


I. INTRODUCTION
Our digital age has witnessed a soaring demand for flexible, high-quality portrait manipulation, not only from smart-phone apps but also from photography industry, e-commerce, and movie production, etc. Portrait manipulation is a widely studied topic [Reference Averbuch-Elor, Cohen-Or, Kopf and Cohen1–Reference Thies, Zollhofer, Stamminger, Theobalt and Nießner6] in computer vision and computer graphics. From another perspective, many computer vision problems can be seen as translating image from one domain (modality) to another, such as colorization [Reference Levin, Lischinski and Weiss7], style transfer [Reference Gatys, Ecker and Bethge8–Reference Luan, Paris, Shechtman and Bala11], image inpainting [Reference Bertalmio, Sapiro, Caselles and Ballester12], and visual attribute transfer [Reference Liao, Yao, Yuan, Hua and Kang13], etc. This cross-modality image-to-image translation has received significant attention [Reference Isola, Zhu, Zhou and Efros14, Reference Zhu, Park, Isola and Efros15] in the community. In this paper, we define different styles as modalities and try to address multi-modality transfer using a single model. In terms of practical concern, transfer between each pair of modalities as opposed to SPADE [Reference Park, Liu, Wang and Zhu16] or GANPaint [Reference Bau17] whose manipulation domain is fixed.
Recently, generative adversarial networks have demonstrated compelling effects in synthesis and image translation [Reference Isola, Zhu, Zhou and Efros14, Reference Zhu, Park, Isola and Efros15, Reference Chen and Koltun18–Reference Yang, Lu, Lin, Shechtman, Wang and Li21], among which [Reference Zhu, Park, Isola and Efros15, Reference Yi, Zhang, Tan and Gong22] proposed cycle-consistency for unpaired image translation. In this paper, we extend this idea into a conditional setting by leveraging additional facial landmarks information, which is capable of capturing intricate expression changes. Benefits that arise with this simple yet effective modifications include: First, cycle mapping can effectively prevent many-to-one mapping [Reference Zhu, Park, Isola and Efros15, Reference Zhu23] also known as mode-collapse. In the context of face/pose manipulation, cycle-consistency also induces identity preserving and bidirectional manipulation, whereas previous method [Reference Averbuch-Elor, Cohen-Or, Kopf and Cohen1] assumes neutral face to begin with or is unidirectional [Reference Ma, Jia, Sun, Schiele, Tuytelaars and Van Gool24, Reference Pumarola, Agudo, Sanfeliu and Moreno-Noguer25], manipulating in the same domain. Second, face images of different textures or styles are considered different modalities and current landmark detector will not work on those stylized images. With our design, we can pair samples from multiple domains and translate between each pair of them, thus enabling landmark extraction indirectly on stylized portraits. Our framework can also be extended to makeups/de-makeups, aging manipulation, etc., once corresponding data are collected. In this work, we leverage [Reference Johnson, Alahi and Fei-Fei10] to generate pseudo-targets, i.e. stylized faces to learn simultaneous expression and modality manipulations, but it can be replaced with any desired target domains.
However, there remain two main challenges to achieve high-quality portrait manipulation. We propose to learn a single generator $G$ as in [Reference Choi, Choi, Kim, Ha, Kim and Choo26]. But StarGAN [Reference Choi, Choi, Kim, Ha, Kim and Choo26] deals with discrete manipulation and fails on high-resolution images with irremovable artifacts. To synthesize images of photo-realistic quality ($512\times 512$
as in [Reference Choi, Choi, Kim, Ha, Kim and Choo26]. But StarGAN [Reference Choi, Choi, Kim, Ha, Kim and Choo26] deals with discrete manipulation and fails on high-resolution images with irremovable artifacts. To synthesize images of photo-realistic quality ($512\times 512$ ), we propose multi-level adversarial supervision inspired by [Reference Wang, Liu, Zhu, Tao, Kautz and Catanzaro27, Reference Zhang28] where synthesized images at different resolution are propagated and combined before being fed into multi-level discriminators. Second, to avoid texture inconsistency and artifacts during translation between different domains, we integrate Gram matrix [Reference Gatys, Ecker and Bethge8] as a measure of texture distance into our model as it is differentiable and can be trained end-to-end using back propagation. Figure 1 shows the result of our model.
), we propose multi-level adversarial supervision inspired by [Reference Wang, Liu, Zhu, Tao, Kautz and Catanzaro27, Reference Zhang28] where synthesized images at different resolution are propagated and combined before being fed into multi-level discriminators. Second, to avoid texture inconsistency and artifacts during translation between different domains, we integrate Gram matrix [Reference Gatys, Ecker and Bethge8] as a measure of texture distance into our model as it is differentiable and can be trained end-to-end using back propagation. Figure 1 shows the result of our model.

