


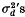 between the neutral and the surrounding over-dominant loci, where
between the neutral and the surrounding over-dominant loci, where 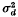 is the squared standard linkage deviation, defined between any two loci by the relation
is the squared standard linkage deviation, defined between any two loci by the relation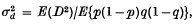

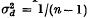 in the first generation, if it is produced by extracting
in the first generation, if it is produced by extracting 
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Kimura, Motoo
1971.
Theoretical foundation of population genetics at the molecular level.
Theoretical Population Biology,
Vol. 2,
Issue. 2,
p.
174.
Ohta, Tomoko
1971.
Associative overdominance caused by linked detrimental mutations.
Genetical Research,
Vol. 18,
Issue. 3,
p.
277.
Sved, J.A.
1972.
Heterosis at the level of the chromosome and at the level of the gene.
Theoretical Population Biology,
Vol. 3,
Issue. 4,
p.
491.
Ohta, Tomoko
and
Kimura, Motoo
1972.
Fixation time of overdominant alleles influenced by random fluctuation of selection intensity.
Genetical Research,
Vol. 20,
Issue. 1,
p.
1.
King, Jack Lester
1972.
Genetic Polymorphisms and Environment.
Science,
Vol. 176,
Issue. 4034,
p.
545.
King, Jack Lester
1972.
Genetic Polymorphisms and Environment.
Science,
Vol. 176,
Issue. 4034,
p.
545.
Ohta, Tomoko
1973.
Effect of linkage on behavior of mutant genes in finite populations.
Theoretical Population Biology,
Vol. 4,
Issue. 2,
p.
145.
Littler, R.A.
1973.
Linkage disequilibrium in two-locus, finite, random mating models without selection or mutation.
Theoretical Population Biology,
Vol. 4,
Issue. 3,
p.
259.
Ohta, Tomoko
and
Cockerham, C. Clark
1974.
Detrimental genes with partial selfing and effects on a neutral locus.
Genetical Research,
Vol. 23,
Issue. 2,
p.
191.
Weir, B.S.
and
Cockerham, C.Clark
1974.
Behavior of pairs of loci in finite monoecious populations.
Theoretical Population Biology,
Vol. 6,
Issue. 3,
p.
323.
Powell, Jeffrey R
1974.
Interaction of genetic loci: the effect of linkage disequilibria on hardy-weinberg expectations.
Heredity,
Vol. 32,
Issue. 2,
p.
151.
Stam, Peter
1975.
Linkage disequilibrium causing selection at a neutral locus in pooled Tribolium populations.
Heredity,
Vol. 34,
Issue. 1,
p.
29.
Powers, Dennis A.
and
Place, Allen R.
1978.
Biochemical genetics of Fundulus heteroclitus (L.). I. Temporal and spatial variation in gene frequencies of Ldh-B, Mdh-A, Gpi-B, and Pgm-A.
Biochemical Genetics,
Vol. 16,
Issue. 5-6,
p.
593.
Barker, J.S.F.
1979.
Inter-locus interactions: A review of experimental evidence.
Theoretical Population Biology,
Vol. 16,
Issue. 3,
p.
323.
Andresen, E.
1979.
Associative Additive Effects of Alleles of theHandPHILoci on the Quality of Meat from Danish Landrace Pigs.
Acta Agriculturae Scandinavica,
Vol. 29,
Issue. 4,
p.
321.
Barton, N. H.
1983.
MULTILOCUS CLINES.
Evolution,
Vol. 37,
Issue. 3,
p.
454.
Singh, R S
and
Morton, R A
1985.
The perturbation ofDrosophila melanogaster esterase-6 allozyme frequencies by selection for malathion resistance.
Journal of Genetics,
Vol. 64,
Issue. 2-3,
p.
111.
Barton, N. H.
1994.
The reduction in fixation probability caused by substitutions at linked loci.
Genetical Research,
Vol. 64,
Issue. 3,
p.
199.
Gillespie, John H.
1997.
Junk ain't what junk does: neutral alleles in a selected context.
Gene,
Vol. 205,
Issue. 1-2,
p.
291.
Gillespie, John H.
1999.
The Role of Population Size in Molecular Evolution.
Theoretical Population Biology,
Vol. 55,
Issue. 2,
p.
145.