



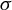
1 Introduction
In recent years, there has been growing interest in the mathematics and computer science communities about expanding the formalism of measure theory. The goal is to capture a wider range of structures and phenomena in probability theory and related fields such as statistics and information theory.
On one hand, there is interest in moving measure theory beyond the need of countability, for example, in the work of Jamneshan and Tao [Reference Jamneshan and Tao15], and in their work with others in expanding ergodic theory in that direction [Reference Jamneshan12–Reference Jamneshan and Tao14, Reference Jamneshan and Tao16].
In addition, there has been work in translating the basic ideas of probability theory into an abstract, axiomatic formalism, of which the traditional measure-theoretic probability is a concrete instance. This approach is sometimes called categorical probability, and it is mostly done by means of Markov categories. In their current form, they were defined in [Reference Fritz5], with some of the concepts already present in earlier work such as [Reference Cho and Jacobs4] for ‘GS monoidal’ or ‘CD’ categories, a slightly more general structure. (The first definitions, in a different context, date back at least to [Reference Gadducci9]—see also [Reference Fritz and Liang7, §1] for a more detailed overview.)
Categorical probability is an example of a synthetic theory, as opposed to analytic. To clarify the terms, here is a classical analogy. The geometry of the plane can be studied synthetically starting from axioms such as Euclid’s ones, or one can do analytic geometry, in the sense of Descartes, doing calculations in coordinates. Since
 $\mathbb {R}^2$
satisfies Euclid’s axioms, analytic geometry is indeed a model of Euclidean geometry, and to prove a theorem, one could use either approach, both methods having advantages and disadvantages.
$\mathbb {R}^2$
satisfies Euclid’s axioms, analytic geometry is indeed a model of Euclidean geometry, and to prove a theorem, one could use either approach, both methods having advantages and disadvantages.
Similarly, with Markov categories, one first formulates some fundamental axioms for probability theory. The theorems of traditional probability theory and statistics can then be recast in a more general and abstract categorical form, and proven purely in terms of these axioms, focusing on the conceptual aspects, and without relying on the specific properties of the objects of the category in question (such as cardinality or separability). The category
 ${\mathsf {Stoch}}$
of Markov kernels (see §2.2) is an example of a Markov category, and one can obtain the traditional results of probability by instantiating the abstract versions in
${\mathsf {Stoch}}$
of Markov kernels (see §2.2) is an example of a Markov category, and one can obtain the traditional results of probability by instantiating the abstract versions in
 ${\mathsf {Stoch}}$
or in one of its subcategories. Several results of probability theory have recently been reproven in this way, for example, the Kolmogorov and Hewitt–Savage zero-one laws [Reference Fritz and Rischel8] and the de Finetti theorem [Reference Fritz, Gonda and Perrone6, Reference Moss and Perrone18].
${\mathsf {Stoch}}$
or in one of its subcategories. Several results of probability theory have recently been reproven in this way, for example, the Kolmogorov and Hewitt–Savage zero-one laws [Reference Fritz and Rischel8] and the de Finetti theorem [Reference Fritz, Gonda and Perrone6, Reference Moss and Perrone18].
In computer science, there is interest in finding an alternative to, or an extension of, traditional measure theory to talk about random functions, in the sense of random elements of a function space. This is known to be impossible in traditional measure theory [Reference Aumann1], and so additional theory is needed. A recently defined structure which solves that problem is the quasi-Borel space [Reference Heunen, Kammar, Staton and Yang10]. Quasi-Borel spaces have interesting properties which may sound counterintuitive if one comes from traditional measure theory, and the Markov category formalism helps to elucidate the conceptual differences [Reference Sabok, Staton, Stein and Wolman19].
In this work, we start expanding the approach of categorical probability to ergodic theory. We focus on one particular result, the ergodic decomposition theorem, which can be roughly stated as ‘every invariant measure of a deterministic dynamical system can be written as a convex mixture of ergodic ones’ [Reference Viana and Oliveira21, §5]. While the traditional form of the theorem, relying on the notions of convexity and almost-sure equality, seems to be very specific to the measure-theoretic formalism, we show that both the statement and the proof can be rewritten in terms of category theory, with most of the conceptual steps used in the proof (such as disintegrations of measures) being already well studied in terms of Markov categories. In particular, the notion of a ‘convex mixture’ can be interpreted as a categorical composition (see §3.1).
An interesting feature of this approach is that the very definition of ergodic measure sits very naturally within the Markov category formalism. Indeed, Markov categories come with a notion of deterministic states (see Definition 2.3) which, when instantiated in
 ${\mathsf {Stoch}}$
, give exactly the zero-one measures, those probability measures which assign to each event probability either zero or one. Since ergodic measures are traditionally (equivalently) defined as measures which are zero-one on the
${\mathsf {Stoch}}$
, give exactly the zero-one measures, those probability measures which assign to each event probability either zero or one. Since ergodic measures are traditionally (equivalently) defined as measures which are zero-one on the
 $\sigma $
-algebra of invariant sets, we can redefine them categorically, and more generally, as particular deterministic states (see §3.3). Invariant sets also have a natural categorical characterization, since the invariant
$\sigma $
-algebra of invariant sets, we can redefine them categorically, and more generally, as particular deterministic states (see §3.3). Invariant sets also have a natural categorical characterization, since the invariant
 $\sigma $
-algebra satisfies a particular universal property in the category of Markov kernels (see §3.2 and Appendix A).
$\sigma $
-algebra satisfies a particular universal property in the category of Markov kernels (see §3.2 and Appendix A).
In the case of deterministic dynamical systems, one can talk about ergodic measures either in terms of sets which are invariant in the strict sense (see Definition 3.6) or only up to measure zero [Reference Viana and Oliveira21, Theorem 5.1.3], and the notions are equivalent for a large class of systems (see for example [Reference Tao20, Theorem 3]). In this work, we focus on the strict approach. A Markov-categorical formalism to treat morphisms up to almost-sure equality exists [Reference Fritz5, Definition 13.8], and it may open an interesting new approach, which for now, we leave to future work.
1.1 Outline
In §2, we start by giving some general background by explaining how to write some notions of dynamical systems in a category-theoretic way (§2.1). We then recall the main definitions and constructions of Markov categories (§2.2), and use them to express some concepts of probability (§2.3) and dynamical systems (§2.4). Most of the material here is well known, except from the last section.
The main original contributions of this work are in §3. In particular, in §3.1, we give a categorical definition of ‘mixtures’ or ‘convex combinations’. In §3.2, we give a categorical characterization of invariant sets, giving a definition that can work in more general categories than Markov kernels. In §3.3, we then express ergodicity of states categorically, in a way that generalizes the usual definition of ‘assuming only values zero and one on invariant sets.’ Our main result, a synthetic version of the ergodic decomposition theorem (Theorem 3.15), is stated and proven in §3.4, together with its instantiation in traditional measure theory (Corollary 3.16).
In Appendix A, we make mathematically precise the intuition that ‘the invariant
 $\sigma $
-algebra is a weak analog of a space of orbits,’ using universal properties in the category of Markov kernels.
$\sigma $
-algebra is a weak analog of a space of orbits,’ using universal properties in the category of Markov kernels.
2 Background
Some aspects of the theory of dynamical systems lend themselves very well to a category-theoretic treatment. Here, we first look at some of the ideas of dynamical systems that can be formalized in terms of categories, in particular, the ideas of invariant states and observables that can be thought of as particular cones and cocones. (There is more to be said about dynamical systems and categories, a good starting point could be [Reference Behrisch, Kerkhoff, Pöschel, Schneider and Siegmund2].)
We then recall the basic definitions and results of Markov categories, which will be used in the rest of this work, and we review some of the main probabilistic concepts which can be expressed in terms of Markov categories. In §2.4, we turn to some structures involving dynamical systems in Markov categories which are, as far as we are aware, first defined in this work.
2.1 Dynamical systems and categories
In ergodic theory and related fields, one is mostly interested in the following two types of dynamical system:
-
(1) a set or space X with some structure (topology, measure, etc.), and a map or kernel
 $t:X\to X$
preserving that structure;
$t:X\to X$
preserving that structure; -
(2) a set or space X with some structure, and a group acting on X in a structure-preserving way.

Both dynamics are encompassed by the notion of a monoid: every group is a monoid, and every map
 $t:X\to X$
generates a monoid via iterations,
$t:X\to X$
generates a monoid via iterations,
 $\{\mathrm {id},t,t^2,\dots \}$
.
$\{\mathrm {id},t,t^2,\dots \}$
.
In terms of category theory, a monoid is equivalently a category with a single object. Given a monoid M, denote by
 ${\mathsf {B}}M$
the category with a single object, denoted by
${\mathsf {B}}M$
the category with a single object, denoted by
 $\bullet $
, and with the set of arrows
$\bullet $
, and with the set of arrows
 $\bullet \to \bullet $
given by M, with its identity and composition.
$\bullet \to \bullet $
given by M, with its identity and composition.
Let now
 ${\mathsf {C}}$
be a category (for example, the category
${\mathsf {C}}$
be a category (for example, the category
 ${\mathsf {Meas}}$
of measurable spaces and measurable maps). A dynamical system can be modeled as a functor
${\mathsf {Meas}}$
of measurable spaces and measurable maps). A dynamical system can be modeled as a functor
 ${\mathsf {B}}M\to {\mathsf {C}}$
. Let us see this explicitly. Such a functor maps:
${\mathsf {B}}M\to {\mathsf {C}}$
. Let us see this explicitly. Such a functor maps:
-
• the unique object
$\bullet $
of
${\mathsf {B}}M$
to an object X of
${\mathsf {C}}$
(for example, a measurable space). This is the object (or ‘space’) where the dynamics takes place; -
• each arrow of
${\mathsf {B}}M$
, i.e. each element m of the monoid M, to an ‘induced’ arrow
$X\to X$
(for example, a measurable map). This is the dynamics.





For brevity, we denote the dynamical system just by X whenever this does not cause ambiguity, and we denote the map
 $X\to X$
induced by
$X\to X$
induced by
 $m\in M$
again by m, writing
$m\in M$
again by m, writing
 $m:X\to X$
.
$m:X\to X$
.
If
 $M=\mathbb {N}$
, the monoid is generated by the number
$M=\mathbb {N}$
, the monoid is generated by the number
 $1$
, and so the dynamics is generated by the arrow induced by
$1$
, and so the dynamics is generated by the arrow induced by
 $1$
(for example, a measurable map), which then is iterated. We usually denote the resulting map by
$1$
(for example, a measurable map), which then is iterated. We usually denote the resulting map by
 $t:X\to X$
.
$t:X\to X$
.
Here are other examples of categories
 ${\mathsf {C}}$
.
${\mathsf {C}}$
.
-
• If
${\mathsf {C}}$
is the category of compact Hausdorff spaces and continuous maps, a functor
${\mathsf {B}}M\to {\mathsf {C}}$
is a (compact) topological dynamical system. -
• If
${\mathsf {C}}$
is the category of measure spaces and measure-preserving maps, a functor
${\mathsf {B}}M\to ~{\mathsf {C}}$
is a measure-preserving dynamical system. -
• If
$M=\mathbb {N}$
and
${\mathsf {C}}$
is the category of measurable spaces and Markov kernels, a functor
${\mathsf {B}}M\to {\mathsf {C}}$
is a (discrete-time) Markov chain.







One of the most useful contributions of the categorical formalism to dynamical systems is a systematic treatment of invariant states and observables. Consider a dynamical system on the object X indexed by the monoid M. A cone over X is an object C together with an arrow
 $c:C\to X$
such that for every
$c:C\to X$
such that for every
 $m\in M$
, the following diagram commutes.
$m\in M$
, the following diagram commutes.

