



1. Introduction
Coreference assignment and how it is achieved by means of syntax, semantics, and pragmatics is a topic of debate among linguistic theorists as well as researchers concerned with language processing. Depending on the theory and the type of referent-dependent item in discussion, different dependencies seem to have varying effects on coreference processing. Some studies investigate antecedent reactivation using reaction time experiments predicting facilitation by priming (e.g. Nicol & Swinney, Reference Nicol and Swinney1989; Hestvik et al., Reference Hestvik, Nordby and Karlsen2005, Reference Hestvik, Schwartz and Tornyova2010; Larsen & Johansson, Reference Larsen and Johansson2020), while others analyze interference effects (e.g. Parker et al., Reference Parker, Lago and Phillips2015; Sturt & Kwon, Reference Sturt and Kwon2015). Priming occurs when some item, whether it be a word, image, or part of a syntactic representation, facilitates the processing of an upcoming item or word. This process allows for an early activation of said item by preparing or pre-activating it for faster processing. Interference takes place in a similar manner, but it has the opposite effect on participant reaction times, for example by activating a competitor. Slower reaction times are explained by interference with the processing of an upcoming item. This can be due to semantic or syntactic competition. Both effects generally occur undetected by the participant.
Our research focuses on non-finite Control constructions and the null pronoun (PRO) that fills the subject position of Control clauses. We aim to investigate coreference processing in Norwegian non-finite clauses and complement clauses containing a pronoun. Our experimental design takes into consideration the position and pattern of antecedent reactivation. We investigate NP reactivation interference effects when in competition with the infinitive marker/complementizer and the subordinate clause verb. We then combine our findings with previous research on Control in Norwegian to discuss the theoretical implications of real-time language processing data.
1.1 Non-finite clauses and PRO
In non-finite clauses, PRO occupies the subject position of the clause as a covert pronoun (Chomsky, Reference Chomsky1981). Example 1.1 presents a Control sentence in English in which PRO is coreferent with the subject of the matrix clause. This is called Subject Control. Depending on the sentence, PRO can be controlled by the subject or object of the matrix clause, or by a noun phrase from outside of the sentence.
Control constructions are found in all languages that contain non-finite clauses (Bisang, Reference Bisang and Haspelmath2008); however, that leads to the presumption that PRO is the same across these languages. The established characteristics of PRO have evolved throughout the years (Reed, Reference Reed2014), yet the underlying assumption that these characteristics remain the same regardless of language has become increasingly difficult to support. Sigursson (Reference Sigursson2008) argues that PRO in Icelandic can be assigned dative case. If one of the established characteristics of PRO is that it is always assigned null case (Chomsky & Lasnik, Reference Chomsky and Lasnik1993), we already see an issue with claiming the existence of a universal PRO.
Our research investigates Control constructions in Norwegian. Much of the research on Control has been done using English. English and Norwegian have arguably similar surface structures when it comes to non-finite Control clauses; however, the standard analysis of Norwegian non-finite clauses has been to consider the infinitive marker å as a complementizer, as shown in (2a) (Faarlund et al., Reference Faarlund, Svein and Vannebo1997; Åfarli et al., Reference Åfarli and Eide2003; Faarlund, Reference Faarlund2007). In English, though, the infinitive marker to is commonly represented in the position of the tense head, T, as shown in (2b) (See Carnie, Reference Carnie2013).

Support for the infinitive marker being positioned in C in Norwegian relies on the sentence position of adverbials in non-finite clauses being flexible. This positioning allows finite and non-finite clauses to maintain similar syntactic structures (Faarlund, Reference Faarlund2015).
There are other theories of Control that propose an analysis of non-finite clauses that does not contain PRO. One theory of Control suggests that they are formed by movement in a manner similar to Raising, and this would make the subject of the non-finite clause a regular NP trace (Hornstein, Reference Hornstein1999). Another theory maintains a similar claim and states that Control should be handled by A-movement but treated differently than Raising (Hornstein & Polinsky, Reference Hornstein, Polinsky, Hornstein and Polinsky2010). Yet another approach accounts for Control using an alternative theory of theta roles. Theta role percolation (Neeleman & van de Koot, Reference Neeleman and van de Koot2002) is used to reinterpret the subject properties of controlled infinitives, which allows theta roles to regulate case on the predicate without necessitating PRO (Janke, Reference Janke2003, Reference Janke2007, Reference Janke2008).