Fig. 1. More results for continuous shape edits and simultaneous shape and modality manipulation results by PortraitGAN.
Extensive evaluations have shown both quantitatively and qualitatively that our method is comparable or superior to state-of-the-art generative models in performing high-quality portrait manipulation. Our model is bidirectional, which circumvents the need to start from a neutral face or a fixed domain. This feature also ensures stable training, identity preservation, and is easily scalable to other desired domain manipulations. In the following section, we review related works to ours and point out the differences. Details of PortraitGAN are elaborated in Section III. We evaluate our approach in Section IV and conclude the paper in Section V.
II. RELATED WORK
Face editing
Face editing or manipulation is a widely studied area in the field of computer vision and graphics, including face morphing [Reference Blanz and Vetter29], expression edits [Reference Lau, Chai, Xu and Shum30, Reference Sucontphunt, Mo, Neumann and Deng31], age progression [Reference Kemelmacher-Shlizerman, Suwajanakorn and Seitz32], facial reenactment [Reference Averbuch-Elor, Cohen-Or, Kopf and Cohen1, Reference Thies, Zollhofer, Stamminger, Theobalt and Nießner6, Reference Blanz, Basso, Poggio and Vetter33]. However, these models are designed for a particular task and rely heavily on domain knowledge and certain assumptions. For example, [Reference Averbuch-Elor, Cohen-Or, Kopf and Cohen1] assumes neutral and frontal faces to begin with while [Reference Thies, Zollhofer, Stamminger, Theobalt and Nießner6] employs 3D model and assumes the availability of target videos with variation in both poses and expressions. Our model differs from them as it is a data-driven approach that does not require domain knowledge, designed to handle general face manipulations.
Image translation
Our work can be categorized into image translation with generative adversarial networks [Reference Isola, Zhu, Zhou and Efros14, Reference Chen and Koltun18, Reference Yi, Zhang, Tan and Gong22, Reference Wang, Liu, Zhu, Tao, Kautz and Catanzaro27, Reference Hoffman34, Reference Liu, Breuel and Kautz35], whose goal is to learn a mapping $G:\mathcal {X} \rightarrow \widehat {\mathcal {Y}}$ that induces an indistinguishable distribution to target domain $\mathcal {Y}$
that induces an indistinguishable distribution to target domain $\mathcal {Y}$ , through adversarial training. For example, Isola et al. [Reference Isola, Zhu, Zhou and Efros14] take image as a condition for general image-to-image translation trained on paired samples. Later, Zhu et al. [Reference Zhu, Park, Isola and Efros15] build upon [Reference Isola, Zhu, Zhou and Efros14] by introducing cycle-consistency loss to obviate the need of matched training pairs. In addition, it alleviates many-to-one mapping during training generative adversarial networks also known as mode collapse. Inspired by this, we integrate this loss into our model for identity preservation between different domains.
, through adversarial training. For example, Isola et al. [Reference Isola, Zhu, Zhou and Efros14] take image as a condition for general image-to-image translation trained on paired samples. Later, Zhu et al. [Reference Zhu, Park, Isola and Efros15] build upon [Reference Isola, Zhu, Zhou and Efros14] by introducing cycle-consistency loss to obviate the need of matched training pairs. In addition, it alleviates many-to-one mapping during training generative adversarial networks also known as mode collapse. Inspired by this, we integrate this loss into our model for identity preservation between different domains.
Another seminal work that inspired our design is StarGAN [Reference Choi, Choi, Kim, Ha, Kim and Choo26], where target facial attributes are encoded into a one-hot vector. In StarGAN, each attribute is treated as a different domain and an auxiliary classifier used to distinguish these attributes is essential for supervising the training process. Different from StarGAN, our goal is to perform continuous edits in the pixel space that cannot be enumerated with discrete labels. This implicitly implies a smooth and continuous latent space where each point in this space encodes meaningful axis of variation in the data. We treat different style modalities as domains in this paper and use two words interchangeably. In this sense, applications like beautification/de-beautification, aging/younger, with beard/without beard can also be included into our general framework. We compare our approach against CycleGAN [Reference Zhu, Park, Isola and Efros15] and StarGAN [Reference Choi, Choi, Kim, Ha, Kim and Choo26] during experiments and illustrate in more details about our design in the next section.
Landmark guided generation
In [Reference Qian36], an offline interpolation process is adopted for generating face boundary map, to be used for GMM clustering and as conditional prior. There are two key differences: (1) the number of new expressions depends on clustering, possibly not continuous; (2) boundary heat map is estimated offline. In [Reference Wang, Alameda-Pineda, Xu, Fua, Ricci and Sebe37], facial landmarks are represented as VAE encoding for GAN. In contrast, the major goal of our framework is to support online, flexible, even interactive in user experience, which is why we process and leverage landmarks in a different way, as a channel map.
There are also works that use pose landmarks as condition for person image generation [Reference Pumarola, Agudo, Sanfeliu and Moreno-Noguer25, Reference Lassner, Pons-Moll and Gehler38–Reference Walker, Marino, Gupta and Hebert40]. For example, [Reference Ma, Jia, Sun, Schiele, Tuytelaars and Van Gool24] concatenates one-hot pose feature maps in a channel-wise fashion to control pose generation. Different from our approach, each landmark constitutes one channel. In [Reference Reed, Akata, Mohan, Tenka, Schiele and Lee41], keypoints and segmentation mask of birds are used to manipulate locations and poses of birds. To synthesize more plausible human poses, Siarohin et.al [Reference Siarohin, Sangineto, Lathuiliere and Sebe39] develop deformable skip connections and compute a set of affine transformations to approximate joint deformations. These works share some similarity with ours as both facial landmark and human skeleton can be seen as a form of pose representation. However, the above works deal with manipulation in the original domain and does not preserve identity.
Style transfer
Exemplar-guided neural style transfer was first proposed by Gatys et al. [Reference Gatys, Ecker and Bethge8]. The idea is to preserve content from the original image and mimic “style” from a reference image. We adopt Gram matrix in our model to enforce pattern consistency. We apply a fast neural-style transfer algorithm [Reference Johnson, Alahi and Fei-Fei10] to generate pseudo targets for multi-modality manipulations. Another branch of work [Reference Park, Liu, Wang and Zhu16, Reference Choi, Uh, Yoo and Ha42] try to model style distribution in another domain which is in favor of one-to-many mapping in the target domain, or collection style transfer [Reference Huang, Liu, Belongie and Kautz43].
III. PROPOSED METHOD
Problem formulation
Given domains $\mathcal {X}_{1}, \mathcal {X}_{2}, \mathcal {X}_{3},\ldots , \mathcal {X}_{n}$ of different modalities, our goal is to learn a single general mapping function
of different modalities, our goal is to learn a single general mapping function