In general, cones over a given dynamical system have the interpretation of ‘invariant states of some kind.’ Indeed, in the category of sets and functions, if C is a one-point set, the arrow
 $c:C\to X$
is the inclusion of some point
$c:C\to X$
is the inclusion of some point
 $x\in X$
, and the diagram in equation (1) just says that x is a fixed point, that is,
$x\in X$
, and the diagram in equation (1) just says that x is a fixed point, that is,
 $m(x)=x$
. More generally, if C is not a one-point set, the arrow
$m(x)=x$
. More generally, if C is not a one-point set, the arrow
 $c:C\to X$
selects a C-indexed family of fixed points in X. (Note that what matters here is that each individual point
$c:C\to X$
selects a C-indexed family of fixed points in X. (Note that what matters here is that each individual point
 $c(i)$
is a fixed point, rather than any property of the range
$c(i)$
is a fixed point, rather than any property of the range
 $\{ c(i) : i \in C \} \subseteq X$
of c as a subset.)
$\{ c(i) : i \in C \} \subseteq X$
of c as a subset.)
Since the diagram in equation (1) can be written as
 $m\circ c = c$
, sometimes one says that m is a left-invariant morphism (since m acts on the left of c). Note that the commutativity of the diagram in equation (1) needs only to be checked on generators of M. For example, for
$m\circ c = c$
, sometimes one says that m is a left-invariant morphism (since m acts on the left of c). Note that the commutativity of the diagram in equation (1) needs only to be checked on generators of M. For example, for
 $M=\mathbb {N}$
, it suffices to check the condition for
$M=\mathbb {N}$
, it suffices to check the condition for
 $1\in \mathbb {N}$
, the map that we usually denote by
$1\in \mathbb {N}$
, the map that we usually denote by
 $t:X\to X$
.
$t:X\to X$
.
A cone
 $C\to X$
over X is universal, or a limit, if for every (other) cone
$C\to X$
over X is universal, or a limit, if for every (other) cone
 $D\to X$
, there is a unique arrow
$D\to X$
, there is a unique arrow
 $D\to C$
such that for every
$D\to C$
such that for every
 $m\in M$
, the following diagram commutes.
$m\in M$
, the following diagram commutes.

The limit cone C, if it exists, is unique up to isomorphism, and can be interpreted as the ‘largest subspace of X of invariant states.’ In the category of sets, it is precisely the set of all invariant points (which can be empty), and in other categories, it has a similar interpretation. We denote the limit, if it exists, by
 $X^{\mathrm {inv}}$
.
$X^{\mathrm {inv}}$
.
Dually, a cocone under the dynamical system X, or a right-invariant morphism, is an object R together with an arrow
 $r:X\to R$
such that for all
$r:X\to R$
such that for all
 $m\in M$
,
$m\in M$
,
 $f\circ m= f$
, i.e. the following diagram commutes.
$f\circ m= f$
, i.e. the following diagram commutes.

This has the interpretation of an invariant function or invariant observable. In the category of sets, this is precisely a function with the property that
 $r(mx)=r(x)$
, i.e. it is constant on each orbit.
$r(mx)=r(x)$
, i.e. it is constant on each orbit.
A cocone is universal, or a colimit, if for every (other) cocone
 $X\to S$
, there is a unique arrow
$X\to S$
, there is a unique arrow
 $R\to S$
such that for every
$R\to S$
such that for every
 $m\in M$
, the following diagram commutes.
$m\in M$
, the following diagram commutes.

Again, this object, if it exists, is unique up to isomorphism, and it can be interpreted as the ‘finest invariant observable.’ In the category of sets, it is precisely the set of orbits, and the commutation of the last diagram says precisely that every invariant observable factors through the orbits. In other categories, the interpretation is similar (for example, for compact Hausdorff spaces, one obtains the quotient by the smallest closed equivalence relation which contains the orbits). We denote the colimit X, if it exists and up to isomorphism, by
 $X_{\mathrm {inv}}$
.
$X_{\mathrm {inv}}$
.
Further categorical formalism for dynamical systems, similar in spirit to this section, can be found in [Reference Behrisch, Kerkhoff, Pöschel, Schneider and Siegmund2], for the case of Cartesian closed categories.
2.2 Basic concepts of Markov categories
Markov categories are a category-theoretic framework for probability and related fields. They allow us to express several conceptual aspects of probability theory (such as stochastic dependence and independence, almost-sure equality, and conditional distributions) in a graphical language, where the formalism takes care automatically of the measure-theoretic aspects. See [Reference Fritz5] for more details.
The basic idea of a Markov category, which we will define shortly, is that of a category whose morphisms are ‘probabilistic maps’ or ‘transitions.’ One of the most basic examples is the category
 ${\mathsf {FinStoch}}$
, where:
${\mathsf {FinStoch}}$
, where:
-
• objects are finite sets, which we denote by X, Y, etc.;
-
• morphisms are stochastic matrices. A stochastic matrix from X to Y is a function
such that for all
$x\in X$
, we have
$\sum _{y\in Y} k(y|x)=1$
. A possible interpretation is a transition probability from state x to state y;
-
• the composition of stochastic matrices is equivalently the Chapman–Kolmogorov formula. For
$k:X\to Y$
and
$h:Y\to Z$
,
$$ \begin{align*} h\circ k(z|x) = \sum_{y\in Y} h(z|y) \, k(y|x). \end{align*} $$






The most important example is the category
 ${\mathsf {Stoch}}$
, where:
${\mathsf {Stoch}}$
, where:
-
• objects are measurable spaces, which we denote as either
$(X,\Sigma _X)$
or more briefly as X; -
• morphisms are Markov kernels. A Markov kernel from X to Y is a function
such that:-
– for each
$x\in X$
, the assignment
$B\mapsto k(B|x)$
is a probability measure on Y; -
– for each
$B\in \Sigma _Y$
, the assignment
$x\mapsto k(B|x)$
is a measurable function on X.
A possible interpretation of the quantity
$k(B|x)$
is the ‘probability that the next state is in B if the current state is x;’ -
-
• the composition of Markov kernels is given by the integral version of the Chapman–Kolmogorov formula. For
$k:X\to Y$
and
$h:Y\to Z$
, and for each measurable
$C\in \Sigma _Z$
,
$$ \begin{align*} h\circ k(C|x) = \int_{Y} h(C|y) \, k(dy|x). \end{align*} $$











Every measurable function
 $f:X\to Y$
defines a ‘deterministic’ Markov kernel
$f:X\to Y$
defines a ‘deterministic’ Markov kernel
 $K_f$
as follows.
$K_f$
as follows.

for each
 $x\in X$
and
$x\in X$
and
 $B\in \Sigma _Y$
. This construction defines then a functor
$B\in \Sigma _Y$
. This construction defines then a functor
 $K:{\mathsf {Meas}}\to {\mathsf {Stoch}}$
from measurable functions to Markov kernels.
$K:{\mathsf {Meas}}\to {\mathsf {Stoch}}$
from measurable functions to Markov kernels.
Markov categories can be considered an abstraction of the category
 ${\mathsf {Stoch}}$
, where the main categorical properties are formulated as axioms, and used to prove theorems of probability without having to use measure theory directly.
${\mathsf {Stoch}}$
, where the main categorical properties are formulated as axioms, and used to prove theorems of probability without having to use measure theory directly.
One of the main structures of the categories
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {FinStoch}}$
, which figures prominently in the definition of Markov categories, is the concept of a monoidal or tensor product. The basic idea is that, sometimes, one wants to consider two systems and talk about joint or composite states. Sometimes, the systems transition independently, and sometimes they interact. The categorical notion of a tensor product (generalizing, for example, the usual tensor of vector spaces) models this idea. Indeed, given objects X and Y, we want to form a ‘composite’ object, denoted by
${\mathsf {FinStoch}}$
, which figures prominently in the definition of Markov categories, is the concept of a monoidal or tensor product. The basic idea is that, sometimes, one wants to consider two systems and talk about joint or composite states. Sometimes, the systems transition independently, and sometimes they interact. The categorical notion of a tensor product (generalizing, for example, the usual tensor of vector spaces) models this idea. Indeed, given objects X and Y, we want to form a ‘composite’ object, denoted by
 $X\otimes Y$
. In
$X\otimes Y$
. In
 ${\mathsf {Stoch}}$
, we take the Cartesian product of measurable spaces, with the product
${\mathsf {Stoch}}$
, we take the Cartesian product of measurable spaces, with the product
 $\sigma $
-algebra. Moreover, given morphisms
$\sigma $
-algebra. Moreover, given morphisms
 $k:X\to Y$
and
$k:X\to Y$
and
 $h:Z\to W$
, we want a morphism
$h:Z\to W$
, we want a morphism
 $k\otimes h:X\otimes Z\to Y\otimes W$
, with the interpretation that in this case, the dynamics is given by k and h independently on the two subsystems. This means that the tensor product is a functor of two variables,
$k\otimes h:X\otimes Z\to Y\otimes W$
, with the interpretation that in this case, the dynamics is given by k and h independently on the two subsystems. This means that the tensor product is a functor of two variables,
 $\otimes :{\mathsf {C}}\otimes {\mathsf {C}}\to {\mathsf {C}}$
. In
$\otimes :{\mathsf {C}}\otimes {\mathsf {C}}\to {\mathsf {C}}$
. In
 ${\mathsf {Stoch}}$
, this is given by the (independent) product of Markov kernels,
${\mathsf {Stoch}}$
, this is given by the (independent) product of Markov kernels,
 $$ \begin{align*} k\otimes h(B,D|x,z) = k(B|x) \, h(D|z) \end{align*} $$
$$ \begin{align*} k\otimes h(B,D|x,z) = k(B|x) \, h(D|z) \end{align*} $$
for all
 $x\in X$
,
$x\in X$
,
 $z\in Z$
,
$z\in Z$
,
 $B\in \Sigma _Y$
, and
$B\in \Sigma _Y$
, and
 $D\in \Sigma _W$
. It is helpful to use string diagrams to represent these products. We draw a morphism
$D\in \Sigma _W$
. It is helpful to use string diagrams to represent these products. We draw a morphism
 $k:X\to Y$
as the following diagram, which should be read from bottom to top.
$k:X\to Y$
as the following diagram, which should be read from bottom to top.
We can write the tensor product
 $k\otimes h$
by simply juxtaposing the two morphisms, as follows.
$k\otimes h$
by simply juxtaposing the two morphisms, as follows.

This notation reflects the fact that the two subsystems do not interact. A general morphism between
 $X\otimes Z$
and
$X\otimes Z$
and
 $Y\otimes W$
will exhibit interaction and will not be in the form above—we represent it as follows.
$Y\otimes W$
will exhibit interaction and will not be in the form above—we represent it as follows.

Moreover, we need a unit object I, which accounts for a ‘trivial’ state. In
 ${\mathsf {Stoch}}$
, this is the one-point measurable space. Markov kernels of the form
${\mathsf {Stoch}}$
, this is the one-point measurable space. Markov kernels of the form
 $p:I\to X$
are equivalently just probability measures in X. In general, we call morphisms in this form states, and denote them as follows.
$p:I\to X$
are equivalently just probability measures in X. In general, we call morphisms in this form states, and denote them as follows.
We have associativity and unitality isomorphisms which resemble the axioms for a monoid,
 $$ \begin{align*} (X\otimes Y)\otimes Z \cong X\otimes(Y\otimes Z) ,\quad X\otimes I \cong X \cong I\otimes X , \end{align*} $$
$$ \begin{align*} (X\otimes Y)\otimes Z \cong X\otimes(Y\otimes Z) ,\quad X\otimes I \cong X \cong I\otimes X , \end{align*} $$
and so, a category with this notion of product is called a monoidal category. A monoidal category is symmetric if each product
 $X\otimes Y$
is isomorphic to
$X\otimes Y$
is isomorphic to
 $Y\otimes X$
in a very strong sense, so that for all practical purposes, the order of the factors does not matter. For the rigorous definition of a monoidal category, see for example [Reference Lane17, §VII.1]. The categorical product with its usual universal property satisfies the axioms of a monoidal product, in that case, one talks about a Cartesian monoidal category. The categories
$Y\otimes X$
in a very strong sense, so that for all practical purposes, the order of the factors does not matter. For the rigorous definition of a monoidal category, see for example [Reference Lane17, §VII.1]. The categorical product with its usual universal property satisfies the axioms of a monoidal product, in that case, one talks about a Cartesian monoidal category. The categories
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {FinStoch}}$
are symmetric monoidal, but not Cartesian. In general, whenever randomness is involved, we do not want a Cartesian category (see below for more on this).
${\mathsf {FinStoch}}$
are symmetric monoidal, but not Cartesian. In general, whenever randomness is involved, we do not want a Cartesian category (see below for more on this).
Here is the rigorous definition of a Markov category.
Definition 2.1. A Markov category is a symmetric monoidal category
 $({\mathsf {C}},\otimes ,I)$
, or more briefly
$({\mathsf {C}},\otimes ,I)$
, or more briefly
 ${\mathsf {C}}$
, where:
${\mathsf {C}}$
, where:
-
• each object X is equipped with maps
$\operatorname {\mathrm {copy}}:X\to X\otimes X$
and
$\operatorname {\mathrm {del}}:X\to I$
, which we call ‘copy and delete’ or ‘copy and discard,’ and we draw as follows; -
• the following identities are satisfied (e.g. ‘copying and deleting a copy is the same as doing nothing’);
-
• the copy and discard maps are compatible with tensor products in the following way;
-
• the unit I is the terminal object of the category (i.e. the category is semicartesian).