These competing theories generate more questions. Are Control constructions processed similarly to other constructions containing referent-dependent items? If so, which ones? Can we determine the syntactic properties of PRO using experimental methods? Do constructions with similar syntactic structures but different dependencies, such as finite complement clauses, display effects for coreference processing? We examine these questions by comparing the processing effects of PRO and pronouns in non-finite and finite clauses in Norwegian. The effects are contrasted with current theories of Control to consider which proposed syntactic properties of PRO are supported by our results.
1.2 Finite clauses and pronouns
PRO has been called a null pronoun, having properties similar to both anaphors and pronouns. PRO has been compared to NP traces both theoretically (Hornstein, Reference Hornstein1999; Hornstein & Polinsky, Reference Hornstein, Polinsky, Hornstein and Polinsky2010) and empirically (e.g. Nicol & Swinney, Reference Nicol and Swinney1989; Walenski, Reference Walenski2002; Larsen & Johansson, Reference Larsen and Johansson2020). PRO and NP traces have the common characteristic of being phonologically null. Since another characteristic of PRO is that it is a pronoun, it should also be studied in relation to overt pronouns.
The umbrella term ’complement clause’ encompasses both finite and non-finite clauses. Non-finite clauses contain PRO while finite clauses are less selective. Since theories of Generative Grammar allow Norwegian finite and non-finite clauses to hold a similar syntactic structure, it enables these minimal differences in structure to be tested and manipulated experimentally. A pronoun can be placed in a finite clause in the same position in which PRO would appear in a non-finite clause.

We explore this in our study, assuming minimal differences based on the input provided to the parser before the test positions. Looking at (3), it is apparent that the continuation of the sentence cannot be predicted prior to the presentation of the infinitive marker or complementizer. If PRO behaves like a pronoun, we would expect to observe the same pattern of antecedent reactivation.
1.3 Anaphor interpretation and coreference processing
There is a plethora of theories on anaphora and pronoun interpretation. One prominent theory is Centering Theory (CT) (Grosz et al., Reference Grosz, Joshi and Weinstein1995; Johshi & Prasad, Reference Johshi and Prasad2006), which states that particular antecedents are more central in discourse than others. The ranking of antecedents is defined by morphogrammatical properties, particularly grammatical role (Kehler & Rohde, Reference Kehler and Rohde2013). Resolution may occur immediately or be delayed, depending on when the information is available. A competing theory by Hobbs (1979,Reference Hobbs1990) focuses on the role that world knowledge and coherence relations play on pronoun interpretation. This theory may more easily account for referent-swapping constructions, such as the one given in Example 1.3, since it is not strictly based on factors such as grammatical form and information structure. In 1.3, PRO is able to swap from being coreferent with the subject of the matrix clause (a) to being coreferent with an NP from outside of the sentence (b). Recent theories combine the two into a model that can account for incremental interpretation and contextual influences (Kehler & Rohde, Reference Kehler and Rohde2013).

Experimental data supports CT in its claims that grammatical information is available to the parser during anaphor processing; however, the same data shows that some sentences must be fully processed prior to antecedent assignment. Previous research on antecedent assignment and pronouns has found that the set of all potential antecedents are reactivated at the position of the pronoun during on-line processing (Corbett & Chang, Reference Corbett and Chang1983; Nicol, Reference Nicol1988; Nicol & Swinney, Reference Nicol and Swinney1989; MacDonald & MacWhinney, Reference MacDonald and MacWhinney1990; Nicol & Swinney, Reference Nicol, Swinney and Barss2002, a.o.). Evidence shows that the activation of potential antecedents occurs in compliance with binding constraints (Nicol, Reference Nicol1988; Clifton et al., Reference Clifton, Kennison and Albrecht1997; Sturt, Reference Sturt2003). This means that pronouns do not reactivate NPs contained within their binding domain.