that transforms $\mathcal {I}_{A}$ from domain $A$
from domain $A$ to $\mathcal {I}_{B}$
to $\mathcal {I}_{B}$ from domain $B$
from domain $B$ in a continuous manner. Equation 1 implicitly implies that $G$
in a continuous manner. Equation 1 implicitly implies that $G$ is bidirectional given desired conditions. We use facial landmark $\mathcal {L}_{j}\in R^{1\times H\times W}$
is bidirectional given desired conditions. We use facial landmark $\mathcal {L}_{j}\in R^{1\times H\times W}$ to denote facial expression in domain $j$
to denote facial expression in domain $j$ . Facial expressions are represented as a vector of 2D keypoints with $N=68$
. Facial expressions are represented as a vector of 2D keypoints with $N=68$ , where each point $u_{i}=(x_{i}, y_{i})$
, where each point $u_{i}=(x_{i}, y_{i})$ is the $i$
is the $i$ th pixel location in $\mathcal {L}_{j}$
th pixel location in $\mathcal {L}_{j}$ . We use attribute vector $\overline {c}=[c_{1},c_{2},c_{3},\ldots ,c_{n}]$
. We use attribute vector $\overline {c}=[c_{1},c_{2},c_{3},\ldots ,c_{n}]$ to represent the target domain. Formally, our input/output are tuples of the form $(\mathcal {I}_{A},\mathcal {L}_{B},c_{B})/ (\mathcal {I}_{B},\mathcal {L}_{A},c_{A}) \in R^{(3+1+n)\times H\times W}$
to represent the target domain. Formally, our input/output are tuples of the form $(\mathcal {I}_{A},\mathcal {L}_{B},c_{B})/ (\mathcal {I}_{B},\mathcal {L}_{A},c_{A}) \in R^{(3+1+n)\times H\times W}$ .
.
Model architecture
The overall pipeline of our approach is straightforward, shown in Fig. 2 consisting of three main components: (1) A generator $G(\mathcal {I}, \mathcal {L},\overline {c})$ , which renders an input face in domain $\overline {c_{1}}$
, which renders an input face in domain $\overline {c_{1}}$ to the same person in another domain $\overline {c_{2}}$
to the same person in another domain $\overline {c_{2}}$ given conditional facial landmarks. $G$
given conditional facial landmarks. $G$ is bidirectional and reused in both forward as well as backward cycle. First mapping $\mathcal {I}_{A}\rightarrow \widehat {\mathcal {I}_{B}}\rightarrow \widehat {\mathcal {I}_{A}}$
is bidirectional and reused in both forward as well as backward cycle. First mapping $\mathcal {I}_{A}\rightarrow \widehat {\mathcal {I}_{B}}\rightarrow \widehat {\mathcal {I}_{A}}$ and then mapping back $\mathcal {I}_{B}\rightarrow \widehat {\mathcal {I}_{A}}\rightarrow \widehat {\mathcal {I}_{B}}$
and then mapping back $\mathcal {I}_{B}\rightarrow \widehat {\mathcal {I}_{A}}\rightarrow \widehat {\mathcal {I}_{B}}$ given conditional pair $(\mathcal {L}_{B}, \overline {c_{B}})/(\mathcal {L}_{A}, \overline {c_{A}})$
given conditional pair $(\mathcal {L}_{B}, \overline {c_{B}})/(\mathcal {L}_{A}, \overline {c_{A}})$ . (2) A set of discriminators $D_{i}$
. (2) A set of discriminators $D_{i}$ at different levels of resolution that distinguish generated samples from real ones. Instead of mapping $\mathcal {I}$