In
 ${\mathsf {Stoch}}$
, the copy and discard maps are the kernels obtained by the following measurable functions. The copy map corresponds from the diagonal map
${\mathsf {Stoch}}$
, the copy and discard maps are the kernels obtained by the following measurable functions. The copy map corresponds from the diagonal map
 $X\to X\times X$
which literally ‘copies the state,’
$X\to X\times X$
which literally ‘copies the state,’
 $x\mapsto (x,x)$
. The discard map corresponds to the unique map to the one-point space
$x\mapsto (x,x)$
. The discard map corresponds to the unique map to the one-point space
 $X\to I$
.
$X\to I$
.
2.3 Graphical definitions of probabilistic concepts
The formalism of Markov categories allows us to express several concepts of probability theory in categorical and graphical terms. The first notion we can look at is stochastic independence. First of all, notice that given a joint state
 $p:I\to X\otimes Y$
, we can form the marginal
$p:I\to X\otimes Y$
, we can form the marginal
 $p_X$
on X by simply discarding Y.
$p_X$
on X by simply discarding Y.

In
 ${\mathsf {Stoch}}$
, this corresponds to saying that the marginal on X is the pushforward of the measure p along the projection map
${\mathsf {Stoch}}$
, this corresponds to saying that the marginal on X is the pushforward of the measure p along the projection map
 $X\times Y\to X$
.
$X\times Y\to X$
.
Definition 2.2. A joint state
 $p:I\to X\otimes Y$
is said to exhibit independence of X and Y if the following holds.
$p:I\to X\otimes Y$
is said to exhibit independence of X and Y if the following holds.

More generally, a morphism
 $p:A\to X\otimes Y$
is said to exhibit conditional independence of X and Y given A if the following holds.
$p:A\to X\otimes Y$
is said to exhibit conditional independence of X and Y given A if the following holds.

In
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {FinStoch}}$
, these correspond to the usual notions. For example, equation (3) in
${\mathsf {FinStoch}}$
, these correspond to the usual notions. For example, equation (3) in
 ${\mathsf {FinStoch}}$
corresponds to saying that
${\mathsf {FinStoch}}$
corresponds to saying that
 $$ \begin{align*} p(x,y) = p_X(x)\,p_Y(y) \end{align*} $$
$$ \begin{align*} p(x,y) = p_X(x)\,p_Y(y) \end{align*} $$
for all x and y, and in
 ${\mathsf {Stoch}}$
corresponds to saying that
${\mathsf {Stoch}}$
corresponds to saying that
 $$ \begin{align*} p(A\times B) = p_X(A)\,p_Y(B) \end{align*} $$
$$ \begin{align*} p(A\times B) = p_X(A)\,p_Y(B) \end{align*} $$
for all measurable sets
 $A\in \Sigma _X$
and
$A\in \Sigma _X$
and
 $B\in \Sigma _Y$
.
$B\in \Sigma _Y$
.
Another natural concept in Markov categories is the notion of a deterministic morphism.
Definition 2.3. A morphism
 $f:X\to Y$
in a Markov category
$f:X\to Y$
in a Markov category
 ${\mathsf {C}}$
is called deterministic if the following identity holds.
${\mathsf {C}}$
is called deterministic if the following identity holds.

We denote by
 ${{\mathsf {C}}}_{\det }$
the subcategory of
${{\mathsf {C}}}_{\det }$
the subcategory of
 ${\mathsf {C}}$
of deterministic morphisms.
${\mathsf {C}}$
of deterministic morphisms.
Intuitively, if f carries non-trivial randomness, then the identity above cannot hold: on the left, we have perfect correlation given A and on the right, we have conditional independence given A.
For a state
 $p:I\to X$
, the condition in equation (4) reads as follows.
$p:I\to X$
, the condition in equation (4) reads as follows.

In
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {FinStoch}}$
, these are exactly those measures (and kernels in the general case) which can only have values zero and one. Indeed, equation (5) says that for each pair of measurable sets
${\mathsf {FinStoch}}$
, these are exactly those measures (and kernels in the general case) which can only have values zero and one. Indeed, equation (5) says that for each pair of measurable sets
 $A,B\in \Sigma _X$
, we have
$A,B\in \Sigma _X$
, we have
 $$ \begin{align*} p(A\cap B) = p(A)\,p(B). \end{align*} $$
$$ \begin{align*} p(A\cap B) = p(A)\,p(B). \end{align*} $$
In particular, for
 $A=B$
, we get
$A=B$
, we get
 $p(A)=p(A)^2$
, i.e.
$p(A)=p(A)^2$
, i.e.
 $p(A)=0$
or
$p(A)=0$
or
 $p(A)=1$
. Every Dirac delta probability measure is of this form. On standard Borel spaces, only Dirac deltas are in this form, and so every deterministic morphism between standard Borel spaces comes from an ordinary measurable function, via the construction in equation (2). If one considers coarser
$p(A)=1$
. Every Dirac delta probability measure is of this form. On standard Borel spaces, only Dirac deltas are in this form, and so every deterministic morphism between standard Borel spaces comes from an ordinary measurable function, via the construction in equation (2). If one considers coarser
 $\sigma $
-algebras, however, there are measures which are deterministic (according to Definition 2.3), but which are not Dirac deltas. These are extremely important, for example, most ergodic measures are of this form, if one considers the
$\sigma $
-algebras, however, there are measures which are deterministic (according to Definition 2.3), but which are not Dirac deltas. These are extremely important, for example, most ergodic measures are of this form, if one considers the
 $\sigma $
-algebra of invariant sets (see Definition 3.8). In other words, we have functors
$\sigma $
-algebra of invariant sets (see Definition 3.8). In other words, we have functors
and the first functor is not quite the identity. When we speak generally of deterministic Markov kernels, we will mean kernels with value zero and one, which are more general than the ones obtained by a measurable function via the functor K of equation (2). The advantage of working with this category will become clear in §3, and also in Appendix A. For more theory on those deterministic morphisms which are not Dirac deltas, see [Reference Moss and Perrone18].
Proposition 2.4. The following conditions are equivalent for a Markov category
 ${\mathsf {C}}$
.
${\mathsf {C}}$
.
-
(1) Every morphism of
${\mathsf {C}}$
is deterministic. -
(2) The copy maps form a natural transformation.
-
(3) The monoidal structure of
${\mathsf {C}}$
is Cartesian.


Therefore, one can view Cartesian categories as precisely those Markov categories with only trivial randomness.
Another concept of probability theory which can be expressed in terms of Markov categories is the concept of almost-sure equality, first introduced in [Reference Cho and Jacobs4, Definition 5.1] and expanded in [Reference Fritz5, Definition 13.1].
Definition 2.5. In a Markov category, let
 $p:A\to X$
and let
$p:A\to X$
and let
 $f,g:X\to Y$
. We say that f and g are p-almost surely (a.s.) equal if
$f,g:X\to Y$
. We say that f and g are p-almost surely (a.s.) equal if

In particular, for states, this reads as follows.

In
 ${\mathsf {Stoch}}$
, this condition is equivalent to the usual almost-sure equality for the measure p.
${\mathsf {Stoch}}$
, this condition is equivalent to the usual almost-sure equality for the measure p.
If f is a morphism and R is an equationally defined property that f may or may not satisfy, we say that f satisfies the R property p-a.s. if and only if the relevant morphisms are equal p-a.s. For example, we say that f is p-a.s. deterministic if and only if equation (4) holds p-a.s., i.e. the following condition holds.

See also [Reference Fritz5, Definition 13.11].
We now turn to conditioning. There are a few variations of the idea of conditionals and disintegrations. We will use the following one. For additional context, see [Reference Fritz5, §11].
Definition 2.6. In a Markov category
 ${\mathsf {C}}$
, let
${\mathsf {C}}$
, let
 $p:I\to X$
be a state and let
$p:I\to X$
be a state and let
 $f:X\to Y$
be a morphism. A disintegration of p via f, or a Bayesian inversion of f with respect to (w.r.t.) p, is a morphism
$f:X\to Y$
be a morphism. A disintegration of p via f, or a Bayesian inversion of f with respect to (w.r.t.) p, is a morphism
 $f^+_p: Y\to X$
such that the following holds.
$f^+_p: Y\to X$
such that the following holds.

In
 ${\mathsf {Stoch}}$
, this definition reads as follows, if we denote the state
${\mathsf {Stoch}}$
, this definition reads as follows, if we denote the state
 $f\circ p:I\to Y$
by q. Given a probability measure p on X and a Markov kernel (for example, a measurable function)
$f\circ p:I\to Y$
by q. Given a probability measure p on X and a Markov kernel (for example, a measurable function)
 $f:X\to Y$
, the Markov kernel
$f:X\to Y$
, the Markov kernel
 $f^+_p: Y\to X$
is such that for all measurable subsets
$f^+_p: Y\to X$
is such that for all measurable subsets
 $A\in \Sigma _X$
and
$A\in \Sigma _X$
and
 $B\in \Sigma _Y$
,
$B\in \Sigma _Y$
,
 $$ \begin{align*} \int_A f(B|x) \,p(dx) = \int_B f^+_p(A|y) \, q(dy). \end{align*} $$
$$ \begin{align*} \int_A f(B|x) \,p(dx) = \int_B f^+_p(A|y) \, q(dy). \end{align*} $$
In
 ${\mathsf {FinStoch}}$
, the condition has the even simpler form
${\mathsf {FinStoch}}$
, the condition has the even simpler form
 $$ \begin{align*} p(x) \, f(y|x) = q(y) \, f^+_p(x|y). \end{align*} $$
$$ \begin{align*} p(x) \, f(y|x) = q(y) \, f^+_p(x|y). \end{align*} $$
This can be therefore seen as a categorical definition of Bayesian inversion, and if f is deterministic, as a disintegration of p in the sense of disintegration theorems (see for example [Reference Bogachev3, §10.6]).
It follows immediately from the definition that any two disintegrations of p via f as above are equal q-a.s., generalizing what happens in ordinary measure theory.
Proposition 2.7. Let
 $f:X\to Y$
be deterministic. Let
$f:X\to Y$
be deterministic. Let
 $p:I\to X$
and suppose that the disintegration
$p:I\to X$
and suppose that the disintegration
 $f^+_p:Y\to X$
exists. Then, the composite
$f^+_p:Y\to X$
exists. Then, the composite
is
 $(f\circ p)$
-a.s. equal to the identity.
$(f\circ p)$
-a.s. equal to the identity.
This was mentioned in [Reference Fritz5], directly after Proposition 11.17 therein. We include a proof here, for completeness.
Proof. We have that

