
82 results
3 Are we Up-Front About Switching or are we Side-Stepping the Issue: Localization of Cognitive Switching Measures with Cortical Thickness
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 29 / Issue s1 / November 2023
- Published online by Cambridge University Press:
- 21 December 2023, p. 608
-
- Article
-
- You have access
- Export citation
53 Are Boys (names) Really Just Like Animals? Comparing Multi-Category Fluency Trials from the D-KEFS in Predicting Temporal Cortical Thickness in an Outpatient Memory Disorders Population
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 29 / Issue s1 / November 2023
- Published online by Cambridge University Press:
- 21 December 2023, pp. 731-732
-
- Article
-
- You have access
- Export citation
46 Comparison of Anxiety Measures in a Memory Clinic Sample
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 29 / Issue s1 / November 2023
- Published online by Cambridge University Press:
- 21 December 2023, pp. 725-726
-
- Article
-
- You have access
- Export citation
The Mopra Southern Galactic Plane CO Survey – data release 4– complete survey
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 40 / 2023
- Published online by Cambridge University Press:
- 22 August 2023, e047
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present observations of the Mopra carbon monoxide (CO) survey of the Southern Galactic Plane, covering Galactic longitudes spanning
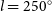 $l = 250^{\circ}$ (
$l = 250^{\circ}$ (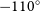 $-110^{\circ}$) to
$-110^{\circ}$) to 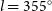 $l = 355^{\circ}$ (
$l = 355^{\circ}$ (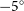 $-5^{\circ}$), with a latitudinal coverage of at least
$-5^{\circ}$), with a latitudinal coverage of at least 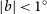 $|b|<1^\circ$, totalling an area of
$|b|<1^\circ$, totalling an area of 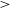 $>$210 deg
$>$210 deg $^{2}$. These data have been taken at 0.6 arcmin spatial resolution and 0.1 km s
$^{2}$. These data have been taken at 0.6 arcmin spatial resolution and 0.1 km s $^{-1}$ spectral resolution, providing an unprecedented view of the molecular gas clouds of the Southern Galactic Plane in the 109–115 GHz
$^{-1}$ spectral resolution, providing an unprecedented view of the molecular gas clouds of the Southern Galactic Plane in the 109–115 GHz 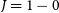 $J = 1-0$ transitions of
$J = 1-0$ transitions of  $^{12}$CO,
$^{12}$CO,  $^{13}$CO, C
$^{13}$CO, C $^{18}$O, and C
$^{18}$O, and C $^{17}$O.
$^{17}$O.
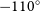
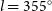
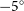
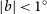






P.063 Physician approaches to the initial management of an intraluminal thrombus in recently symptomatic carotid artery stenosis: results from the Hot Carotid Study
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 50 / Issue s2 / June 2023
- Published online by Cambridge University Press:
- 05 June 2023, pp. S75-S76
-
- Article
-
- You have access
- Export citation
P.067 The decision to revascularize in symptomatic non-stenotic carotid disease: results from the Hot Carotid Qualitative study
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 50 / Issue s2 / June 2023
- Published online by Cambridge University Press:
- 05 June 2023, pp. S76-S77
-
- Article
-
- You have access
- Export citation
Association between saturated fatty acid intake with low density lipoprotein cholesterol and central obesity
-
- Journal:
- Proceedings of the Nutrition Society / Volume 82 / Issue OCE1 / 2023
- Published online by Cambridge University Press:
- 08 March 2023, E28
-
- Article
-
- You have access
- HTML
- Export citation
Are fewer cases of diabetes mellitus diagnosed in the months after SARS-CoV-2 infection? A population-level view in the EHR-based RECOVER program
-
- Journal:
- Journal of Clinical and Translational Science / Volume 7 / Issue 1 / 2023
- Published online by Cambridge University Press:
- 08 March 2023, e90
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WALLABY Pilot Survey: Public release of HI kinematic models for more than 100 galaxies from phase 1 of ASKAP pilot observations
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 39 / 2022
- Published online by Cambridge University Press:
- 15 November 2022, e059
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present the Widefield ASKAP L-band Legacy All-sky Blind surveY (WALLABY) Pilot Phase I Hi kinematic models. This first data release consists of Hi observations of three fields in the direction of the Hydra and Norma clusters, and the NGC 4636 galaxy group. In this paper, we describe how we generate and publicly release flat-disk tilted-ring kinematic models for 109/592 unique Hi detections in these fields. The modelling method adopted here—which we call the WALLABY Kinematic Analysis Proto-Pipeline (WKAPP) and for which the corresponding scripts are also publicly available—consists of combining results from the homogeneous application of the FAT and 3DBarolo algorithms to the subset of 209 detections with sufficient resolution and
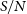 $S/N$
in order to generate optimised model parameters and uncertainties. The 109 models presented here tend to be gas rich detections resolved by at least 3–4 synthesised beams across their major axes, but there is no obvious environmental bias in the modelling. The data release described here is the first step towards the derivation of similar products for thousands of spatially resolved WALLABY detections via a dedicated kinematic pipeline. Such a large publicly available and homogeneously analysed dataset will be a powerful legacy product that that will enable a wide range of scientific studies.
