
1599 results
VaTEST III: Validation of 8 Potential Super-Earths from TESS Data
-
- Journal:
- Publications of the Astronomical Society of Australia / Accepted manuscript
- Published online by Cambridge University Press:
- 11 April 2024, pp. 1-22
-
- Article
- Export citation
-
NASA’s all-sky survey mission, the Transiting Exoplanet Survey Satellite (TESS), is specifically engineered to detect exoplanets that transit bright stars. Thus far, TESS has successfully identified approximately 400 transiting exoplanets, in addition to roughly 6000 candidate exoplanets pending confirmation. In this study, we present the results of our ongoing project, the Validation of Transiting Exoplanets using Statistical Tools (VaTEST). Our dedicated effort is focused on the confirmation and characterization of new exoplanets through the application of statistical validation tools. Through a combination of ground-based telescope data, high-resolution imaging, and the utilization of the statistical validation tool known as TRICERATOPS, we have successfully discovered eight potential super-Earths. These planets bear the designations: TOI-238b (
 R⊕), TOI-771b (
R⊕), TOI-771b ( R⊕), TOI-871b (
R⊕), TOI-871b ( R⊕), TOI-1467b (
R⊕), TOI-1467b ( R⊕), TOI-1739b (
R⊕), TOI-1739b ( R⊕), TOI-2068b (
R⊕), TOI-2068b ( R⊕), TOI-4559b (
R⊕), TOI-4559b (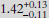 R⊕), and TOI-5799b (
R⊕), and TOI-5799b ( R⊕). Among all these planets, six of them fall within the region known as ’keystone planets,’ which makes them particularly interesting for study. Based on the location of TOI-771b and TOI-4559b below the radius valley we characterized them as likely super-Earths, though radial velocity mass measurements for these planets will provide more details about their characterization. It is noteworthy that planets within the size range investigated herein are absent from our own solar system, making their study crucial for gaining insights into the evolutionary stages between Earth and Neptune.
R⊕). Among all these planets, six of them fall within the region known as ’keystone planets,’ which makes them particularly interesting for study. Based on the location of TOI-771b and TOI-4559b below the radius valley we characterized them as likely super-Earths, though radial velocity mass measurements for these planets will provide more details about their characterization. It is noteworthy that planets within the size range investigated herein are absent from our own solar system, making their study crucial for gaining insights into the evolutionary stages between Earth and Neptune.
 R
R R
R R
R R
R R
R R
R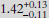 R
R R
REarly auditory processing abnormalities alter individual learning trajectories and sensitivity to computerized cognitive training in schizophrenia
-
- Journal:
- Psychological Medicine , First View
- Published online by Cambridge University Press:
- 08 April 2024, pp. 1-8
-
- Article
- Export citation
The Ukrainian Refugee Crisis and the Politics of Public Opinion: Evidence from Hungary
-
- Journal:
- Perspectives on Politics , First View
- Published online by Cambridge University Press:
- 03 April 2024, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
546 Using Contingency Management to Understand the Cardiovascular, Immune and Psychosocial Benefits of Reduced Cocaine Use: A Protocol for a Randomized Controlled Trial
- Part of
-
- Journal:
- Journal of Clinical and Translational Science / Volume 8 / Issue s1 / April 2024
- Published online by Cambridge University Press:
- 03 April 2024, p. 163
-
- Article
-
- You have access
- Open access
- Export citation
The effect of older age on outcomes of rTMS treatment for treatment-resistant depression
-
- Journal:
- International Psychogeriatrics , First View
- Published online by Cambridge University Press:
- 25 March 2024, pp. 1-6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Retinal microvascular function and incidence and trajectories of clinically relevant depressive symptoms: the Maastricht Study
-
- Journal:
- Psychological Medicine , First View
- Published online by Cambridge University Press:
- 12 March 2024, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying incarceration status in the electronic health record using large language models in emergency department settings
-
- Journal:
- Journal of Clinical and Translational Science / Volume 8 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 11 March 2024, e53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large-scale spatial drivers of avian schistosomes in Northern Michigan inland lakes
-
- Journal:
- Parasitology , First View
- Published online by Cambridge University Press:
- 11 March 2024, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Impact of universal chlorhexidine bathing with or without COVID-19 intensive training on staff and resident COVID-19 case rates in nursing homes
-
- Journal:
- Infection Control & Hospital Epidemiology , First View
- Published online by Cambridge University Press:
- 05 March 2024, pp. 1-4
-
- Article
- Export citation
Partitioning of Binary Solvents on Charged Expandable Clays
-
- Journal:
- Clays and Clay Minerals / Volume 44 / Issue 6 / December 1996
- Published online by Cambridge University Press:
- 28 February 2024, pp. 727-733
-
- Article
- Export citation
Cross-flow instability on a swept-fin cone at Mach 6: characteristics and control
-
- Journal:
- Journal of Fluid Mechanics / Volume 981 / 25 February 2024
- Published online by Cambridge University Press:
- 21 February 2024, A18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Experiments were performed to document the complex flow field around and over a
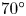 $70^{\circ }$ swept fin mounted on a
$70^{\circ }$ swept fin mounted on a 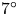 $7^{\circ }$ half-angle right-circular cone in a Mach 6 free-stream. Of particular interest is the turbulent transition of the boundary layer over the swept fin, which is expected to be dominated by a cross-flow instability. Stationary features in the surface temperature distribution over the fin are documented using infrared thermal imaging. These were processed further to determine average spatial Stanton number distributions over the fin. Wavelet analysis of the Stanton number distributions revealed stationary patterns with wavelengths near the fin leading edge that were consistent with linear theory predictions of stationary cross-flow modes. Further from the leading edge, the wavelength of the stationary patterns was observed to increase prior to turbulence onset. Based on these observations, specially designed arrays of discrete roughness elements (DREs) were investigated as a means of delaying turbulence transition with the objective of reducing surface heat flux on the swept fin. The DRE designs followed our previous approach used for cross-flow transition control (Corke et al., J. Fluid Mech., vol. 856, issue 10, 2018, pp. 822–849; Arndt et al., J. Fluid Mech., vol. 887, 2020, A30). These focused on either the shorter wavelengths near the leading edge, or the longer wavelengths that developed near turbulence onset. With regard to delaying transition and reducing the surface heat flux, the DREs that focused on the larger wavelengths of stationary modes were most effective. The fin included an array of pressure sensors that were used to document travelling disturbances that could include those associated with travelling cross-flow modes. Phase analysis of the pressure fluctuation time series was used to determine the wavelength, wave angle and phase speed that were consistent with the travelling cross-flow modes. Cross-bicoherence analysis between the stationary and travelling disturbances indicates a nonlinear phase locking that can account for the development of the longer-wavelength stationary features in the surface heat flux, presumed to be due to stationary cross-flow modes, prior to turbulence onset.