where the first equality is by definition of
 $f^+_p$
and the second equality is by determinism of f.
$f^+_p$
and the second equality is by determinism of f.
Definition 2.8. We say that an object X in a Markov category has disintegrations if it admits a disintegration for each state
 $p:I\to X$
and for each deterministic map
$p:I\to X$
and for each deterministic map
 $f:X\to Y$
.
$f:X\to Y$
.
In
 ${\mathsf {Stoch}}$
, every standard Borel space has disintegrations, this statement is sometimes known as (Rokhlin’s) disintegration theorem. See for example [Reference Tao20, Theorem 4 and Remark 5], [Reference Viana and Oliveira21, Theorem 5.1.11 and related sections], as well as [Reference Bogachev3, §10.6].
${\mathsf {Stoch}}$
, every standard Borel space has disintegrations, this statement is sometimes known as (Rokhlin’s) disintegration theorem. See for example [Reference Tao20, Theorem 4 and Remark 5], [Reference Viana and Oliveira21, Theorem 5.1.11 and related sections], as well as [Reference Bogachev3, §10.6].
2.4 Dynamical systems in Markov categories
A dynamical system in a Markov category can be interpreted as a ‘stochastic’ dynamical system in general. For example, a dynamical system in
 ${\mathsf {Stoch}}$
with monoid
${\mathsf {Stoch}}$
with monoid
 $\mathbb {N}$
is a discrete-time Markov process. In this work, we are mostly interested in dynamical systems in the subcategory of deterministic morphisms of a Markov category. These are interpretable as traditional deterministic dynamical systems. The advantage of working in the larger Markov category (rather than in
$\mathbb {N}$
is a discrete-time Markov process. In this work, we are mostly interested in dynamical systems in the subcategory of deterministic morphisms of a Markov category. These are interpretable as traditional deterministic dynamical systems. The advantage of working in the larger Markov category (rather than in
 ${\mathsf {Meas}}$
) is the convenience of having states (measures) and conditionals (kernels) fit in the same language. Moreover, as we have seen, there are deterministic morphisms in
${\mathsf {Meas}}$
) is the convenience of having states (measures) and conditionals (kernels) fit in the same language. Moreover, as we have seen, there are deterministic morphisms in
 ${\mathsf {Stoch}}$
which are not just measurable functions, and these are going to be crucial to talk about ergodicity.
${\mathsf {Stoch}}$
which are not just measurable functions, and these are going to be crucial to talk about ergodicity.
Let X be a dynamical system with monoid M in a Markov category
 ${\mathsf {C}}$
. Following the intuition of §2.1, we have the following.
${\mathsf {C}}$
. Following the intuition of §2.1, we have the following.
-
• A left-invariant state (as known as (a.k.a.) cone) from the monoidal unit
$p:I\to X$
is a state satisfying
$m\circ p=p$
for all
$m\in M$
. This can be interpreted as an ‘invariant random state,’ or ‘invariant measure.’ In
${\mathsf {Stoch}}$
, these are invariant measures. For deterministic dynamical systems generated by measurable functions in the form
$m:X\to X$
, this is a measure p satisfying for every measurable set
$$ \begin{align*} p(m^{-1}(A)) = p(A) \end{align*} $$
$A\in \Sigma _X$
. More generally, for dynamical systems generated by kernels, in the form
$m:X\times \Sigma _X\to [0,1]$
, the invariance of p means that for every measurable
$A\in \Sigma _X$
,
$$ \begin{align*} \int_X m(A|x) \,p(dx) = p(A). \end{align*} $$
-
• More generally, a left-invariant morphism (a.k.a. cone) from a generic object
$c:C\to ~X$
is a morphism satisfying
$m\circ c=c$
for all
$m\in M$
. This can be interpreted either as a ‘transition to an invariant state,’ or as a family of invariant states parameterized (measurably) by C. In
${\mathsf {Stoch}}$
, the interpretation is similar to invariant measures, except that they depend measurably on a parameter. -
• A right-invariant morphism (a.k.a. cocone)
$r:X\to R$
is a morphism satisfying
$r\circ m=r$
for all
$m\in M$
. This can be interpreted as an ‘invariant function or invariant observable,’ especially when r is deterministic. In
${\mathsf {Stoch}}$
, these indeed correspond to invariant functions, or invariant kernels. For dynamical systems where M acts by measurable functions
$m:X\to X$
, this means a measurable map
$r:X\to R$
satisfying for every
$$ \begin{align*} r(m(x)) = r(x) \end{align*} $$
$x\in X$
and
$m \in M$
. More generally, for dynamical systems where M acts by kernels
$m:X\times \Sigma _X\to [0,1]$
, the right-invariance of a kernel r means that for every
$x\in X$
,
$m\in M$
, and
$B\in \Sigma _R$
, (6)
$$ \begin{align} \int_X r(B|x') \, m(dx'|x) = r(B|x). \end{align} $$




























From now on, when we talk about an invariant state, we always mean a left-invariant state (in
 ${\mathsf {Stoch}}$
, an invariant measure). When we talk about an invariant observable, we talk about a right-invariant morphism (in
${\mathsf {Stoch}}$
, an invariant measure). When we talk about an invariant observable, we talk about a right-invariant morphism (in
 ${\mathsf {Stoch}}$
, an invariant measurable map or kernel). We are mostly interested in deterministic invariant observables.
${\mathsf {Stoch}}$
, an invariant measurable map or kernel). We are mostly interested in deterministic invariant observables.
3 Ergodic decomposition in Markov categories
To express our main result (Theorem 3.15), we need to express some additional concepts in terms of category theory. First of all, we need a notion of ‘mixture’ or ‘convex combination,’ which will be introduced in §3.1. We then need to explain how to talk about invariant sets categorically, and it will be in terms of a particular colimit construction, explained in §3.2. Finally, in §3.3, we define ergodic states as particular deterministic morphisms, which allows in §3.4 to express our main result and its instantiation in the category of Markov kernels (Corollary 3.16).
3.1 Mixtures of states
Let us define a categorical version of convex decompositions, which can be constructed in any Markov category.
For motivation, let X be a finite set and let p be a (discrete) probability measure on X. Let now
 $k_1,\dots ,k_n$
be other probability measures on X. We say that p is a convex combination of the
$k_1,\dots ,k_n$
be other probability measures on X. We say that p is a convex combination of the
 $k_i$
with coefficients
$k_i$
with coefficients
 $q_i$
if
$q_i$
if
 $$ \begin{align*} p = \sum_{i=1}^n k_i \, q_i , \end{align*} $$
$$ \begin{align*} p = \sum_{i=1}^n k_i \, q_i , \end{align*} $$
or more explicitly, for each
 $x\in X$
,
$x\in X$
,
 $$ \begin{align} p(x) = \sum_{i=1}^n k_i(x) \, q_i. \end{align} $$
$$ \begin{align} p(x) = \sum_{i=1}^n k_i(x) \, q_i. \end{align} $$
For the
 $q_i$
to be the coefficients of a convex combination, we need
$q_i$
to be the coefficients of a convex combination, we need
 $0\le q_i\le 1$
for all i, and
$0\le q_i\le 1$
for all i, and
 $\sum _i q_i=1$
. In other words, we need the map
$\sum _i q_i=1$
. In other words, we need the map
 $i\mapsto q_i$
to be a (discrete) probability measure on the set
$i\mapsto q_i$
to be a (discrete) probability measure on the set
 $\{1,\dots ,n\}$
. That way,
$\{1,\dots ,n\}$
. That way,
 $i\mapsto k_i$
can be considered a discrete kernel (or transition matrix) from
$i\mapsto k_i$
can be considered a discrete kernel (or transition matrix) from
 $\{1,\dots ,n\}$
to X. Equation (7) can then be expressed as the (matrix) composition of q with k. Note that the values of
$\{1,\dots ,n\}$
to X. Equation (7) can then be expressed as the (matrix) composition of q with k. Note that the values of
 $k_i$
when
$k_i$
when
 $q_i=0$
do not play any role.
$q_i=0$
do not play any role.
More generally, if a generic finite set Y is indexing the convex combination, and writing
 $k(x|y)$
instead of
$k(x|y)$
instead of
 $k_y(x)$
, we see that a convex decomposition of p,
$k_y(x)$
, we see that a convex decomposition of p,
 $$ \begin{align*} p(x) = \sum_{y\in Y} k(x|y) \, q(y) , \end{align*} $$
$$ \begin{align*} p(x) = \sum_{y\in Y} k(x|y) \, q(y) , \end{align*} $$
is just the decomposition of
 $p:I\to X$
in the category
$p:I\to X$
in the category
 ${\mathsf {FinStoch}}$
into a composite of stochastic matrices,
${\mathsf {FinStoch}}$
into a composite of stochastic matrices,
Let us now turn to the continuous case. Let X be a measurable space, and let p be a probability measure on X, which we can view as a morphism
 $p:I\to X$
of
$p:I\to X$
of
 ${\mathsf {Stoch}}$
. In this category, decomposing
${\mathsf {Stoch}}$
. In this category, decomposing
 $p:I\to X$
corresponds to writing it as a (measurably indexed) mixture of measures. Indeed,
$p:I\to X$
corresponds to writing it as a (measurably indexed) mixture of measures. Indeed,
 $k\circ q = p$
for a pair of morphisms
$k\circ q = p$
for a pair of morphisms
 $q:I\to Y, k:Y\to X$
if and only if for each measurable set
$q:I\to Y, k:Y\to X$
if and only if for each measurable set
 $A\subseteq X$
, we have
$A\subseteq X$
, we have
 $$ \begin{align*} p(A) = \int_Y k(A|y) \, q(dy). \end{align*} $$
$$ \begin{align*} p(A) = \int_Y k(A|y) \, q(dy). \end{align*} $$
If we consider k as a Y-indexed family of measures on X, and denote it by
 $y\mapsto k_y$
, then we are equivalently saying that
$y\mapsto k_y$
, then we are equivalently saying that
 $$ \begin{align*} p = \int_Y k_y \, q(dy). \end{align*} $$
$$ \begin{align*} p = \int_Y k_y \, q(dy). \end{align*} $$
That is, p is a mixture of measures (
 $k_y$
) with mixing measure q. Note that the mixture only depends on the values of
$k_y$
) with mixing measure q. Note that the mixture only depends on the values of
 $k_y$
for q-almost all y.
$k_y$
for q-almost all y.
Here is the general definition.
Definition 3.1. Let
 $p:I\to X$
be a state in a Markov category. A decomposition of p is a factorization of p. More explicitly, it consists of:
$p:I\to X$
be a state in a Markov category. A decomposition of p is a factorization of p. More explicitly, it consists of:
-
• a state
$q:I\to Y$
; -
• a morphism
$k : Y \to X$
,


such that
 $k\circ q = p$
.
$k\circ q = p$
.
Not all distinctions between decompositions are interesting. For example, in the discussion above, changes to the values of
 $k_y$
on any set of q-measure zero are not interesting. In terms of Markov categories, we have the following. If
$k_y$
on any set of q-measure zero are not interesting. In terms of Markov categories, we have the following. If
 $(q,k)$
is a decomposition of p and
$(q,k)$
is a decomposition of p and
 $k' : Y \to X$
is any other morphism with
$k' : Y \to X$
is any other morphism with
 $k =_{q\text {-a.s.}} k'$
, it follows that
$k =_{q\text {-a.s.}} k'$
, it follows that
 $p = k \circ q = k' \circ q$
, whence
$p = k \circ q = k' \circ q$
, whence
 $(q,k')$
is also a decomposition of p. Thus it would be somewhat natural to identify decompositions
$(q,k')$
is also a decomposition of p. Thus it would be somewhat natural to identify decompositions
 $(q,k), (q,k')$
whenever
$(q,k), (q,k')$
whenever
 $k =_{q\text {-a.s.}} k'$
, but equivalence of decompositions plays no role in this paper beyond the special case of equivalence with the trivial decomposition (Definition 3.2).
$k =_{q\text {-a.s.}} k'$
, but equivalence of decompositions plays no role in this paper beyond the special case of equivalence with the trivial decomposition (Definition 3.2).
In the discrete case, p always has a trivial decomposition: we can write p as
 $$ \begin{align*} p = \sum_{y\in Y} p \, q(y) \end{align*} $$
$$ \begin{align*} p = \sum_{y\in Y} p \, q(y) \end{align*} $$
for any normalized measure q. More generally, we can always write
 $$ \begin{align*} p = \int_Y \tilde{p}_y \, q(dy) , \end{align*} $$
$$ \begin{align*} p = \int_Y \tilde{p}_y \, q(dy) , \end{align*} $$
where
 $y\mapsto \tilde {p}_y$
is q-a.s. equal to p.
$y\mapsto \tilde {p}_y$
is q-a.s. equal to p.
We can define this in general.
Definition 3.2. Let
 $(q:I\to Y, k:Y\to X)$
be a decomposition of
$(q:I\to Y, k:Y\to X)$
be a decomposition of
 $p:I\to X$
. We say that
$p:I\to X$
. We say that
 $(q,k)$
is a trivial decomposition of p if and only if k is q-a.s. equal to
$(q,k)$
is a trivial decomposition of p if and only if k is q-a.s. equal to
We call the state p indecomposable if all its decompositions are trivial.
Clearly, each Dirac delta probability measure is indecomposable. This is part of Choquet theory, where one shows that the set of probability measures over a given space is a simplex (or an infinite-dimensional analog thereof), and its extreme points are exactly the Dirac delta, or more generally, the zero-one measures. (See for example [Reference Winkler22] for more on Choquet decompositions.) For general Markov categories, there is a similar relationship between indecomposable and deterministic states.
Proposition 3.3. Every indecomposable state is deterministic.
Proof. Let
 $p:I\to X$
be an indecomposable state. We can decompose p as
$p:I\to X$
be an indecomposable state. We can decompose p as
 $p=\mathrm {id}\circ p$
and, by hypothesis, this decomposition is trivial. Therefore, the identity
$p=\mathrm {id}\circ p$
and, by hypothesis, this decomposition is trivial. Therefore, the identity
 $\mathrm {id}$
is p-a.s. equal to
$\mathrm {id}$
is p-a.s. equal to
That is,

