if not determinative, the algorithmic decision in this case had a significant bearing on one of the most important human rights, the right to liberty. This case demonstrates the risk that courts and other bodies may pay an unwarranted level of deference to algorithms, meaning that while a human may be ‘in the loop’, their role in the loop may actually be minimal.Footnote 150 In areas such as sentencing and bail applications, there may be a greater deference to algorithms where actors are concerned about going against the findings of an algorithm, in case they are then blamed if a person released goes on to commit a crime. On one level, this is understandable, as the human decision-maker is unlikely to want to ‘go against the computer’ and then explain their reasoning for doing so should they ‘get it wrong’. However, it is precisely these situations that involve fundamental rights, such as the right to liberty, and that therefore require particular protection.Footnote 151
C. Responsibilities in Areas in Which Algorithmic Effect Is Not Possible to Predict
Finally, the increasing complexity of algorithms and their possible future autonomy may mean that it is difficult for humans to predict the impact they will have. For example, others have asked, ‘[w]hat happens when algorithms write algorithms? Algorithms in the past have been created by a programmer … In the future they will likely be evolved by intelligent/learning machines. We may not even understand where they came from’.Footnote 152 This has resulted in debate over whether humans should have reduced responsibility for the actions of algorithms if humans cannot predict what algorithms will do.Footnote 153 At the conceptualization stage, therefore, actors may claim that they cannot predict whether or not the algorithm will result in human rights interferences or violations.
In these circumstances, the actor is taking the decision to use an algorithm in full knowledge that it cannot predict the effect it will have. From an IHRL perspective, this does not automatically reduce the level of responsibility. This is because human entities (primarily in the form of States or businesses) make the decision to design and deploy algorithms. These actors remain subject to an obligation to ensure that their use of algorithms does not result in human rights violations, even if unintended. Thus, under IHRL, blanket assertions of reduced responsibility would be rejected; if the specific outcome of an algorithmic decision cannot be predicted, the parameters within which a decision is made should nonetheless be clear. For example, if in the conception or design phase actors claim that they cannot predict how the algorithm might perform or anticipate risks that might arise because of the complexity and sophistication of the particular algorithm, this would not reduce responsibility. Rather, if the actor decided to proceed with the use of the algorithm, such a decision might actually result in heightened responsibility. Thus, the IHRL framework pushes back on the developing discourse on reduced human responsibility or distributed responsibility between humans and machines as the starting point.Footnote 154 IHRL responds to this unpredictability by requiring actors to build in human rights protections so that where an algorithm acts unpredictably, safeguards are in place. This includes the proposals by some scientists to explore whether human rights and other ethical principles could be ‘baked into’ the algorithmic process so that the algorithm would act according to these norms and also be capable of alerting the human supervisor to problems.Footnote 155
V. CONCLUSION
Existing approaches to algorithmic accountability are important, but of themselves do not address the full complexity of the issue. IHRL can provide an appropriate framework that takes into account the overall algorithmic life cycle, as well as the differentiated responsibility of all the actors involved. Adopting an IHRL framework can: take advantage of both current and future approaches to prevention, safeguards, monitoring and oversight, and remedy; incorporate broadly accepted understandings as to the conduct that constitutes ‘harm’; and provide guidance with respect to the circumstances in which algorithmic decision-making may be employed. Mapping the algorithmic life cycle against the human rights framework provides clear red lines where algorithms cannot be used, as well as necessary safeguards for ensuring compatibility with human rights. Overall, it strengthens the protections for individuals who are caught in a power imbalance against entities that rely on technologically advanced algorithmic decision-making tools, as it ensures that responsibility is exercised and not deferred.
As stated at the outset, this article is intended to facilitate a discussion as to the role of IHRL in relation to the design, development, and deployment of algorithms, and to provide guidance as to how the IHRL framework can substantively inform this process. Although IHRL does not currently establish binding obligations on business enterprises, it requires States to address third-party harm and establishes clear expectations of businesses, as set out in the UN Guiding Principles on Business and Human Rights, and this area of IHRL continues to evolve. It is these measures that businesses should apply if they are to comply with human rights, and in order to ensure that they ‘do no harm’.
This article has focused on presenting an approach capable of informing the decision-making process – as it relates to the entirety of the algorithmic life cycle – and on providing guidance as to the steps that States and businesses should take to avoid human rights violations. As such, a discussion regarding the role of established human rights mechanisms has been outside the scope of this article. However, these mechanisms can play a critical role in operationalizing existing IHRL so that it makes a contribution and can help shape and address current gaps in algorithmic accountability. Of particular importance at this nascent stage of the discussion are those mechanisms that can help to inform the development of a human rights-based approach and facilitate its incorporation into mainstream discussions. Key in this regard are the Office of the UN High Commissioner for Human Rights and the Special Procedures established by the Human Rights Council. As algorithmic decision-making potentially affects all human rights, a joint statement by a number of UN Treaty Bodies may also be appropriate.Footnote 156 Regional human rights mechanisms and Treaty Bodies will also play an important role in addressing suspected violations arising in this regard, and their case law can assist as regards a deeper and more day-to-day understanding of the human rights law framework. This focus on international mechanisms should not, however, distract from the essential role played by national bodies, such as the independent oversight mechanisms discussed in Part IIIB.
Ultimately, much work remains to be done both to operationalize the IHRL framework and to then ensure that it is applied.

 Open access
Open access