2 results
The longest common substring problem
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 2 / February 2017
- Published online by Cambridge University Press:
- 29 May 2015, pp. 277-295
-
- Article
- Export citation
-
Given a set
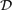 $\mathcal{D}$ of q documents, the Longest Common Substring (LCS) problem asks, for any integer 2 ⩽ k ⩽ q, the longest substring that appears in k documents. LCS is a well-studied problem having a wide range of applications in Bioinformatics: from microarrays to DNA sequences alignments and analysis. This problem has been solved by Hui (2000International Journal of Computer Science and Engineering15 73–76) by using a famous constant-time solution to the Lowest Common Ancestor (LCA) problem in trees coupled with the use of suffix trees.
$\mathcal{D}$ of q documents, the Longest Common Substring (LCS) problem asks, for any integer 2 ⩽ k ⩽ q, the longest substring that appears in k documents. LCS is a well-studied problem having a wide range of applications in Bioinformatics: from microarrays to DNA sequences alignments and analysis. This problem has been solved by Hui (2000International Journal of Computer Science and Engineering15 73–76) by using a famous constant-time solution to the Lowest Common Ancestor (LCA) problem in trees coupled with the use of suffix trees.In this article, we present a simple method for solving the LCS problem by using suffix trees (STs) and classical union-find data structures. In turn, we show how this simple algorithm can be adapted in order to work with other space efficient data structures such as the enhanced suffix arrays (ESA) and the compressed suffix tree.
Fast circular dictionary-matching algorithm
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 2 / February 2017
- Published online by Cambridge University Press:
- 11 May 2015, pp. 143-156
-
- Article
-
- You have access
- Open access
- Export citation
-
Circular string matching is a problem which naturally arises in many contexts. It consists in finding all occurrences of the rotations of a pattern of length m in a text of length n. There exist optimal worst- and average-case algorithms for circular string matching. Here, we present a suboptimal average-case algorithm for circular string matching requiring time
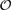 $\mathcal{O}$(n) and space $\mathcal{O}$(m). The importance of our contribution is underlined by the fact that the proposed algorithm can be easily adapted to deal with circular dictionary matching. In particular, we show how the circular dictionary-matching problem can be solved in average-case time $\mathcal{O}$(n + M) and space $\mathcal{O}$(M), where M is the total length of the dictionary patterns, assuming that the shortest pattern is sufficiently long. Moreover, the presented average-case algorithms and other worst-case approaches were also implemented. Experimental results, using real and synthetic data, demonstrate that the implementation of the presented algorithms can accelerate the computations by more than a factor of two compared to the corresponding implementation of other approaches.
$\mathcal{O}$(n) and space $\mathcal{O}$(m). The importance of our contribution is underlined by the fact that the proposed algorithm can be easily adapted to deal with circular dictionary matching. In particular, we show how the circular dictionary-matching problem can be solved in average-case time $\mathcal{O}$(n + M) and space $\mathcal{O}$(M), where M is the total length of the dictionary patterns, assuming that the shortest pattern is sufficiently long. Moreover, the presented average-case algorithms and other worst-case approaches were also implemented. Experimental results, using real and synthetic data, demonstrate that the implementation of the presented algorithms can accelerate the computations by more than a factor of two compared to the corresponding implementation of other approaches.