Hence, p is deterministic.
The converse statement fails for general Markov categories, but it holds for a large class of them, including
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {FinStoch}}$
. Recall from [Reference Fritz5, §11] that a Markov category is called positive if whenever a composite
${\mathsf {FinStoch}}$
. Recall from [Reference Fritz5, §11] that a Markov category is called positive if whenever a composite
 $f\circ p$
is deterministic, then the following equation holds.
$f\circ p$
is deterministic, then the following equation holds.

This holds for
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {FinStoch}}$
, and it is related to the fact that probabilities are non-negative (hence the name), see the original reference for more details.
${\mathsf {FinStoch}}$
, and it is related to the fact that probabilities are non-negative (hence the name), see the original reference for more details.
Proposition 3.4. In a positive Markov category, every deterministic state is indecomposable.
Proof. If we instantiate the positivity condition in equation (8) with the case of a state, we get that for
 $p:I\to X$
and
$p:I\to X$
and
 $f:X\to Y$
such that
$f:X\to Y$
such that
 $f\circ p$
is deterministic, then
$f\circ p$
is deterministic, then

So let the composition
 $f\circ p$
be a deterministic state. The equation above says that f is p-a.s. equal to
$f\circ p$
be a deterministic state. The equation above says that f is p-a.s. equal to
 $f\circ p$
. Therefore,
$f\circ p$
. Therefore,
 $f\circ p$
is indecomposable.
$f\circ p$
is indecomposable.
In conclusion:
-
• in
${\mathsf {Stoch}}$
and
${\mathsf {FinStoch}}$
, convex combinations of measures can be described categorically as compositions of arrows (up to almost sure equality); -
• the deterministic states are precisely those that cannot be written as a non-trivial convex combination.


This is the notion of decomposition which we will use in our ergodic decomposition theorem (§3.4).
3.2 Markov quotients
For the purposes of this work, we need colimits of dynamical systems in a Markov category, which, as we have seen in §2.1, can be often interpreted as ‘quotient spaces’ or ‘spaces of orbits’ (more on this in Appendix A). In Markov categories, we need to require a little bit more of the usual universal property: it needs to play well with deterministic morphisms.
Definition 3.5. Let X be a dynamical system with monoid M in a Markov category
 ${\mathsf {C}}$
. The Markov colimit or Markov quotient of X over the action of M is an object, which we denote by
${\mathsf {C}}$
. The Markov colimit or Markov quotient of X over the action of M is an object, which we denote by
 $X_{\mathrm {inv}}$
together with a deterministic map
$X_{\mathrm {inv}}$
together with a deterministic map
 $r:X\to X_{\mathrm {inv}}$
, which is a colimit both in
$r:X\to X_{\mathrm {inv}}$
, which is a colimit both in
 ${\mathsf {C}}$
and in the subcategory
${\mathsf {C}}$
and in the subcategory
 ${\mathsf {C}}_{\det }$
of deterministic morphisms.
${\mathsf {C}}_{\det }$
of deterministic morphisms.
Alternatively and more explicitly, it is a map
 $r : X \to X_{\mathrm {inv}}$
, where:
$r : X \to X_{\mathrm {inv}}$
, where:
-
• for every invariant observable
$s:X\to S$
, there exists a unique map
$\tilde s:X_{\mathrm {inv}}\to S$
such that
$s=\tilde s\circ r$
, i.e. making the following diagram commute for each
$m\in M$
; (10) -
• and moreover, the map
$\tilde s$
is deterministic if and only if the map s is.