$S/N$
in order to generate optimised model parameters and uncertainties. The 109 models presented here tend to be gas rich detections resolved by at least 3–4 synthesised beams across their major axes, but there is no obvious environmental bias in the modelling. The data release described here is the first step towards the derivation of similar products for thousands of spatially resolved WALLABY detections via a dedicated kinematic pipeline. Such a large publicly available and homogeneously analysed dataset will be a powerful legacy product that that will enable a wide range of scientific studies.
WALLABY pilot survey: Public release of H i data for almost 600 galaxies from phase 1 of ASKAP pilot observations
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 39 / 2022
- Published online by Cambridge University Press:
- 15 November 2022, e058
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present WALLABY pilot data release 1, the first public release of H i pilot survey data from the Wide-field ASKAP L-band Legacy All-sky Blind Survey (WALLABY) on the Australian Square Kilometre Array Pathfinder. Phase 1 of the WALLABY pilot survey targeted three
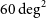 $60\,\mathrm{deg}^{2}$
regions on the sky in the direction of the Hydra and Norma galaxy clusters and the NGC 4636 galaxy group, covering the redshift range of
$60\,\mathrm{deg}^{2}$
regions on the sky in the direction of the Hydra and Norma galaxy clusters and the NGC 4636 galaxy group, covering the redshift range of
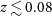 $z \lesssim 0.08$
. The source catalogue, images and spectra of nearly 600 extragalactic H i detections and kinematic models for 109 spatially resolved galaxies are available. As the pilot survey targeted regions containing nearby group and cluster environments, the median redshift of the sample of
$z \lesssim 0.08$
. The source catalogue, images and spectra of nearly 600 extragalactic H i detections and kinematic models for 109 spatially resolved galaxies are available. As the pilot survey targeted regions containing nearby group and cluster environments, the median redshift of the sample of
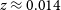 $z \approx 0.014$
is relatively low compared to the full WALLABY survey. The median galaxy H i mass is
$z \approx 0.014$
is relatively low compared to the full WALLABY survey. The median galaxy H i mass is
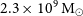 $2.3 \times 10^{9}\,{\rm M}_{{\odot}}$
. The target noise level of
$2.3 \times 10^{9}\,{\rm M}_{{\odot}}$
. The target noise level of
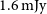 $1.6\,\mathrm{mJy}$
per 30′′ beam and
$1.6\,\mathrm{mJy}$
per 30′′ beam and
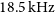 $18.5\,\mathrm{kHz}$
channel translates into a
$18.5\,\mathrm{kHz}$
channel translates into a
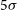 $5 \sigma$
H i mass sensitivity for point sources of about
$5 \sigma$
H i mass sensitivity for point sources of about
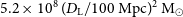 $5.2 \times 10^{8} \, (D_{\rm L} / \mathrm{100\,Mpc})^{2} \, {\rm M}_{{\odot}}$
across 50 spectral channels (
$5.2 \times 10^{8} \, (D_{\rm L} / \mathrm{100\,Mpc})^{2} \, {\rm M}_{{\odot}}$
across 50 spectral channels (
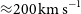 ${\approx} 200\,\mathrm{km \, s}^{-1}$
) and a
${\approx} 200\,\mathrm{km \, s}^{-1}$
) and a
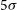 $5 \sigma$
H i column density sensitivity of about
$5 \sigma$
H i column density sensitivity of about
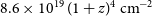 $8.6 \times 10^{19} \, (1 + z)^{4}\,\mathrm{cm}^{-2}$
across 5 channels (
$8.6 \times 10^{19} \, (1 + z)^{4}\,\mathrm{cm}^{-2}$
across 5 channels (
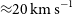 ${\approx} 20\,\mathrm{km \, s}^{-1}$
) for emission filling the 30′′ beam. As expected for a pilot survey, several technical issues and artefacts are still affecting the data quality. Most notably, there are systematic flux errors of up to several 10% caused by uncertainties about the exact size and shape of each of the primary beams as well as the presence of sidelobes due to the finite deconvolution threshold. In addition, artefacts such as residual continuum emission and bandpass ripples have affected some of the data. The pilot survey has been highly successful in uncovering such technical problems, most of which are expected to be addressed and rectified before the start of the full WALLABY survey.