at different levels of resolution that distinguish generated samples from real ones. Instead of mapping $\mathcal {I}$ to a single scalar which signifies “real” or “fake”, we adopt PatchGAN [Reference Huang and Belongie9] which uses a fully convnet that outputs a matrix where each element $M_{i,j}$
to a single scalar which signifies “real” or “fake”, we adopt PatchGAN [Reference Huang and Belongie9] which uses a fully convnet that outputs a matrix where each element $M_{i,j}$ represents the probability of overlapping patch $ij$
represents the probability of overlapping patch $ij$ to be real. If we trace back to the original image, each output has a $70\times 70$
to be real. If we trace back to the original image, each output has a $70\times 70$ receptive field. (3) Our loss function takes into account identity preservation and texture consistency between different domains. In the following sections, we elaborate on each module individually and then combine them together to construct PortraitGAN.
receptive field. (3) Our loss function takes into account identity preservation and texture consistency between different domains. In the following sections, we elaborate on each module individually and then combine them together to construct PortraitGAN.
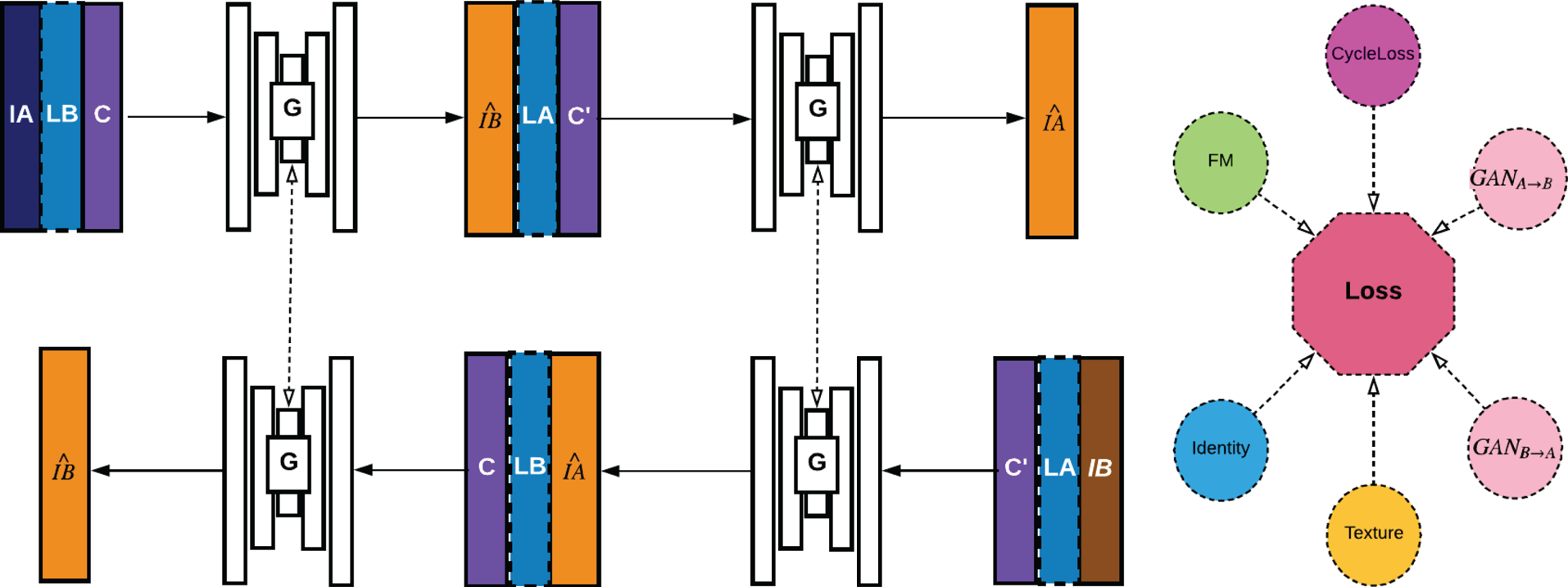
Fig. 2. Overview of training pipeline: In the forward cycle, original image $IA$ is first translated to $\widehat {IB}$
is first translated to $\widehat {IB}$ given target emotion $LB$
given target emotion $LB$ and modality $C$
and modality $C$ and then mapped back to $\widehat {IA}$
and then mapped back to $\widehat {IA}$ given condition pair ($LA$
given condition pair ($LA$ ,$C'$
,$C'$ ) encoding the original image. The backward cycle follows similar manner starting from $IB$
) encoding the original image. The backward cycle follows similar manner starting from $IB$ but with opposite condition encodings using the same generator $G$
but with opposite condition encodings using the same generator $G$ . Identity preservation and modality constraints are explicitly modeled in our loss design.
. Identity preservation and modality constraints are explicitly modeled in our loss design.
A) Base model
To begin with, we consider manipulation of emotions in the same domain, i.e. $\mathcal {I}_A$ and $\mathcal {I}_B$
and $\mathcal {I}_B$ are of same texture and style, but with different face shapes denoted by facial landmarks $\mathcal {L}_A$
are of same texture and style, but with different face shapes denoted by facial landmarks $\mathcal {L}_A$ and $\mathcal {L}_B$
and $\mathcal {L}_B$ . Under this scenario, it is sufficient to incorporate only forward cycle and conditional modality vector is not needed. The adversarial loss conditioned on facial landmarks follows equation 2.
. Under this scenario, it is sufficient to incorporate only forward cycle and conditional modality vector is not needed. The adversarial loss conditioned on facial landmarks follows equation 2.