By taking
 $S = X_{\mathrm {inv}}$
and
$S = X_{\mathrm {inv}}$
and
 $s = r$
, so that
$s = r$
, so that
 $\tilde s = \mathrm {id}$
, we see that the second point implies that r is deterministic.
$\tilde s = \mathrm {id}$
, we see that the second point implies that r is deterministic.
It is worth remarking on the connection between our Markov quotients and the Kolmogorov products introduced in [Reference Fritz and Rischel8]. The latter essentially suggests a notion of cofiltered limit appropriate to Markov categories, characterized by requiring the limiting property to hold in both the
 ${\mathsf {C}}$
and
${\mathsf {C}}$
and
 ${\mathsf {C}}_{\det }$
and to be preserved by all functors
${\mathsf {C}}_{\det }$
and to be preserved by all functors
 $(-) \otimes A$
for
$(-) \otimes A$
for
 $A \in {\mathsf {C}}$
. By contrast, we do not require Markov quotients to be preserved by the tensor product here.
$A \in {\mathsf {C}}$
. By contrast, we do not require Markov quotients to be preserved by the tensor product here.
We have seen that the colimit of a dynamical system has the interpretation of a ‘space of orbits.’ In
 ${\mathsf {Stoch}}$
, at least when the dynamics is deterministic, the Markov colimit exists and is given by the invariant
${\mathsf {Stoch}}$
, at least when the dynamics is deterministic, the Markov colimit exists and is given by the invariant
 $\sigma $
-algebra. We will define this more precisely and then check the universal property (Proposition 3.7). In Appendix A, we will see in what sense it is similar to a space of orbits.
$\sigma $
-algebra. We will define this more precisely and then check the universal property (Proposition 3.7). In Appendix A, we will see in what sense it is similar to a space of orbits.
Definition 3.6. Let X be a dynamical system in
 ${\mathsf {Stoch}}$
with monoid M. A measurable set
${\mathsf {Stoch}}$
with monoid M. A measurable set
 $A\in \Sigma _X$
is called invariant if for every
$A\in \Sigma _X$
is called invariant if for every
 $m\in M$
, we have
$m\in M$
, we have
 $$ \begin{align} m(A|x) = 1_A(x) = \begin{cases} 1, & x\in A, \\ 0, & x\notin A. \end{cases} \end{align} $$
$$ \begin{align} m(A|x) = 1_A(x) = \begin{cases} 1, & x\in A, \\ 0, & x\notin A. \end{cases} \end{align} $$
If the dynamical system is deterministic and generated by measurable functions
 $m:X\to X$
, the invariance condition in equation (11) can be written more simply as
$m:X\to X$
, the invariance condition in equation (11) can be written more simply as
 $m^{-1}(A)=A$
. As it is well known, both for the deterministic and for the generic case, invariant sets form a
$m^{-1}(A)=A$
. As it is well known, both for the deterministic and for the generic case, invariant sets form a
 $\sigma $
-algebra, often called the invariant
$\sigma $
-algebra, often called the invariant
 $\sigma $
-algebra.
$\sigma $
-algebra.
Proposition 3.7. Let X be a deterministic dynamical system in
 ${\mathsf {Stoch}}$
with monoid M. Then, the Markov quotient
${\mathsf {Stoch}}$
with monoid M. Then, the Markov quotient
 $X_{\mathrm {inv}}$
exists and it is given by the same set X, equipped with the invariant
$X_{\mathrm {inv}}$
exists and it is given by the same set X, equipped with the invariant
 $\sigma $
-algebra.
$\sigma $
-algebra.
Proof. Construct the kernel
 $r:X\to X_{\mathrm {inv}}$
as follows:
$r:X\to X_{\mathrm {inv}}$
as follows:
 $$ \begin{align*} r(A|x) = 1_A(x) = \begin{cases} 1, & x\in A, \\ 0, & x\notin A \end{cases} \end{align*} $$
$$ \begin{align*} r(A|x) = 1_A(x) = \begin{cases} 1, & x\in A, \\ 0, & x\notin A \end{cases} \end{align*} $$
for every
 $x\in S$
and every measurable (invariant) set
$x\in S$
and every measurable (invariant) set
 $A\in \Sigma _{X_{\mathrm {inv}}}$
. Note that it is exactly the kernel induced by the function
$A\in \Sigma _{X_{\mathrm {inv}}}$
. Note that it is exactly the kernel induced by the function
 $X\to X_{\mathrm {inv}}$
induced by the set-theoretic identity. As every measurable set of
$X\to X_{\mathrm {inv}}$
induced by the set-theoretic identity. As every measurable set of
 $X_{\mathrm {inv}}$
is measurable in X, this function is measurable, and so it induces a well-defined Markov kernel. Let us now prove that r is left-invariant. For every
$X_{\mathrm {inv}}$
is measurable in X, this function is measurable, and so it induces a well-defined Markov kernel. Let us now prove that r is left-invariant. For every
 $m\in M$
, every
$m\in M$
, every
 $x\in X$
, and every measurable (invariant) set
$x\in X$
, and every measurable (invariant) set
 $A\in \Sigma _{X_{\mathrm {inv}}}$
,
$A\in \Sigma _{X_{\mathrm {inv}}}$
,
 $$ \begin{align*} \int_X r(A|x') \,m(dx'|x) = \int_X 1_A(x') \,m(dx'|x) = m(A|x) = 1_A(x) = r(A|x), \end{align*} $$
$$ \begin{align*} \int_X r(A|x') \,m(dx'|x) = \int_X 1_A(x') \,m(dx'|x) = m(A|x) = 1_A(x) = r(A|x), \end{align*} $$
where we used invariance of A.
Let us now prove the universal property in equation (10). Let
 $s:X\to S$
be a right-invariant Markov kernel. Define the kernel
$s:X\to S$
be a right-invariant Markov kernel. Define the kernel
 $\tilde s:X_{\mathrm {inv}}\to S$
simply by
$\tilde s:X_{\mathrm {inv}}\to S$
simply by
for all
 $x\in X_{\mathrm {inv}}$
(equivalently,
$x\in X_{\mathrm {inv}}$
(equivalently,
 $x\in X$
) and all measurable
$x\in X$
) and all measurable
 $B\subseteq S$
. To see that
$B\subseteq S$
. To see that
 $\tilde s$
is measurable in x, consider a Borel-generating interval
$\tilde s$
is measurable in x, consider a Borel-generating interval
 $(r,1]\subseteq [0,1]$
for some
$(r,1]\subseteq [0,1]$
for some
 $0\le r < 1$
. We have to prove that the set
$0\le r < 1$
. We have to prove that the set
is measurable in
 $X_{\mathrm {inv}}$
, that is, as a subset of X, is measurable and invariant. We know that it is measurable as a subset of X, since s is a Markov kernel. Let us prove invariance. Using the fact that s is right-invariant (equation (6)), and that
$X_{\mathrm {inv}}$
, that is, as a subset of X, is measurable and invariant. We know that it is measurable as a subset of X, since s is a Markov kernel. Let us prove invariance. Using the fact that s is right-invariant (equation (6)), and that
 $\tilde s^*(B,r)$
is measurable as a subset of X,
$\tilde s^*(B,r)$
is measurable as a subset of X,
 $$ \begin{align*} s(B|x) &= \int_X s(B|x') \, m(dx'|x) \\ &= \int_{\tilde s^*(B,r)} s(B|x') \, m(dx'|x) + \int_{X\setminus \tilde s^*(B,r)} s(B|x') \, m(dx'|x). \end{align*} $$
$$ \begin{align*} s(B|x) &= \int_X s(B|x') \, m(dx'|x) \\ &= \int_{\tilde s^*(B,r)} s(B|x') \, m(dx'|x) + \int_{X\setminus \tilde s^*(B,r)} s(B|x') \, m(dx'|x). \end{align*} $$
Now let us use that m is deterministic, so that either we have
 $m(\tilde s^*(B,r)|x)=1$
or
$m(\tilde s^*(B,r)|x)=1$
or
 $m(X\setminus \tilde s^*(B,r)|x)=1$
. In the first case, we have that
$m(X\setminus \tilde s^*(B,r)|x)=1$
. In the first case, we have that
 $s(B|x')> r$
on a set of measure
$s(B|x')> r$
on a set of measure
 $1$
; therefore,
$1$
; therefore,
 $s(B|x)> r$
, i.e.
$s(B|x)> r$
, i.e.
 $x\in \tilde s^*(B,r)$
. In the latter case,
$x\in \tilde s^*(B,r)$
. In the latter case,
 $s(B|x') \le r$
on a set of measure
$s(B|x') \le r$
on a set of measure
 $1$
; therefore,
$1$
; therefore,
 $s(B|x) \le r$
, i.e.
$s(B|x) \le r$
, i.e.
 $x\notin \tilde s^*(B,r)$
. Since m is deterministic, these are the only possibilities, and so we have that
$x\notin \tilde s^*(B,r)$
. Since m is deterministic, these are the only possibilities, and so we have that
 $$ \begin{align*} m(\tilde s^*(B,r)|x) = \begin{cases} 1, & x \in \tilde s^*(B,r), \\ 0, & x\notin \tilde s^*(B,r). \end{cases} \end{align*} $$
$$ \begin{align*} m(\tilde s^*(B,r)|x) = \begin{cases} 1, & x \in \tilde s^*(B,r), \\ 0, & x\notin \tilde s^*(B,r). \end{cases} \end{align*} $$
This means precisely that
 $\tilde s^*(B,r)$
is invariant, and so
$\tilde s^*(B,r)$
is invariant, and so
 $\tilde s$
is measurable. Therefore,
$\tilde s$
is measurable. Therefore,
 $\tilde s$
is a well-defined Markov kernel
$\tilde s$
is a well-defined Markov kernel
 $X_{\mathrm {inv}}\to S$
.
$X_{\mathrm {inv}}\to S$
.
For uniqueness, note that
 $\tilde s$
is the only possible choice of kernel
$\tilde s$
is the only possible choice of kernel
 $X_{\mathrm {inv}}\to S$
making equation (10) commute: let
$X_{\mathrm {inv}}\to S$
making equation (10) commute: let
 $k:X_{\mathrm {inv}}\to S$
be another such kernel. Then, for all
$k:X_{\mathrm {inv}}\to S$
be another such kernel. Then, for all
 $x\in X$
and every measurable
$x\in X$
and every measurable
 $B\subseteq X$
,
$B\subseteq X$
,
 $$ \begin{align*} k(B|x) = \int_{X_{\mathrm{inv}}} k(B|x') \,\delta(dx'|x) = \int_{X_{\mathrm{inv}}} k(B|x') \, r(dx'|x) = s(B|x). \end{align*} $$
$$ \begin{align*} k(B|x) = \int_{X_{\mathrm{inv}}} k(B|x') \,\delta(dx'|x) = \int_{X_{\mathrm{inv}}} k(B|x') \, r(dx'|x) = s(B|x). \end{align*} $$
Moreover, by construction,
 $\tilde s$
is deterministic if and only if s is.
$\tilde s$
is deterministic if and only if s is.
3.3 Ergodic states
Definition 3.8. Let X be a dynamical system with monoid M in a Markov category
 ${\mathsf {C}}$
. An invariant state
${\mathsf {C}}$
. An invariant state
 $p:I\to X$
is ergodic if for every invariant deterministic observable
$p:I\to X$
is ergodic if for every invariant deterministic observable
 $c:X\to ~R$
, the composition
$c:X\to ~R$
, the composition
 $c\circ p$
is deterministic.
$c\circ p$
is deterministic.
Intuitively, an ergodic measure is an invariant state of the system such that every conserved quantity almost surely takes on a single definite value. In particular, invariant deterministic observations
 $c : X \to R$
cannot be used to ‘decompose’ the state p into disjoint invariant subsystems of X, since
$c : X \to R$
cannot be used to ‘decompose’ the state p into disjoint invariant subsystems of X, since
 $c \circ p$
being deterministic intuitively means that the state p is concentrated in a single fiber of c.
$c \circ p$
being deterministic intuitively means that the state p is concentrated in a single fiber of c.
Example 3.9. Let X be a standard Borel space and consider the infinite product
 $X^{\mathbb {N}}$
with the product
$X^{\mathbb {N}}$
with the product
 $\sigma $
-algebra. The group
$\sigma $
-algebra. The group
 $S_{\mathbb {N}}$
of finite, unbounded permutations of
$S_{\mathbb {N}}$
of finite, unbounded permutations of
 $\mathbb {N}$
acts on
$\mathbb {N}$
acts on
 $X^{\mathbb {N}}$
by permuting the components. Let now p be a measure on X. The infinite product measure
$X^{\mathbb {N}}$
by permuting the components. Let now p be a measure on X. The infinite product measure
 $p^{\otimes \mathbb {N}}$
on
$p^{\otimes \mathbb {N}}$
on
 $X^{\mathbb {N}}$
is clearly permutation-invariant. The Hewitt–Savage zero-one law [Reference Hewitt and Savage11] says that for every permutation-invariant deterministic observable
$X^{\mathbb {N}}$
is clearly permutation-invariant. The Hewitt–Savage zero-one law [Reference Hewitt and Savage11] says that for every permutation-invariant deterministic observable
 $c:X^{\mathbb {N}}\to R$
, the pushforward of
$c:X^{\mathbb {N}}\to R$
, the pushforward of
 $p^{\otimes \mathbb {N}}$
along c is a zero-one measure. As a zero-one measure is exactly a deterministic state according to our definition, the Hewitt–Savage zero-one law can be equivalently expressed as follows: for the dynamical system
$p^{\otimes \mathbb {N}}$
along c is a zero-one measure. As a zero-one measure is exactly a deterministic state according to our definition, the Hewitt–Savage zero-one law can be equivalently expressed as follows: for the dynamical system
 $X^{\mathbb {N}}$
with the dynamics given by
$X^{\mathbb {N}}$
with the dynamics given by
 $S_{\mathbb {N}}$
, any infinite product measure is ergodic.
$S_{\mathbb {N}}$
, any infinite product measure is ergodic.
A categorical proof of the Hewitt–Savage zero-one law, in terms of Markov categories, has been given in [Reference Fritz and Rischel8].
Our notion of ergodicity coincides with the traditional one in terms of invariant sets, by means of the following statement, which follows from the universal property of Markov colimits.
Proposition 3.10. Let X be a dynamical system with monoid M in a Markov category
 ${\mathsf {C}}$
, and suppose that the Markov colimit
${\mathsf {C}}$
, and suppose that the Markov colimit
 $X_{\mathrm {inv}}$
of X exists. An invariant state
$X_{\mathrm {inv}}$
of X exists. An invariant state
 $p:I\to X$
is ergodic if and only if the composition with the universal cocone
$p:I\to X$
is ergodic if and only if the composition with the universal cocone
is deterministic.
Proof. First, suppose that the composite
 $r\circ p$
is deterministic. Let
$r\circ p$
is deterministic. Let
 $c:X\to R$
be an invariant deterministic observable. By definition of Markov colimit, c factors (uniquely) as a composite
$c:X\to R$
be an invariant deterministic observable. By definition of Markov colimit, c factors (uniquely) as a composite
 $\tilde {c}\circ r$
, where
$\tilde {c}\circ r$
, where
 $\tilde {c}:X_{\mathrm {inv}}\to R$
is deterministic. Therefore,
$\tilde {c}:X_{\mathrm {inv}}\to R$
is deterministic. Therefore,
 $$ \begin{align*} c\circ p = \tilde{c}\circ r \circ p = \tilde{c}\circ (r\circ p) \end{align*} $$
$$ \begin{align*} c\circ p = \tilde{c}\circ r \circ p = \tilde{c}\circ (r\circ p) \end{align*} $$
is a composite of deterministic maps, and hence is deterministic. This is true for every invariant deterministic c, and so p is ergodic.
The converse follows by taking c in the definition of ergodicity to be
 $r:X\to X_{\mathrm {inv}}$
, which is deterministic and invariant.
$r:X\to X_{\mathrm {inv}}$
, which is deterministic and invariant.
Corollary 3.11. Let X be a deterministic dynamical system in
 ${\mathsf {Stoch}}$
. An invariant measure p on X is ergodic (according to our Definition 3.8) if and only if for every invariant measurable set A, we have
${\mathsf {Stoch}}$
. An invariant measure p on X is ergodic (according to our Definition 3.8) if and only if for every invariant measurable set A, we have
 $p(A)=0$
or
$p(A)=0$
or
 $p(A)=1$
(i.e. p is ergodic in the traditional sense).
$p(A)=1$
(i.e. p is ergodic in the traditional sense).
Compare, for example, with the traditional characterizations [Reference Tao20, Theorem 3] and [Reference Viana and Oliveira21, Proposition 4.1.3].
To state Theorem 3.15, it remains to consider families of states which are almost surely ergodic. In Definition 3.8, we required
 $p : I \to X$
to be an invariant state, but the definition still makes sense for an invariant morphism
$p : I \to X$
to be an invariant state, but the definition still makes sense for an invariant morphism
 $k : Y \to X$
(that is, with domain other than I). The development above generalizes immediately and, in particular, in
$k : Y \to X$
(that is, with domain other than I). The development above generalizes immediately and, in particular, in
 ${\mathsf {Stoch}}$
,
${\mathsf {Stoch}}$
,
 $k : Y \to X$
being ergodic simply says that each measure
$k : Y \to X$
being ergodic simply says that each measure
 $p_y$
on X for
$p_y$
on X for
 $y \in Y$
is ergodic. However, we cannot simply derive the meaning of ‘almost surely ergodic’ in the manner described after Definition 2.5, since ergodicity is not a purely equational notion. Nevertheless, it is natural to adopt the following definition.
$y \in Y$
is ergodic. However, we cannot simply derive the meaning of ‘almost surely ergodic’ in the manner described after Definition 2.5, since ergodicity is not a purely equational notion. Nevertheless, it is natural to adopt the following definition.
Definition 3.12. Let X be a dynamical system with monoid M in a Markov category
 ${\mathsf {C}}$
. Let Y be an object of
${\mathsf {C}}$
. Let Y be an object of
 ${\mathsf {C}}$
with a state
${\mathsf {C}}$
with a state
 $q : I \to Y$
and a morphism
$q : I \to Y$
and a morphism
 $k : Y \to X$
. We say that k is q-a.s. ergodic if:
$k : Y \to X$
. We say that k is q-a.s. ergodic if:
-
• k is q-a.s. invariant; and
-
• whenever
$r : X \to R$
is invariant and deterministic (not just almost surely), then
$r \circ k$
is q-a.s. deterministic.