Other information has been found to affect pronoun antecedent assignment and the time course of resolution. Research shows that information richness (Karimi & Ferreira, Reference Karimi and Ferreira2016) and implicit causality play a role in pronoun interpretation during integration (Stewart et al., Reference Stewart, Pickering and Sanford2000; Järvikivi et al., Reference Järvikivi, van Gompel and Hyönä2017; Weatherford & Arnold, Reference Weatherford and Arnold2021). This suggests that predictability influences coreference processing.
Though some results indicate that semantic information is utilized as soon as an attempt at pronoun resolution is made, other research demonstrates that syntactic information is vital to this process. There is evidence that number and grammatical gender are accessed during on-line processing (Ehrlich & Rayner, Reference Ehrlich and Rayner1983; Arnold, Reference Arnold1998; Arnold et al., Reference Arnold, Eisenband, Brown-Schmidt and Trueswell2000; Aoshima et al., Reference Aoshima, Yoshida and Phillips2009). It seems that the ability of the parser to integrate a variety of information at first pass leads to the delay of pronoun resolution (Ehrlich & Rayner, Reference Ehrlich and Rayner1983; Stewart et al., Reference Stewart, Holler and Kidd2007). Arnold et al. (Reference Arnold, Eisenband, Brown-Schmidt and Trueswell2000) suggests that this supports a dynamic model of language processing where information contributes to probabilistic pronoun resolution. This is similar to the combined theory of anaphora and pronoun interpretation proposed by Kehler & Rohde (Reference Kehler and Rohde2013).
The exact role of all linguistic elements in the process of pronoun resolution is still unknown. There have been various suggestions as to what influences this process in the literature throughout the years (See Cowles et al., Reference Cowles, Walenski and Kluender2007, for an overview). Though preferences such as those for antecedents with the same thematic role or grammatical relation may affect pronoun processing, this is not something we explore in this article. One interesting hypothesis that could affect our empirical findings is posited by Nicol & Swinney (Reference Nicol, Swinney and Barss2002). They suggest that the occurrence of a pronoun only triggers immediate reactivation of a set of potential antecedents when presented auditorily. Though they mention that this might be an issue of participant engagement rather than presentation method. Reading requires active participation in the task.
Previous research demonstrates the importance of pinpointing and understanding the factors that affect coreference processing. For our study, we attempt to control as many of these factors as possible by limiting outside information such as context. Prior knowledge concerning the NPs included in the sentence stimuli is considered as well. We focus primarily on investigating morphogrammatical properties and how the parser incorporates them during processing and interpretation.
1.4 Control processing
Nicol & Swinney (Reference Nicol and Swinney1989) present a compilation of research on English investigating the reactivation of various referent-dependent items during sentence processing. This research examines the time course of coreference processing that occurs in English in relation to wh-traces, NP-traces, overt anaphors, pronouns, and PRO. The experimental designs are motivated by the Trace Reactivation Hypothesis which states that a reference-dependent item causes reactivation of its antecedent NP. They discuss studies that focus on cross-modal priming, an online psycholinguistic method developed by Swinney (Reference Swinney1979), that measures the activation of lexical and syntactic information as participants read or listen to sentences in real-time. They find that syntactic constraints play a key role in restricting the reactivation of potential antecedents. When the grammar specifies a unique antecedent then only that antecedent is immediately reactivated at the position of the referent-dependent item; however, they found that pronouns and PRO reactivate multiple potential antecedents. Nicol and Swinney hypothesize that the final antecedent selection occurs later for pronouns and PRO than for wh- and NP traces because more information is typically needed for the parser to make the correct selection.
Parker et al. (Reference Parker, Lago and Phillips2015) investigated the processing of adjunct Control dependencies in English by testing interference effects during memory retrieval. Prior research on interference effects suggested that anaphors subject to structural constraints are immune to interference (Sturt, Reference Sturt2003; Xiang et al., Reference Xiang, Dillon and Phillips2009; Dillon et al., Reference Dillon, Mishler, Slogget and Phillips2013). To examine this claim, Parker et al. (Reference Parker, Lago and Phillips2015) ran a self-paced reading experiment to explore whether retrieval of null subject licensing in English was susceptible to interference from distractors in structurally inappropriate locations. They focused on measuring a memory retrieval error called facilitatory interference, which arises when a structurally inappropriate but feature matching item facilitates the processing of an ill-formed linguistic dependency. Their results showed that PRO in adjunct Control (though they do not use this specific term for the name of the null pronoun) was subject to facilitatory interference at two sentence positions, at the gerundive verb and the reflexive. See (5) for an example of two grammatical adjunct Control conditions with these positions marked. This suggests that adjunct Control dependencies are indeed susceptible to facilitatory interference, contrary to previous claims. This implies that PRO might also be vulnerable to other types of interference effects.