A face verification loss is desired to preserve identity between $\mathcal {I}_B$ and $\widehat {\mathcal {I}_B}=G(\mathcal {I}_A,\mathcal {L}_B)$
and $\widehat {\mathcal {I}_B}=G(\mathcal {I}_A,\mathcal {L}_B)$ . However, in our experiments, we find $\ell _1$
. However, in our experiments, we find $\ell _1$ loss to be enough and it is better than $\ell _2$
loss to be enough and it is better than $\ell _2$ loss as it alleviates blurry output and acts as an additional regularization [Reference Isola, Zhu, Zhou and Efros14].
loss as it alleviates blurry output and acts as an additional regularization [Reference Isola, Zhu, Zhou and Efros14].

The overall loss is a combination of adversarial loss and $\ell _1$ loss, weighted by $\lambda$
loss, weighted by $\lambda$ .
.

B) Multi-level adversarial supervision
Manipulation at a landmark level requires high-resolution synthesis, which is challenging [Reference Goodfellow44], because it is harder to optimize.
Here we use two strategies for improving generation quality and training stability. First our conditional facial landmark acts as an additional constraint for generation. Second, we adopt a multi-level feature matching loss [Reference Gatys, Ecker and Bethge8, Reference Salimans, Goodfellow, Zaremba, Cheung, Radford and Chen45] to explicitly require $G$ to match statistics of real data that $D$
to match statistics of real data that $D$ finds most discriminative at feature level as follows.
finds most discriminative at feature level as follows.

we denote the ith-layer feature extractor of discriminator $D_k$ as $D_k^{i}$
as $D_k^{i}$ , where T is the total number of layers and $N_{i}$
, where T is the total number of layers and $N_{i}$ denotes the number of elements in each layer.
denotes the number of elements in each layer.
Third, we provide fine-grained guidance by propagating multi-level features for adversarial supervision (Fig. 3). Cascaded upsampling layers in $G$ are connected with auxiliary convolutional branches to provide images at different scales ($\widehat {\mathcal {I}_{B1}},\widehat {\mathcal {I}_{B2}},\widehat {\mathcal {I}_{B3}}\ldots \widehat {\mathcal {I}_{Bm}}$
are connected with auxiliary convolutional branches to provide images at different scales ($\widehat {\mathcal {I}_{B1}},\widehat {\mathcal {I}_{B2}},\widehat {\mathcal {I}_{B3}}\ldots \widehat {\mathcal {I}_{Bm}}$ ), where $m$
), where $m$ is the number of upsampling blocks. These images are fed into discriminators at different scales $D_{k}$
is the number of upsampling blocks. These images are fed into discriminators at different scales $D_{k}$ . Applying it to equation 4 we get,
. Applying it to equation 4 we get,

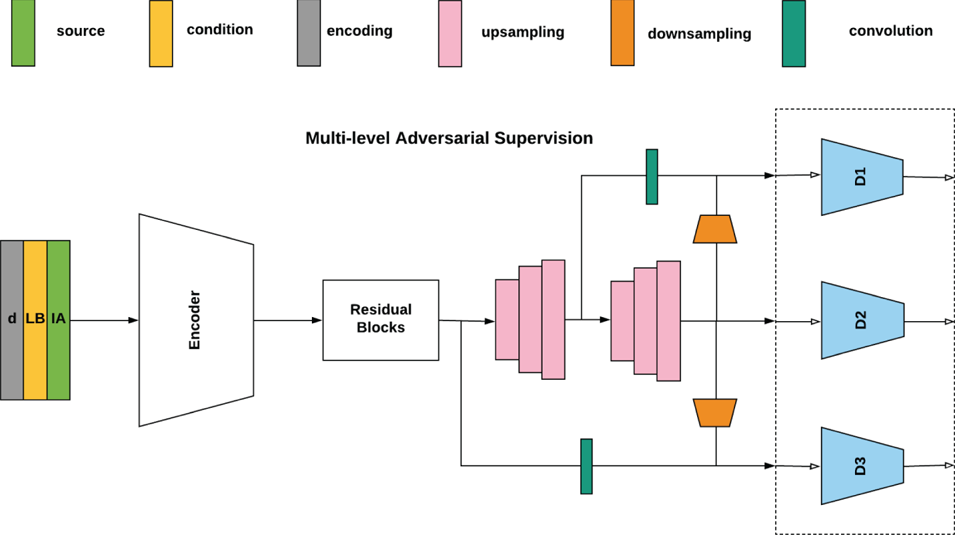
Fig. 3. Multi-level adversarial supervision.
Compared to [Reference Zhang28], our proposed discriminators responsible for different levels are optimized as a whole rather than individually for each level. The increased discriminative ability from $D_k$ in turn provides further guidance when training $G$
in turn provides further guidance when training $G$ (equation 6).
(equation 6).
C) Texture consistency
When translating between different modalities in high-resolution, texture differences become easy to observe. Inspired by [Reference Gatys, Ecker and Bethge8], we let $\psi _{\mathcal {I},L}^{k}$ be the vectorized $k$
be the vectorized $k$ th extracted feature map of image $\mathcal {I}$
th extracted feature map of image $\mathcal {I}$ from neural network $\psi$
from neural network $\psi$ at layer $L$
at layer $L$ . $\mathcal {G}_{\mathcal {I},L} \in R^{\kappa \times \kappa }$
. $\mathcal {G}_{\mathcal {I},L} \in R^{\kappa \times \kappa }$ is defined as,
is defined as,

where $\kappa$ is the number of feature maps at layer $L$
is the number of feature maps at layer $L$ and $\psi _{\mathcal {I},L}^{k}(i)$
and $\psi _{\mathcal {I},L}^{k}(i)$ is $i$
is $i$ th element in the feature vector. Equation 7 also known as Gram matrix can be seen as a measure of the correlation between feature maps $k$
th element in the feature vector. Equation 7 also known as Gram matrix can be seen as a measure of the correlation between feature maps $k$ and $l$
and $l$ , which only depends on the number of feature maps, not the size of $\mathcal {I}$
, which only depends on the number of feature maps, not the size of $\mathcal {I}$ . For image $\mathcal {I}_A$
. For image $\mathcal {I}_A$ and $\mathcal {I}_B$
and $\mathcal {I}_B$ , the texture loss at layer $L$
, the texture loss at layer $L$ is,
is,