The following is a straightforward adaptation of Proposition 3.10.
Proposition 3.13. Let X be a dynamical system with monoid M in a Markov category
 ${\mathsf {C}}$
, and suppose that the Markov colimit
${\mathsf {C}}$
, and suppose that the Markov colimit
 $X_{\mathrm {inv}}$
of X exists. Let Y be an object of
$X_{\mathrm {inv}}$
of X exists. Let Y be an object of
 ${\mathsf {C}}$
with a state
${\mathsf {C}}$
with a state
 $q : I \to Y$
and a q-a.s. invariant morphism
$q : I \to Y$
and a q-a.s. invariant morphism
 $k : Y \to X$
. Then k is q-a.s. ergodic if and only if the composition with the universal cocone
$k : Y \to X$
. Then k is q-a.s. ergodic if and only if the composition with the universal cocone
is q-a.s. deterministic.
Definition 3.12 is justified by what it means for
 ${\mathsf {Stoch}}$
.
${\mathsf {Stoch}}$
.
Corollary 3.14. Let X be a deterministic dynamical system in
 ${\mathsf {Stoch}}$
and let
${\mathsf {Stoch}}$
and let
 $q : I \to Y$
be a measure on some measurable space Y. A stochastic map
$q : I \to Y$
be a measure on some measurable space Y. A stochastic map
 $k : Y \to X$
on X is q-a.s. ergodic (according to our Definition 3.12) if and only if there is a measurable set
$k : Y \to X$
on X is q-a.s. ergodic (according to our Definition 3.12) if and only if there is a measurable set
 $E \subseteq Y$
with
$E \subseteq Y$
with
 $q(E) = 1$
such that
$q(E) = 1$
such that
 $k_y$
is ergodic (in the usual sense) for each
$k_y$
is ergodic (in the usual sense) for each
 $y \in E$
.
$y \in E$
.
Proof. By Proposition 3.7, the Markov quotient
 $r : X \to X_{\mathrm {inv}}$
exists. Suppose k satisfies the second condition, which, in particular, certainly means that k is q-a.s. invariant. Using Corollary 3.11, we see that
$r : X \to X_{\mathrm {inv}}$
exists. Suppose k satisfies the second condition, which, in particular, certainly means that k is q-a.s. invariant. Using Corollary 3.11, we see that
 $r \circ k$
is q-a.s. deterministic and hence, by Proposition 3.13, k is q-a.s. ergodic. For the converse, we can take a set
$r \circ k$
is q-a.s. deterministic and hence, by Proposition 3.13, k is q-a.s. ergodic. For the converse, we can take a set
 $E_1 \subseteq Y$
with
$E_1 \subseteq Y$
with
 $q(E_1) = 1$
and
$q(E_1) = 1$
and
 $p_y$
invariant for
$p_y$
invariant for
 $y \in E_1$
, and a set
$y \in E_1$
, and a set
 $E_2 \subseteq Y$
with
$E_2 \subseteq Y$
with
 $q(E_2) = 1$
and
$q(E_2) = 1$
and
 $(r \circ k)_y$
valued in
$(r \circ k)_y$
valued in
 $\{0,1\}$
. Now
$\{0,1\}$
. Now
 $E = E_1 \cap E_2$
is as required.
$E = E_1 \cap E_2$
is as required.
3.4 Main statement
Theorem 3.15. (Synthetic ergodic decomposition theorem)
Let
 ${\mathsf {C}}$
be a Markov category. Let X be a deterministic dynamical system in
${\mathsf {C}}$
be a Markov category. Let X be a deterministic dynamical system in
 ${\mathsf {C}}$
with monoid M. Suppose that:
${\mathsf {C}}$
with monoid M. Suppose that:
-
• the underlying object X of
${\mathsf {C}}$
has disintegrations; -
• the Markov colimit
$X_{\mathrm {inv}}$
of the dynamical system exists.


Then every invariant state of X can be written as a composition
 $k\circ q$
such that k is q-a.s. ergodic.
$k\circ q$
such that k is q-a.s. ergodic.
Let us now instantiate the theorem in
 ${\mathsf {Stoch}}$
, recalling that Markov colimits of deterministic dynamical systems always exist (Proposition 3.7).
${\mathsf {Stoch}}$
, recalling that Markov colimits of deterministic dynamical systems always exist (Proposition 3.7).
Corollary 3.16. Let X be a deterministic dynamical system in
 $\mathsf {Stoch}$
with monoid M (for example, with M acting via measurable functions
$\mathsf {Stoch}$
with monoid M (for example, with M acting via measurable functions
 $m:X\to X$
). Suppose that the measurable space X satisfies a disintegration theorem (for example, if it is a standard Borel space).
$m:X\to X$
). Suppose that the measurable space X satisfies a disintegration theorem (for example, if it is a standard Borel space).
Then every invariant measure on X can be written as a mixture of ergodic states.
Compare this with the traditional statements [Reference Viana and Oliveira21, Theorem 5.1.3], [Reference Tao20, Proposition 4]. Note also that the statement holds regardless of the cardinality or extra structure of the monoid M.
Now that all the necessary categorical setting is in place, the proof is very concise. Before looking at it, let us explain the intuition behind it a little. Since the Markov colimit exists (for example, the invariant
 $\sigma $
-algebra), we have a ‘weak quotient’ map
$\sigma $
-algebra), we have a ‘weak quotient’ map
 $r:X\to X_{\mathrm {inv}}$
which intuitively forgets the distinction between points that lie on the same orbit. We then construct a disintegration
$r:X\to X_{\mathrm {inv}}$
which intuitively forgets the distinction between points that lie on the same orbit. We then construct a disintegration
 $r^+_p:X_{\mathrm {inv}}\to X$
. Intuitively, this kernel maps each orbit back to a measure on X which is:
$r^+_p:X_{\mathrm {inv}}\to X$
. Intuitively, this kernel maps each orbit back to a measure on X which is:
-
• supported on the given orbit (i.e.
$r^+$
is a stochastic section of r almost surely); -
• uniform within the given orbit (i.e.
$r^+$
is almost surely ergodic).


This disintegration then expresses p as a mixture of ergodic measures.
Let us now look at the proof.
Proof of Theorem 3.15
Let
 $p:I\to X$
be an invariant state. Consider the map
$p:I\to X$
be an invariant state. Consider the map
 ${r:X\to X_{\mathrm {inv}}}$
, and form the disintegration
${r:X\to X_{\mathrm {inv}}}$
, and form the disintegration
 $r^+_p:X_{\mathrm {inv}}\to X$
.
$r^+_p:X_{\mathrm {inv}}\to X$
.

By marginalizing the equation above over
 $X_{\mathrm {inv}}$
, we see that
$X_{\mathrm {inv}}$
, we see that
 $p=r^+_p \circ r\circ p$
, i.e. we are decomposing p into the composition of
$p=r^+_p \circ r\circ p$
, i.e. we are decomposing p into the composition of
 $r\circ p:I\to X_{\mathrm {inv}}$
followed by
$r\circ p:I\to X_{\mathrm {inv}}$
followed by
 $r^+_p$
. Now denote
$r^+_p$
. Now denote
 $r\circ p$
by q.
$r\circ p$
by q.
Let us show that
 $r^+_p$
is q-a.s. ergodic. To see that
$r^+_p$
is q-a.s. ergodic. To see that
 $r^+_p$
is q-a.s. left-invariant, note that for all
$r^+_p$
is q-a.s. left-invariant, note that for all
 $m\in M$
,
$m\in M$
,

using, in order, the definition of
 $r^+_p$
as a disintegration, right-invariance of r, determinism of m, left-invariance of p, and again the definition of
$r^+_p$
as a disintegration, right-invariance of r, determinism of m, left-invariance of p, and again the definition of
 $r^+_p$
as a disintegration.
$r^+_p$
as a disintegration.
By Proposition 3.13, all that remains to be shown to prove q-almost sure ergodicity is that
 $r\circ r^+_p$
is q-a.s. deterministic. To see this, note that since r is deterministic, we can apply Proposition 2.7 with r in place of f. The proposition tells us that
$r\circ r^+_p$
is q-a.s. deterministic. To see this, note that since r is deterministic, we can apply Proposition 2.7 with r in place of f. The proposition tells us that
 $r\circ r^+_p$
is q-a.s. equal to the identity, which is deterministic.
$r\circ r^+_p$
is q-a.s. equal to the identity, which is deterministic.
As one can see, at this level, all the measure-theoretic and analytic details are taken care of by the formalism, and one can focus on the conceptual reasoning.
Acknowledgements
We would like to thank Tobias Fritz, Tomáš Gonda, and Dario Stein for the interesting discussions on Markov categories, and Sharwin Rezagholi for the inspiring conversations on dynamical systems and ergodic theory. We would also like to thank Sam Staton and his research group for the support and for the helpful feedback.
A Appendix. The invariant sigma-algebra as a weak quotient
Let us now explain why X with the invariant
 $\sigma $
-algebra can play the role of a space of orbits. (See §§2.1, 3.2, and 3.4 for context.)
$\sigma $
-algebra can play the role of a space of orbits. (See §§2.1, 3.2, and 3.4 for context.)
We first consider the intrinsic ‘indistinguishability relation’ on a measurable space. For a measurable space
 $(Y,\Sigma _Y)$
, this is the equivalence relation given by
$(Y,\Sigma _Y)$
, this is the equivalence relation given by
 $y\sim y'$
if and only if for every measurable set
$y\sim y'$
if and only if for every measurable set
 $A\in \Sigma _Y$
,
$A\in \Sigma _Y$
,
 $y\in A$
if (and only if)
$y\in A$
if (and only if)
 $y'\in Y$
. The relation
$y'\in Y$
. The relation
 $\sim $
is discrete (coincides with equality) if, for example:
$\sim $
is discrete (coincides with equality) if, for example:
-
• Y is a
$T_0$
topological space (for example, sober or Hausdorff) equipped with the Borel
$\sigma $
-algebra; -
• Y has the property that all singletons are measurable.


In particular,
 $\sim $
is discrete if Y is a standard Borel space.
$\sim $
is discrete if Y is a standard Borel space.
Proposition A.1. The relation
 $\sim $
is the kernel of the map
$\sim $
is the kernel of the map

assigning to each point y the Dirac distribution over it. In particular, the relation
 $\sim $
is discrete if and only if the map
$\sim $
is discrete if and only if the map
 $\delta $
is injective.
$\delta $
is injective.
(See [Reference Moss and Perrone18] for additional context on injectivity of the map
 $\delta $
.)
$\delta $
.)
Proposition A.2. The following conditions are equivalent for elements
 $y,y'$
of a measurable space
$y,y'$
of a measurable space
 $(Y,\Sigma _Y)$
:
$(Y,\Sigma _Y)$
:
-
•
$y\sim y'$
; -
• for every measurable real function
$f:Y\to \mathbb {R}$
,
$f(y)=f(y')$
; -
• for every Markov kernel k from Y to a space Z and every
$C\in \Sigma _Z$
,
$k(C|y)=k(C|y')$
.





