
76 results in 94Axx
Convergence rate of entropy-regularized multi-marginal optimal transport costs
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 15 March 2024, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the convergence rate of multi-marginal optimal transport costs that are regularized with the Boltzmann–Shannon entropy, as the noise parameter
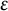 $\varepsilon $ tends to
$\varepsilon $ tends to 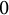 $0$. We establish lower and upper bounds on the difference with the unregularized cost of the form
$0$. We establish lower and upper bounds on the difference with the unregularized cost of the form 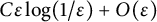 $C\varepsilon \log (1/\varepsilon )+O(\varepsilon )$ for some explicit dimensional constants C depending on the marginals and on the ground cost, but not on the optimal transport plans themselves. Upper bounds are obtained for Lipschitz costs or locally semiconcave costs for a finer estimate, and lower bounds for
$C\varepsilon \log (1/\varepsilon )+O(\varepsilon )$ for some explicit dimensional constants C depending on the marginals and on the ground cost, but not on the optimal transport plans themselves. Upper bounds are obtained for Lipschitz costs or locally semiconcave costs for a finer estimate, and lower bounds for 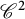 $\mathscr {C}^2$ costs satisfying some signature condition on the mixed second derivatives that may include degenerate costs, thus generalizing results previously in the two marginals case and for nondegenerate costs. We obtain in particular matching bounds in some typical situations where the optimal plan is deterministic.
$\mathscr {C}^2$ costs satisfying some signature condition on the mixed second derivatives that may include degenerate costs, thus generalizing results previously in the two marginals case and for nondegenerate costs. We obtain in particular matching bounds in some typical situations where the optimal plan is deterministic.
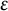
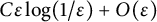
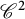
On the Ziv–Merhav theorem beyond Markovianity I
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 07 March 2024, pp. 1-25
-
- Article
- Export citation
Unified bounds for the independence number of graphs
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 11 December 2023, pp. 1-21
-
- Article
- Export citation
t-Design Curves and Mobile Sampling on the Sphere
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 11 / 2023
- Published online by Cambridge University Press:
- 23 November 2023, e105
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In analogy to classical spherical t-design points, we introduce the concept of t-design curves on the sphere. This means that the line integral along a t-design curve integrates polynomials of degree t exactly. For low degrees, we construct explicit examples. We also derive lower asymptotic bounds on the lengths of t-design curves. Our main results prove the existence of asymptotically optimal t-design curves in the Euclidean
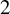 $2$-sphere and the existence of t-design curves in the d-sphere.
$2$-sphere and the existence of t-design curves in the d-sphere.
Approximate discrete entropy monotonicity for log-concave sums
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 13 November 2023, pp. 196-209
-
- Article
- Export citation
-
It is proven that a conjecture of Tao (2010) holds true for log-concave random variables on the integers: For every
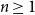 $n \geq 1$, if
$n \geq 1$, if 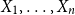 $X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas
$X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas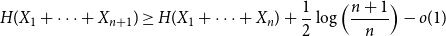 \begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}
\begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}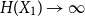 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 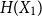 $H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if
$H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if 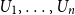 $U_1,\ldots,U_n$ are independent continuous uniforms on
$U_1,\ldots,U_n$ are independent continuous uniforms on 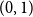 $(0,1)$, thenas
$(0,1)$, thenas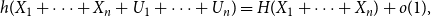 \begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}
\begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}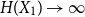 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 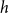 $h$ stands for the differential entropy. Explicit bounds for the
$h$ stands for the differential entropy. Explicit bounds for the 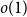 $o(1)$-terms are provided.
$o(1)$-terms are provided.
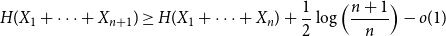
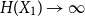
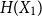
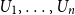
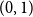
Markov capacity for factor codes with an unambiguous symbol
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 07 November 2023, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The unified extropy and its versions in classical and Dempster–Shafer theories
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 23 October 2023, pp. 1-12
-
- Article
- Export citation
Encoding subshifts through sliding block codes
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 03 August 2023, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove a generalization of Krieger’s embedding theorem, in the spirit of zero-error information theory. Specifically, given a mixing shift of finite type X, a mixing sofic shift Y, and a surjective sliding block code
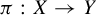 $\pi : X \to Y$, we give necessary and sufficient conditions for a subshift Z of topological entropy strictly lower than that of Y to admit an embedding
$\pi : X \to Y$, we give necessary and sufficient conditions for a subshift Z of topological entropy strictly lower than that of Y to admit an embedding 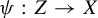 $\psi : Z \to X$ such that
$\psi : Z \to X$ such that 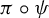 $\pi \circ \psi $ is injective.
$\pi \circ \psi $ is injective.
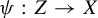
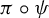
Information-theoretic convergence of extreme values to the Gumbel distribution
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 21 June 2023, pp. 244-254
- Print publication:
- March 2024
-
- Article
- Export citation
On asymptotic fairness in voting with greedy sampling
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 10 May 2023, pp. 999-1032
- Print publication:
- September 2023
-
- Article
- Export citation
Costa’s concavity inequality for dependent variables based on the multivariate Gaussian copula
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 12 April 2023, pp. 1136-1156
- Print publication:
- December 2023
-
- Article
- Export citation
A new lifetime distribution by maximizing entropy: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 28 February 2023, pp. 189-206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random feedback shift registers and the limit distribution for largest cycle lengths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. 559-593
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For a random binary noncoalescing feedback shift register of width
 $n$
, with all
$n$
, with all
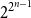 $2^{2^{n-1}}$
possible feedback functions
$2^{2^{n-1}}$
possible feedback functions
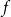 $f$
equally likely, the process of long cycle lengths, scaled by dividing by
$f$
equally likely, the process of long cycle lengths, scaled by dividing by
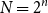 $N=2^n$
, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in
$N=2^n$
, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in
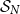 $\mathcal{S}_N$
, with all
$\mathcal{S}_N$
, with all
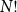 $N!$
possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.
$N!$
possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.

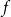
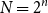
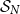
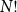
Constant rank factorisations of smooth maps, with applications to sonar
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 35 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 01 December 2022, pp. 1-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A negative binomial approximation in group testing
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 973-996
-
- Article
- Export citation
Fast mixing of a randomized shift-register Markov chain
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 253-266
- Print publication:
- March 2023
-
- Article
- Export citation
-
We present a Markov chain on the n-dimensional hypercube
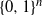 $\{0,1\}^n$
which satisfies
$\{0,1\}^n$
which satisfies
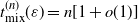 $t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$
. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most
$t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$
. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most
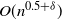 $O(n^{0.5+\delta})$
, where
$O(n^{0.5+\delta})$
, where
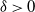 $\delta>0$
. The deterministic moves correspond to a linear shift register.
$\delta>0$
. The deterministic moves correspond to a linear shift register.
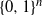
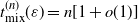
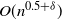
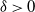
Varentropy of doubly truncated random variable
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 852-871
-
- Article
- Export citation
UNIVERSAL CODING AND PREDICTION ON ERGODIC RANDOM POINTS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 28 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 02 May 2022, pp. 387-412
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Variational model with nonstandard growth conditions for restoration of satellite optical images using synthetic aperture radar
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 34 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 11 March 2022, pp. 77-105
-
- Article
-
- You have access
- HTML
- Export citation
On reconsidering entropies and divergences and their cumulative counterparts: Csiszár's, DPD's and Fisher's type cumulative and survival measures
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 21 February 2022, pp. 294-321
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