where $\widehat {\mathcal {I}_B}=G(\mathcal {I}_A,\mathcal {L}_B)$ . We obtain obvious improvement in quality of texture in cross-modality generation and we use pretrained VGG19 for texture feature extraction in our experiments with its parameters frozen during optimization.
. We obtain obvious improvement in quality of texture in cross-modality generation and we use pretrained VGG19 for texture feature extraction in our experiments with its parameters frozen during optimization.
D) Bidirectional portrait manipulation
To transfer to a target domain $\mathcal {X}$ , an additional one-hot encoding vector $\overline {c}\in R^{n}$
, an additional one-hot encoding vector $\overline {c}\in R^{n}$ is conditioned as input. Specifically, each element is first replicated spatially into size $H\times W$
is conditioned as input. Specifically, each element is first replicated spatially into size $H\times W$ and then concatenated with image and landmark along the channel axis. The only change to previous equations is that instead of taking $(\mathcal {I}_A,\mathcal {L}_B)$
and then concatenated with image and landmark along the channel axis. The only change to previous equations is that instead of taking $(\mathcal {I}_A,\mathcal {L}_B)$ as input, the generator $G$
as input, the generator $G$ now takes $(\mathcal {I}_A,\mathcal {L}_B,\overline {c})$
now takes $(\mathcal {I}_A,\mathcal {L}_B,\overline {c})$ , where $\overline {c}$
, where $\overline {c}$ indicates the domain where $\mathcal {I}_B$
indicates the domain where $\mathcal {I}_B$ belongs to.
belongs to.
To encourage bijection between mappings in different modality manifold and to prevent mode collapse, we adopt cycle-consistency structure similar to [Reference Zhu, Park, Isola and Efros15], which consists of a forward and a backward cycle, for both generating directions.

where $\overline {c}$ and $\overline {c}'$
and $\overline {c}'$ encodes modality for $\mathcal {I}_B$
encodes modality for $\mathcal {I}_B$ and $\mathcal {I}_A$
and $\mathcal {I}_A$ respectively. Note that only one set of generator/discriminator is used for bidirectional manipulation. Our final optimization objective for PortraitGAN is as follows,
respectively. Note that only one set of generator/discriminator is used for bidirectional manipulation. Our final optimization objective for PortraitGAN is as follows,

where $\alpha$ ,$\eta$
,$\eta$ controls the weight for cycle-consistency loss and texture loss respectively.
controls the weight for cycle-consistency loss and texture loss respectively.
IV. EXPERIMENTAL EVALUATION
Our goal in this section is to test our model's capability in (1) continuous shape editing; (2) simultaneous modality transfer. We also created testbed for comparing our model against two closely related SOTA methods [Reference Zhu, Park, Isola and Efros15, Reference Choi, Choi, Kim, Ha, Kim and Choo26], though they do not support either continuous shape editing and multi-modality transfer directly. The aim is to provide quantitative and qualitative analysis in terms of perceptual quality. Additionally, we also conducted ablation studies for our components.
Implementation details
Each training step takes as input a tuple of four images $(\mathcal {I}_{A}$ , $\mathcal {I}_{B}$
, $\mathcal {I}_{B}$ , $\mathcal {L}_{A}$
, $\mathcal {L}_{A}$ , $\mathcal {L}_{B})$
, $\mathcal {L}_{B})$ randomly chosen from possible modalities of the same identity. Attribute conditional vector, represented as a one-hot vector, is replicated spatially before channel-wise concatenation with corresponding image and facial landmarks. Our generator uses 4 stride-2 convolution layers, followed by nine residual blocks and 4 stride-2 transpose convolutions while auxiliary branch uses one-channel convolution for fusion of channels. We use two three-layer PatchGAN [Reference Huang and Belongie9] discriminators for multi-level adversarial supervision and Least Square loss [Reference Mao, Li, Xie, Lau, Wang and Smolley46] for stable training. Layer conv$1\_1$
randomly chosen from possible modalities of the same identity. Attribute conditional vector, represented as a one-hot vector, is replicated spatially before channel-wise concatenation with corresponding image and facial landmarks. Our generator uses 4 stride-2 convolution layers, followed by nine residual blocks and 4 stride-2 transpose convolutions while auxiliary branch uses one-channel convolution for fusion of channels. We use two three-layer PatchGAN [Reference Huang and Belongie9] discriminators for multi-level adversarial supervision and Least Square loss [Reference Mao, Li, Xie, Lau, Wang and Smolley46] for stable training. Layer conv$1\_1$ -conv$5\_1$
-conv$5\_1$ of VGG19 [Reference Simonyan and Zisserman47] are used for computing texture loss. We set $\alpha$
of VGG19 [Reference Simonyan and Zisserman47] are used for computing texture loss. We set $\alpha$ , $\beta$
, $\beta$ , $\gamma$
, $\gamma$ , $\eta$
, $\eta$ as 2, 10, 5, 10 to ensure that loss components are at the same scale. There are four styles used in our experiment, for training a unified deep model for shape and modality manipulation. The training time for PortraitGAN takes around 50 h on a single Nvidia 1080 GPU.
as 2, 10, 5, 10 to ensure that loss components are at the same scale. There are four styles used in our experiment, for training a unified deep model for shape and modality manipulation. The training time for PortraitGAN takes around 50 h on a single Nvidia 1080 GPU.
Dataset
We collected and combined the following three emotion dataset for experiments and performed a 7/3 split based on identity for training and testing. (1) The Radboud Faces Database [Reference Langner, Dotsch, Bijlstra, Wigboldus, Hawk and Van Knippenberg48] contains 4,824 images with 67 participants, each performing eight canonical emotional expressions: anger, disgust, fear, happiness, sadness, surprise, contempt, and neutral. (2) iCV Multi-Emotion Facial Expression Dataset [Reference Lüsi49] is designed for micro-emotion recognition, which includes 31,250 facial expressions from 125 subjects performing 50 different emotions. (3) We also collected 20 videos of high-resolution from Youtube (abbreviated as HRY Dataset) containing 10 people giving speech or talk. For the above dataset, we use dlib [Reference King50] for facial landmark extraction and [Reference Johnson, Alahi and Fei-Fei10] for generating portraits of multiple styles. Extracted landmarks and stylized images correspond to groundtruth $\mathcal {L}_B$ and $\mathcal {I}_B$
and $\mathcal {I}_B$ respectively for equation 5.
respectively for equation 5.
Comparison protocol
CycleGAN [Reference Zhu, Park, Isola and Efros15] is considered state-of-the-art in image translation and is closely related to our work in terms of consistency-loss design. StarGAN [Reference Choi, Choi, Kim, Ha, Kim and Choo26] is also related because it supports multiple attribute transfer using a single generator. However, direct comparison is not possible since none of the two approaches support continuous shape edits. Therefore, to compare with CycleGAN, we use the following pipeline: Given image pair {$\mathcal {I}_A$ ,$\mathcal {I}_B$
,$\mathcal {I}_B$ }, which are from domain $A$
}, which are from domain $A$ and $B$
and $B$ , CycleGAN translates $\mathcal {I}_A$
, CycleGAN translates $\mathcal {I}_A$ to $\widehat {\mathcal {I}_B}$
to $\widehat {\mathcal {I}_B}$ , which has content from $\mathcal {I}_A$
, which has content from $\mathcal {I}_A$ and modality from $\mathcal {I}_B$
and modality from $\mathcal {I}_B$ . This can be achieved with our approach with landmark $\mathcal {L}_A$
. This can be achieved with our approach with landmark $\mathcal {L}_A$ unchanged. To compare with StarGAN, we train StarGAN on discrete canonical expressions and compare it with our approach which is conditioned on facial landmarks.
unchanged. To compare with StarGAN, we train StarGAN on discrete canonical expressions and compare it with our approach which is conditioned on facial landmarks.
A) Portrait manipulation
Our model is sensitive for edits in eyebrows, eyes, and mouth but less so for nose. The reason is because there is little change in nose shape in our collected database. Nevertheless, our model is able to handle continuous edits because of abundant variations of expressions in data. For example, in Fig. 4 of the paper, the 1st-row achieves face-slimming as a result of pulling landmarks for left (right) cheeks inward, even though there is no slim-face groundtruth as training data. Similarly, the 2nd-row of Fig. 4 shows the mouth fully-closed by merging landmarks for upper and down lips. These two results were obtained with a web tool we developed for interactive portrait manipulationFootnote 1, where users can manipulate facial landmarks manually and evaluate the model directly.