Therefore, Markov kernels are ‘blind’ to indistinguishable elements. In particular, two measurable spaces can be isomorphic in the category of deterministic Markov kernels
 ${\mathsf {Stoch}}_{\det }$
even if they have different underlying sets. The following proposition illustrates a canonical example.
${\mathsf {Stoch}}_{\det }$
even if they have different underlying sets. The following proposition illustrates a canonical example.
Proposition A.3. Let
 $(Y,\Sigma _Y)$
be a measurable space, let
$(Y,\Sigma _Y)$
be a measurable space, let
 $Y/_\sim $
be the quotient space w.r.t. the indistinguishability relation, and denote by
$Y/_\sim $
be the quotient space w.r.t. the indistinguishability relation, and denote by
 $q:Y\to Y/_\sim $
the quotient map
$q:Y\to Y/_\sim $
the quotient map
 $y\mapsto [y]$
. If we equip
$y\mapsto [y]$
. If we equip
 $Y/_\sim $
with the quotient
$Y/_\sim $
with the quotient
 $\sigma $
-algebra, so that q is measurable, the Markov kernel induced by q is an isomorphism of
$\sigma $
-algebra, so that q is measurable, the Markov kernel induced by q is an isomorphism of
 ${\mathsf {Stoch}}_{\det }$
. That is, the deterministic kernel induced by q has a deterministic (i.e. zero-one) inverse in the category of Markov kernels.
${\mathsf {Stoch}}_{\det }$
. That is, the deterministic kernel induced by q has a deterministic (i.e. zero-one) inverse in the category of Markov kernels.
(In this section, q will denote a quotient map, rather than a state or measure.)
Note that an isomorphism in the category of deterministic kernels, even though the underlying sets may differ, does imply that the sigma algebras are isomorphic. More on this shortly.
Let us now return to dynamical systems. Let X be a dynamical system in
 ${\mathsf {Stoch}}$
where the monoid M acts by measurable functions
${\mathsf {Stoch}}$
where the monoid M acts by measurable functions
 $m : X \to X$
in
$m : X \to X$
in
 ${\mathsf {Meas}}$
—recall that this is a special case of a deterministic dynamical systems in our terminology. We will show that the traditional quotient and the space
${\mathsf {Meas}}$
—recall that this is a special case of a deterministic dynamical systems in our terminology. We will show that the traditional quotient and the space
 $X_{\mathrm {inv}}$
are isomorphic in
$X_{\mathrm {inv}}$
are isomorphic in
 ${\mathsf {Stoch}}$
via deterministic (in our terminology) kernels.
${\mathsf {Stoch}}$
via deterministic (in our terminology) kernels.
Denote by
 $\sim _M$
the equivalence relation on X generated by the action of M. As usual,
$\sim _M$
the equivalence relation on X generated by the action of M. As usual,
 $x\sim _M y$
if and only if there exists a ‘zig-zag’ connecting x and y, explicitly, a finite sequence
$x\sim _M y$
if and only if there exists a ‘zig-zag’ connecting x and y, explicitly, a finite sequence
 $m_1,\dots ,m_n\in M$
and elements
$m_1,\dots ,m_n\in M$
and elements
 $x_0,x_1,\dots ,x_n\in X$
with
$x_0,x_1,\dots ,x_n\in X$
with
 $x_0=x$
,
$x_0=x$
,
 $x_n=y$
, and such that:
$x_n=y$
, and such that:
-
• for odd i,
$m_i(x_{i-1})=x_i$
; -
• for even i,
$m_i(x_i)=x_{i-1}$
.


For
 $n=6$
, the situation is represented by the following picture.
$n=6$
, the situation is represented by the following picture.

(Note that such a zig-zag is necessary if M is not a group.)
Now let
 $X/M$
be the quotient of X w.r.t. the relation
$X/M$
be the quotient of X w.r.t. the relation
 $\sim _M$
, and denote by
$\sim _M$
, and denote by
 $q:X\to X/M$
the quotient map. If we equip
$q:X\to X/M$
the quotient map. If we equip
 $X/M$
with the quotient
$X/M$
with the quotient
 $\sigma $
-algebra, so that q is measurable, the outer triangle in the following diagram commutes for all
$\sigma $
-algebra, so that q is measurable, the outer triangle in the following diagram commutes for all
 $m\in M$
.
$m\in M$
.

Therefore, the map
 $q:X\to X/M$
is also measurable for the invariant
$q:X\to X/M$
is also measurable for the invariant
 $\sigma $
-algebra, i.e. it descends to
$\sigma $
-algebra, i.e. it descends to
 $X_{\mathrm {inv}}$
as a measurable map
$X_{\mathrm {inv}}$
as a measurable map
 $\tilde q$
, making the diagram above commute.
$\tilde q$
, making the diagram above commute.
Theorem A.4. Let X be a deterministic dynamical system in
 ${\mathsf {Stoch}}$
with monoid M acting by measurable functions
${\mathsf {Stoch}}$
with monoid M acting by measurable functions
 $m:X\to X$
. Construct the quotient map
$m:X\to X$
. Construct the quotient map
 $q:X\to X/M$
as described above. Then the kernel
$q:X\to X/M$
as described above. Then the kernel
 $X_{\mathrm {inv}}\to X/M$
induced by the measurable map
$X_{\mathrm {inv}}\to X/M$
induced by the measurable map
 $\tilde q$
is an isomorphism of
$\tilde q$
is an isomorphism of
 ${\mathsf {Stoch}}_{\det }$
. That is, it has a deterministic (i.e. zero-one) inverse in the category of Markov kernels.
${\mathsf {Stoch}}_{\det }$
. That is, it has a deterministic (i.e. zero-one) inverse in the category of Markov kernels.
Note that this is the case regardless of the particular
 $\sigma $
-algebra of the original space X, and regardless of the cardinality or structure of the monoid M.
$\sigma $
-algebra of the original space X, and regardless of the cardinality or structure of the monoid M.
Lemma A.5. Assume the hypotheses of Theorem A.4. Let
 $A\subseteq X$
be an invariant set. If
$A\subseteq X$
be an invariant set. If
 $x\sim _M y$
, then
$x\sim _M y$
, then
 $x\in A$
if and only if
$x\in A$
if and only if
 $y\in A$
.
$y\in A$
.
Proof of Lemma A.5
Invariance of A means that
 $x\in A$
if and only if
$x\in A$
if and only if
 $m(x)\in A$
for all
$m(x)\in A$
for all
 $m\in M$
. Now let
$m\in M$
. Now let
 $x\sim y$
, so that there is a zig-zag given by
$x\sim y$
, so that there is a zig-zag given by
 $m_1,\dots ,m_n\in M$
and
$m_1,\dots ,m_n\in M$
and
 ${x=x_0,\dots ,x_n=y}$
, as above. Then for all
${x=x_0,\dots ,x_n=y}$
, as above. Then for all
 $i=1,\dots n$
(odd or even), we have
$i=1,\dots n$
(odd or even), we have
 $x_{i-1}\in A$
if and only if
$x_{i-1}\in A$
if and only if
 $x_i\in A$
. Therefore,
$x_i\in A$
. Therefore,
 $x=x_0\in A$
if and only if
$x=x_0\in A$
if and only if
 $y=x_n\in A$
.
$y=x_n\in A$
.
Lemma A.6. Under the hypotheses of Theorem A.4, the preimage map
 $q^{-1}:\Sigma _{X/M}\to \Sigma _{X_{\mathrm {inv}}}$
is a bijection.
$q^{-1}:\Sigma _{X/M}\to \Sigma _{X_{\mathrm {inv}}}$
is a bijection.
Proof of Lemma A.6
First of all,
 $q^{-1}:\Sigma _{X/M}\to \Sigma _{X_{\mathrm {inv}}}$
is injective since
$q^{-1}:\Sigma _{X/M}\to \Sigma _{X_{\mathrm {inv}}}$
is injective since
 $q:X_{\mathrm {inv}}\to X/M$
is surjective by construction. Moreover, we have that
$q:X_{\mathrm {inv}}\to X/M$
is surjective by construction. Moreover, we have that
 $$ \begin{align} q^{-1}(q(A)) = A \end{align} $$
$$ \begin{align} q^{-1}(q(A)) = A \end{align} $$
for each measurable invariant set
 $A\in \Sigma _{X_{\mathrm {inv}}}$
. We have as usual
$A\in \Sigma _{X_{\mathrm {inv}}}$
. We have as usual
 $A\subseteq q^{-1}(q(A)$
. For the reverse inclusion, let
$A\subseteq q^{-1}(q(A)$
. For the reverse inclusion, let
 $x\in q^{-1}(q(A))$
, i.e. such that
$x\in q^{-1}(q(A))$
, i.e. such that
 $[x]\in q(A)$
. This means that there exists
$[x]\in q(A)$
. This means that there exists
 $a\in A$
with
$a\in A$
with
 $[x]=[a]$
, i.e.
$[x]=[a]$
, i.e.
 $x\sim a$
. However, since A is invariant, by Lemma A.5, if
$x\sim a$
. However, since A is invariant, by Lemma A.5, if
 $a\in A$
and
$a\in A$
and
 $x\sim _M a$
, then
$x\sim _M a$
, then
 $x\in A$
as well.
$x\in A$
as well.
Proof of Theorem A.4
Construct the kernel
 $h:X/M\to X_{\mathrm {inv}}$
as follows, for each
$h:X/M\to X_{\mathrm {inv}}$
as follows, for each
 $[x]\in X/M$
and each invariant
$[x]\in X/M$
and each invariant
 $A\in \Sigma _{X_{\mathrm {inv}}}$
.
$A\in \Sigma _{X_{\mathrm {inv}}}$
.

This is well defined: by Lemma A.5, and since A is invariant, for
 $x\sim _M y$
,
$x\sim _M y$
,
 $x\in A$
if and only if
$x\in A$
if and only if
 $y\in A$
.
$y\in A$
.
To see measurability in
 $[x]$
, it suffices to prove that the following subset of
$[x]$
, it suffices to prove that the following subset of
 $X/M$
is measurable for each invariant set A.
$X/M$
is measurable for each invariant set A.

By the definition of quotient
 $\sigma $
-algebra, it suffices to show that
$\sigma $
-algebra, it suffices to show that
 $q^{-1}(q(A))$
is a measurable subset of X. However, now by equation (A.1),
$q^{-1}(q(A))$
is a measurable subset of X. However, now by equation (A.1),
 $q^{-1}(q(A)) = A$
, which is measurable. So
$q^{-1}(q(A)) = A$
, which is measurable. So
 $q(A)$
is a measurable set, and hence h is a measurable kernel.
$q(A)$
is a measurable set, and hence h is a measurable kernel.
To see that h inverts q, notice that for every
 $x\in X$
and every measurable
$x\in X$
and every measurable
 $A\in \Sigma _X$
,
$A\in \Sigma _X$
,
 $$ \begin{align*} h(A|q(x)) = h(A|[x]) = 1_A(x) , \end{align*} $$
$$ \begin{align*} h(A|q(x)) = h(A|[x]) = 1_A(x) , \end{align*} $$
which is the identity kernel. Just as well, for each
 $[x]\in X/M$
and
$[x]\in X/M$
and
 $B\in \Sigma _{X/M}$
,
$B\in \Sigma _{X/M}$
,
 $$ \begin{align*} q_*h(B|[x]) = h(q^{-1}(B)|[x]) = 1_{q^{-1}(B)}(y) = 1_B([x]) , \end{align*} $$
$$ \begin{align*} q_*h(B|[x]) = h(q^{-1}(B)|[x]) = 1_{q^{-1}(B)}(y) = 1_B([x]) , \end{align*} $$
once again the identity kernel.
Now, usually the orbit space plays the role of classifying invariant observables, in the sense that an observable is invariant if and only if it descends to the orbit space in a well-defined way. In our case, the invariant
 $\sigma $
-algebra takes care of this without the need of actually taking the quotient. In general, especially if the cardinality of M is large, the set-theoretic quotient of X can be very badly behaved as a measurable space. Considering the object
$\sigma $
-algebra takes care of this without the need of actually taking the quotient. In general, especially if the cardinality of M is large, the set-theoretic quotient of X can be very badly behaved as a measurable space. Considering the object
 $X_{\mathrm {inv}}$
in the Markov category
$X_{\mathrm {inv}}$
in the Markov category
 ${\mathsf {Stoch}}$
, instead, one avoids having to deal with ‘bad’ quotients. It is still true that, in general, the
${\mathsf {Stoch}}$
, instead, one avoids having to deal with ‘bad’ quotients. It is still true that, in general, the
 $\sigma $
-algebra of
$\sigma $
-algebra of
 $X_{\mathrm {inv}}$
does not separate points, but this is less of a problem in
$X_{\mathrm {inv}}$
does not separate points, but this is less of a problem in
 ${\mathsf {Stoch}}$
and
${\mathsf {Stoch}}$
and
 ${\mathsf {Stoch}}_{\det }$
, since those categories do not really deal with points, but rather with ‘points up to indistinguishability.’ The situation is analogous to what happens in homotopy theory when one takes ‘weak quotients’ or other similar constructions, such as resolutions.
${\mathsf {Stoch}}_{\det }$
, since those categories do not really deal with points, but rather with ‘points up to indistinguishability.’ The situation is analogous to what happens in homotopy theory when one takes ‘weak quotients’ or other similar constructions, such as resolutions.