${\approx} 20\,\mathrm{km \, s}^{-1}$
) for emission filling the 30′′ beam. As expected for a pilot survey, several technical issues and artefacts are still affecting the data quality. Most notably, there are systematic flux errors of up to several 10% caused by uncertainties about the exact size and shape of each of the primary beams as well as the presence of sidelobes due to the finite deconvolution threshold. In addition, artefacts such as residual continuum emission and bandpass ripples have affected some of the data. The pilot survey has been highly successful in uncovering such technical problems, most of which are expected to be addressed and rectified before the start of the full WALLABY survey.
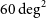
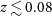
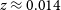
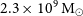
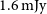
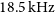
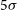
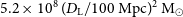
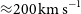
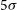
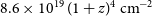
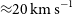
P.062 Physician approaches to anti-thrombotic therapies, imaging and revascularization for acutely symptomatic carotid stenosis: a hot carotid qualitative study
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 49 / Issue s1 / June 2022
- Published online by Cambridge University Press:
- 24 June 2022, pp. S24-S25
-
- Article
-
- You have access
- Export citation
P.065 Physician Approaches to Anti-thrombotic Therapies for Acutely Symptomatic Carotid Stenosis: Insights from the Hot Carotid Qualitative Study
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 48 / Issue s3 / November 2021
- Published online by Cambridge University Press:
- 05 January 2022, p. S37
-
- Article
-
- You have access
- Export citation
P.064 Physician Approaches to Imaging and Revascularization for Acutely Symptomatic Carotid Stenosis: Insights from the Hot Carotid Qualitative Study
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 48 / Issue s3 / November 2021
- Published online by Cambridge University Press:
- 05 January 2022, p. S37
-
- Article
-
- You have access
- Export citation
Replacement of dietary saturated with unsaturated fatty acid has beneficial effects in lowering plasma E-selectin and P-selectin concentrations - Results from the RISSCI-1 study
-
- Journal:
- Proceedings of the Nutrition Society / Volume 80 / Issue OCE5 / 2021
- Published online by Cambridge University Press:
- 27 October 2021, E204
-
- Article
-
- You have access
- HTML
- Export citation
Impact of replacing dietary saturated with unsaturated fats on the expression of genes related to cholesterol metabolism in peripheral blood mononuclear cells: Findings from the RISSCI-1 study
-
- Journal:
- Proceedings of the Nutrition Society / Volume 80 / Issue OCE5 / 2021
- Published online by Cambridge University Press:
- 27 October 2021, E205
-
- Article
-
- You have access
- HTML
- Export citation
Plasma phospholipid fatty acid profiles confirm compliance to the dietary exchange of saturated with unsaturated fat in healthy men using full-fat or lower-fat dairy foods: results from the Reading, Imperial, Surrey, Saturated fat, Cholesterol Intervention (RISSCI) study
-
- Journal:
- Proceedings of the Nutrition Society / Volume 80 / Issue OCE5 / 2021
- Published online by Cambridge University Press:
- 27 October 2021, E177
-
- Article
-
- You have access
- HTML
- Export citation
Measuring subjective stress among young people in Hong Kong: validation and predictive utility of the single-item subjective level of stress (SLS-1) in epidemiological and longitudinal community samples
-
- Journal:
- Epidemiology and Psychiatric Sciences / Volume 30 / 2021
- Published online by Cambridge University Press:
- 08 September 2021, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Story Memory Impairment Rates and Association with Hippocampal Volumes in a Memory Clinic Population
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 28 / Issue 6 / July 2022
- Published online by Cambridge University Press:
- 30 June 2021, pp. 611-619
-
- Article
- Export citation
Dietary pattern analysis reveals key food groups contributing to the successful exchange of saturated with unsaturated fatty acids in healthy men
-
- Journal:
- Proceedings of the Nutrition Society / Volume 79 / Issue OCE3 / 2020
- Published online by Cambridge University Press:
- 19 October 2020, E772
-
- Article
-
- You have access
- HTML
- Export citation
A dietary exchange model to achieve target nutrient intakes in diets high and lower in saturated fatty acids
-
- Journal:
- Proceedings of the Nutrition Society / Volume 79 / Issue OCE3 / 2020
- Published online by Cambridge University Press:
- 19 October 2020, E771
-
- Article
-
- You have access
- HTML
- Export citation