Fig. 4. Interactive manipulation without constraints. Column 1st–2nd: Original image and auto-detected facial landmarks; 3rd: generated image from 1st-2nd; 4th: manipulated target landmark; 5th: inverse modality generation from 3rd–4th; 6th: photo to style generation with landmarks of 5th.
Another example for continuous edits is face interpolation. Our model is capable of generating new facial expressions unseen for a certain person. For example, given two canonical expressions (e.g. surprise and smile), we can interpolateFootnote 2 a neutral expression in between through interpolating their facial landmarks. The granularity of face edits depends on the gap between two facial landmarks. Here we show a more challenging case, where we interpolate five intermediate transitions given only two real faces. In this case, the quality of the 3rd face is dependent on previous generations (i.e. after the 2nd and 4th fake faces are generated). In Fig. 5, our model can gradually transition a surprise emotion to a smile emotion, beyond canonical emotions.

Fig. 5. Given leftmost and rightmost face, we first interpolate the middle one (e.g. the 4th one), then we can interpolate 2nd (with 1st and 4th) and 5th (with 4th and 7th). Lastly, we interpolate 3rd (with 2nd and 4th) and 6th (with 5th and 7th).
Compared to discrete conditional labels, facial landmark gives full freedom for continuous shape editing. As can be seen, our model integrates two functions into a single model: shape edits (when modality is fixed) and style transfer (when landmark is fixed). Not only that, our model supports bidirectional transfer using a single generator, i.e. from natural domain to stylistic domain (1st column to 3rd column or from 5th to 6th) or from stylistic domain to natural domain (3rd column to 5th column). The user can manipulate in any domain and can generate edited shapes in another domain immediately. For example, the 1st row successfully performed simultaneous face-slimming and stylistic transfer.
However, there does exist some failure cases, which generally happen in iCV dataset. In Fig. 6, we tried to manipulate landmark in order to change the original expression (1st column) into groundtruth (4th column) but failed. The closest generated result we can get is shown in the 3rd column. As can be seen, the generated picture fails to mimic the intricate expression displayed in groundtruth. Given that iCV is a micro-emotion dataset, our guess is that $68$ landmark is not sufficient for capturing subtle expressions.
landmark is not sufficient for capturing subtle expressions.

Fig. 6. Failure cases: The reason could be that facial landmarks do not capture well enough details of micro-emotions.
An overview of manipulation results are shown in Fig. 1. Some interesting generations were observed. For example, our model seems to be capable of learning some common knowledge, i.e. teeth is hallucinated when mouth is open (1st row, 4th-6th column), after we manipulate the landmarks along the edge of mouth. It is also surprising that our model can preserve obscure details such as earrings (5th row, 4th–6th column). We also notice some artifacts during translation (3rd–4th row, 8th column). The reason is due to the challenge in handling emotion changes and multi-modal transfer with a single model. Having said that, our framework shows promising results in trying to address both simultaneously. For high-resolution (512x512) synthesis, please refer to Figs. 7, 8, 9, 10, 11, 12, 13, 14. As can be seen, our model is able to manipulate expression and style based on landmark prior of the target emotion with photo-realistic effect.We refer readers to the supplementary material for more qualitative results. We will also release a website showcasing more results in original resolution (512*512) on GithubFootnote 3.