$7^{\circ }$ half-angle right-circular cone in a Mach 6 free-stream. Of particular interest is the turbulent transition of the boundary layer over the swept fin, which is expected to be dominated by a cross-flow instability. Stationary features in the surface temperature distribution over the fin are documented using infrared thermal imaging. These were processed further to determine average spatial Stanton number distributions over the fin. Wavelet analysis of the Stanton number distributions revealed stationary patterns with wavelengths near the fin leading edge that were consistent with linear theory predictions of stationary cross-flow modes. Further from the leading edge, the wavelength of the stationary patterns was observed to increase prior to turbulence onset. Based on these observations, specially designed arrays of discrete roughness elements (DREs) were investigated as a means of delaying turbulence transition with the objective of reducing surface heat flux on the swept fin. The DRE designs followed our previous approach used for cross-flow transition control (Corke et al., J. Fluid Mech., vol. 856, issue 10, 2018, pp. 822–849; Arndt et al., J. Fluid Mech., vol. 887, 2020, A30). These focused on either the shorter wavelengths near the leading edge, or the longer wavelengths that developed near turbulence onset. With regard to delaying transition and reducing the surface heat flux, the DREs that focused on the larger wavelengths of stationary modes were most effective. The fin included an array of pressure sensors that were used to document travelling disturbances that could include those associated with travelling cross-flow modes. Phase analysis of the pressure fluctuation time series was used to determine the wavelength, wave angle and phase speed that were consistent with the travelling cross-flow modes. Cross-bicoherence analysis between the stationary and travelling disturbances indicates a nonlinear phase locking that can account for the development of the longer-wavelength stationary features in the surface heat flux, presumed to be due to stationary cross-flow modes, prior to turbulence onset.
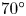
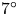
Salvage treatments for barnyardgrass (Echinochloa crus-galli) control in rice following simulated failed herbicide application
-
- Journal:
- Weed Technology / Volume 38 / 2024
- Published online by Cambridge University Press:
- 31 January 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Just as Essential: The Mental Health of Educators During the COVID-19 Pandemic
-
- Journal:
- Disaster Medicine and Public Health Preparedness / Volume 18 / 2024
- Published online by Cambridge University Press:
- 18 January 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Meso-level planning for mine closure and transition: How do we optimise closure benefits and minimise risk at the regional scale?
-
- Journal:
- Research Directions: Mine closure and transitions / Volume 1 / 2024
- Published online by Cambridge University Press:
- 10 January 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Physical activity and sedentary time after lifestyle interventions at the Norwegian Healthy Life Centres
-
- Journal:
- Primary Health Care Research & Development / Volume 25 / 2024
- Published online by Cambridge University Press:
- 08 January 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Increasing the equitability of data citation in paleontology: capacity building for the big data future
-
- Journal:
- Paleobiology , First View
- Published online by Cambridge University Press:
- 28 December 2023, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Palmer amaranth (Amaranthus palmeri) control affected by weed size and herbicide spray solution with nozzle type pairings
-
- Journal:
- Weed Technology / Volume 38 / 2024
- Published online by Cambridge University Press:
- 22 December 2023, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ten New Insights in Climate Science 2023/2024
-
- Journal:
- Global Sustainability / Accepted manuscript
- Published online by Cambridge University Press:
- 01 December 2023, pp. 1-58
-
- Article
-
- You have access
- Open access
- Export citation
The Association Between Civil Legal Needs After Incarceration, Psychosocial Stress, and Cardiovascular Disease Risk Factors
-
- Journal:
- Journal of Law, Medicine & Ethics / Volume 51 / Issue 4 / Winter 2023
- Published online by Cambridge University Press:
- 13 March 2024, pp. 856-864
- Print publication:
- Winter 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Peach tree response to low dosages of dicamba as repeated application or with various spray nozzles
-
- Journal:
- Weed Technology / Volume 38 / 2024
- Published online by Cambridge University Press:
- 29 November 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
