2066 results
Research agenda for transmission prevention within the Veterans Health Administration, 2024–2028
-
- Journal:
- Infection Control & Hospital Epidemiology , First View
- Published online by Cambridge University Press:
- 11 April 2024, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The white grunt, Haemulon plumierii (Lacepède, 1801) as paratenic and definitive host of two acanthocephalan species, with the description of a new species of Dollfusentis (Palaeacanthocephala: Leptohynchoididae) from the Yucatán Peninsula, Mexico
-
- Journal:
- Journal of Helminthology / Volume 98 / 2024
- Published online by Cambridge University Press:
- 08 April 2024, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment of Sleep Quality in Spanish Twin Pregnancy: An Observational Single-Center Study
-
- Journal:
- Twin Research and Human Genetics , First View
- Published online by Cambridge University Press:
- 20 March 2024, pp. 1-8
-
- Article
- Export citation
A multi-shot target-wheel assembly for high-repetition-rate, laser-driven proton acceleration
-
- Journal:
- High Power Laser Science and Engineering / Accepted manuscript
- Published online by Cambridge University Press:
- 12 March 2024, pp. 1-8
-
- Article
-
- You have access
- Open access
- Export citation
Global Governance Confronts the Onslaught of Disinformation
-
- Journal:
- Perspectives on Politics / Volume 22 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 March 2024, pp. 7-10
- Print publication:
- March 2024
-
- Article
- Export citation
Stacking Order in a K/Mg Interstratified Vermiculite from Malawi
-
- Journal:
- Clays and Clay Minerals / Volume 41 / Issue 5 / October 1993
- Published online by Cambridge University Press:
- 28 February 2024, pp. 580-589
-
- Article
- Export citation
Quantification Curves for XRD Analysis of Mixed-Layer 14Å/10Å Clay Minerals
-
- Journal:
- Clays and Clay Minerals / Volume 43 / Issue 2 / April 1995
- Published online by Cambridge University Press:
- 28 February 2024, pp. 246-254
-
- Article
- Export citation
Near-source passive sampling for monitoring viral outbreaks within a university residential setting
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 08 February 2024, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
P135: Electroencephalography-Based Neuro-emotional Responses during interactive scenario therapy in the person with dementia – case study
-
- Journal:
- International Psychogeriatrics / Volume 35 / Issue S1 / December 2023
- Published online by Cambridge University Press:
- 02 February 2024, p. 136
-
- Article
-
- You have access
- Export citation
P134: Immediate stress responses to music during psychomotor stimulation in 2 study cases with dementia.
-
- Journal:
- International Psychogeriatrics / Volume 35 / Issue S1 / December 2023
- Published online by Cambridge University Press:
- 02 February 2024, pp. 135-136
-
- Article
-
- You have access
- Export citation
Let's move forward: Image-computable models and a common model evaluation scheme are prerequisites for a scientific understanding of human vision – CORRIGENDUM
-
- Journal:
- Behavioral and Brain Sciences / Volume 47 / 2024
- Published online by Cambridge University Press:
- 02 February 2024, e66
-
- Article
-
- You have access
- HTML
- Export citation
Parliamentary reaction to the announcement and implementation of the UK Soft Drinks Industry Levy: applied thematic analysis of 2016–2020 parliamentary debates
-
- Journal:
- Public Health Nutrition / Volume 27 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 24 January 2024, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measuring the intangible resources caregivers need to provide nurturing care during the complementary feeding period: a scoping review in low- and lower-middle-income countries
-
- Journal:
- Public Health Nutrition / Volume 27 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 15 January 2024, e78
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improved sleep outcomes and next-day cognitive function in adults following clinical testing of a powder -based drink containing Mulberry leaf extract and a natural source of Tryptophan
-
- Journal:
- Proceedings of the Nutrition Society / Volume 82 / Issue OCE5 / 2023
- Published online by Cambridge University Press:
- 08 January 2024, E350
-
- Article
-
- You have access
- HTML
- Export citation
The association between selenium status and musculoskeletal function in very old adults: The Newcastle 85+ Study
-
- Journal:
- Proceedings of the Nutrition Society / Volume 82 / Issue OCE5 / 2023
- Published online by Cambridge University Press:
- 08 January 2024, E369
-
- Article
-
- You have access
- HTML
- Export citation
The double-burden of functional vitamin B12 deficiency among non-supplemented vegan adults: a systematic review and meta-analysis
-
- Journal:
- Proceedings of the Nutrition Society / Volume 82 / Issue OCE5 / 2023
- Published online by Cambridge University Press:
- 08 January 2024, E362
-
- Article
-
- You have access
- HTML
- Export citation
Editor's Corner
-
- Journal:
- American Antiquity / Volume 89 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 23 January 2024, p. 1
- Print publication:
- January 2024
-
- Article
-
- You have access
- HTML
- Export citation
Reductive Degradation of p,p′-DDT cy Fe(II) in Nontronite NAu-2
-
- Journal:
- Clays and Clay Minerals / Volume 58 / Issue 6 / December 2010
- Published online by Cambridge University Press:
- 01 January 2024, pp. 821-836
-
- Article
- Export citation
Proton and helium ions acceleration in near-critical density gas targets by short-pulse Ti:Sa PW-class laser
- Part of
-
- Journal:
- Journal of Plasma Physics / Volume 89 / Issue 6 / December 2023
- Published online by Cambridge University Press:
- 28 December 2023, 965890601
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The ability to quickly refresh gas-jet targets without cycling the vacuum chamber makes them a promising candidate for laser-accelerated ion experiments at high repetition rate. Here we present results from the first high repetition rate ion acceleration experiment on the VEGA-3 PW-class laser at CLPU. A near-critical density gas-jet target was produced by forcing a 1000 bar H$_2$
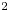 and He gas mix through bespoke supersonic shock nozzles. Proton energies up to 2 MeV were measured in the laser forward direction and 2.2 MeV transversally. He$^{2+}$
and He gas mix through bespoke supersonic shock nozzles. Proton energies up to 2 MeV were measured in the laser forward direction and 2.2 MeV transversally. He$^{2+}$ ions up to 5.8 MeV were also measured in the transverse direction. To help maintain a consistent gas density profile over many shots, nozzles were designed to produce a high-density shock at distances larger than 1 mm from the nozzle exit. We outline a procedure for optimizing the laser–gas interaction by translating the nozzle along the laser axis and using different nozzle materials. Several tens of laser interactions were performed with the same nozzle which demonstrates the potential usefulness of gas-jet targets as high repetition rate particle source.
ions up to 5.8 MeV were also measured in the transverse direction. To help maintain a consistent gas density profile over many shots, nozzles were designed to produce a high-density shock at distances larger than 1 mm from the nozzle exit. We outline a procedure for optimizing the laser–gas interaction by translating the nozzle along the laser axis and using different nozzle materials. Several tens of laser interactions were performed with the same nozzle which demonstrates the potential usefulness of gas-jet targets as high repetition rate particle source.