Fig. 7. Left: original image; Right: generated image.

Fig. 8. Left: original image; Right: generated image.

Fig. 9. Left: original image; Right: generated image.

Fig. 10. Left: original image; Right: generated image.

Fig. 11. Left: original image; Right: generated image.

Fig. 12. Left: original image; Right: generated image.

Fig. 13. Left: original image; Right: generated image.

Fig. 14. Left: original image; Right: generated image.
Ablation study
Each component is crucial for the proper performance of the system, which we demonstrate through qualitative figures and quantitative numbers in Table 1. First multi-level adversarial loss is essential for high-resolution generation. As can be seen in Fig. 15, face generated with this design exhibits more fine-grained details and thus more realistic. In Table 1, SSIM drops 1.6% without this loss. Second, texture loss is crucial for pattern similarity during modality transformation. As shown in Fig. 16, PortraitGAN generates more consistent textures compared to StarGAN and CycleGAN. In Table 1, SSIM drops 3.6% if without. Last but not least, $\mathcal {L}_{\textrm {cyc}}$ and $\mathcal {L}_{id}$
and $\mathcal {L}_{id}$ help preserve identity.
help preserve identity.

Fig. 15. Effect of multi-level adversarial supervision. Left/Right: wo/w multi-level adversarial supervision. Please also refer to the supplementary material for the high-resolution ($512\times 512$ ) version.
) version.

Fig. 16. Comparison with StarGAN and CycleGAN. Images generated by our model exhibit closer texture proximity to groundtruth, due to adoption of texture consistency loss.
Table 1. Quantitative evaluation for generated image. Our model is slightly slower than StarGAN but achieves the best MSE and SSIM.

B) Perceptual quality
Quantitative analysis
We incorporated 1000 images (500 stylized and 500 natural) to conduct quantitative analysis. For generative adversarial network, two widely used metric for image quality is MSE and SSIM, between the generated image and groundtruth. For MSE, the lower means more fidelity to groundtruth, and for SSIM the higher the better. Table 1 shows quantitative results between CycleGAN, StarGAN, and our approach. As can be seen, our method achieves the best MSE and SSIM score while maintaining relatively fast speed.
Subjective user study
As pointed out in [Reference Isola, Zhu, Zhou and Efros14], traditional metrics should be taken with care when evaluating GAN, therefore we adopt the same evaluation protocol as in [Reference Isola, Zhu, Zhou and Efros14, Reference Zhu, Park, Isola and Efros15, Reference Choi, Choi, Kim, Ha, Kim and Choo26, Reference Wang, Liu, Zhu, Tao, Kautz and Catanzaro27] for human subjective study generated images. We collect responses from 10 users (5 experts, 5 non-experts) based on their preferences about images displayed at each group in terms of perceptual realism and identity preservation. Each group consists of one photo input and three randomly shuffled manipulated images generated by CycleGAN [Reference Zhu, Park, Isola and Efros15], StarGAN [Reference Choi, Choi, Kim, Ha, Kim and Choo26], and our approach. We conducted two rounds of user study where the 1st round has a time limit of 5 s while 2nd round is unlimited. There are in total 100 images and each user is asked to rank three methods on each image twice. Our model gets the best score among three methods as shown in Table 2.
Table 2. Subjective ranking for different models based on perceptual quality. Our model is close to CycleGAN but is much better than StarGAN.

V. CONCLUSIONS
We present a flexible portrait manipulation framework that integrates continuous shape edits and modality transfer into a single adversarial framework. To overcome the technical challenges, we proposed to condition on facial landmark as input and designed a multi-level adversarial supervision structure for high-resolution synthesis. Beyond photo quality, our loss function also takes into account identity and texture into consideration, verified by our ablation studies. Experimental results show the promise of our framework in generating photo-realistic and supporting flexible manipulations. For future work, we would like to improve on the stability of training.
STATEMENT OF INTEREST
None.
Jiali Duan is currently a PhD student in MCL, Viterbi Engineering School of USC, under the supervision of Prof. C.-C. Jay Kuo. He received his Master degree in 2017 with Presidential Award from the National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences. His research interests include generative adversarial learning and deep metric learning.
Xiaoyuan Guo is currently a third-year PhD at Emory University supervisied by Prof. Ashish Sharma. Her research involves object detection, object segmentation, and medical image analysis(whole-slide microscopy image and radiology image) using deep neural networks.
Dr. C.-C. Jay Kuo received the B.S. degree from the National Taiwan University, Taipei, in 1980 and the M.S. and Ph.D. degrees from the Massachusetts Institute of Technology, Cambridge, in 1985 and 1987, respectively, all in Electrical Engineering. From October 1987 to December 1988, he was Computational and Applied Mathematics Research Assistant Professor in the Department of Mathematics at the University of California, Los Angeles. Since January 1989, he has been with the University of Southern California (USC). He is presently USC Distinguished Professor of Electrical Engineering and Computer Science and Director of the Multimedia Communication Laboratory. Dr. Kuo is a Fellow of AAAS, IEEE and SPIE.





























 Open access
Open access