Witzel & Witzel (Reference Witzel and Witzel2016) examined whether antecedents are assigned in Japanese Control sentences before verb information becomes available and whether there are biases that drive the process. They used a lexicality maze (L-maze) task to test preverbal analysis of empty subjects. In maze tasks, participants are presented with two alternative continuations of a sentence and must select the correct choice between the two. The L-maze task is similar to that of G-maze, discussed further in Sections 1.4 and 2, but it uses decisions between a real word and a legal nonword. The results showed an Object Control bias. The main-clause object was initially assigned as the antecedent of PRO before reanalysis. It is suggested that this might be due to a preference for the most recent antecedent.
Kwon & Sturt (Reference Kwon and Sturt2016) conducted an eye-tracking experiment with a gender match/mismatch paradigm to study the processing of nominal Control in English. The goal was to investigate the initial access and use of nominal Control information during on-line processing. Participants read sentence stimuli from a screen while their eye movements were tracked. The results supported a recency preference for the processing of nominal Control and the claim that Control information constrains dependency formation during on-line interpretation.
Green et al. (Reference Green, McCourt, Lau and Williams2020) performed an eye-tracking study on adjunct Control in English. These constructions differ from complement Control because they contain a participial clause that is not selected by any element of the matrix clause. The study used an onset-contingent analysis to examine how quickly reference was resolved for PRO and overt pronoun conditions. They found no difference in resolution speed between PRO and pronoun conditions at the cue position (non-finite verb or pronoun). They claim that this means that listeners use structural information as quickly as morphological features when searching for an antecedent.
Delgado et al. (Reference Delgado, Raposo and Santos2021) focus their research on the processing of object and subject relatives in comparison to Object and Subject Control in European Portuguese. They designed a self-paced reading task with a moving-window display. Participants were asked to complete additional tasks during the study to measure resistance to interference, lexical knowledge, working memory capacity, and lexical access ability. They found that object relatives were harder to process than subject relatives. This was not the case for Object and Subject Control. They state that this is evidence against movement accounts of Control, where PRO is treated similarly to NP traces (Hornstein, Reference Hornstein1999).
Our earlier research on Control includes two reaction time experiments, using a word-to-image priming design (Larsen & Johansson, Reference Larsen and Johansson2020). Participants were asked to read a sentence word by word and, when presented with an image, to decide whether or not that image had been presented previously in the sentence in word form. We predicted that the presentation of the correct antecedent in an image format at the position of PRO would facilitate a quicker response. Figure 1 illustrates two priming conditions and the two test positions, directly before and after the infinitive marker. We detected significant facilitation effects for all potential PRO antecedents in Subject Control sentences after the infinitive marker in the non-finite clause in Norwegian. These results were obtained in comparison to a baseline taken from responses to the condition in which the other mentioned, but incorrect, image of a potential antecedent was shown to the participant. This isolates the effect of reactivation from the effect of being mentioned previously, leaving a measure of purely syntactic reactivation.

Figure 1. An example of the two priming types (baseline is not included) and the two test positions in the study done by Larsen & Johansson (Reference Larsen and Johansson2020).
The research that has been conducted thus far on Control and non-finite clauses in various languages suggests that PRO is processed differently than other referent-dependent items, such as NP traces and pronouns. It also shows that at least some types of Control are susceptible to interference during sentence processing and that this can be investigated using self-paced reading and maze tasks. Eye tracking has been used to investigate what type of information is available during on-line processing and when it becomes available, but more research needs to be done in this area. There is evidence that suggests Control is processed differently across languages as well. This could have repercussions for universal theories of Control.
1.5 Our current research: Hypotheses and predictions
In this article, we present our most recent research on the processing of Control in Norwegian. We opted to use a grammatical-maze task (G-maze) as an alternative to a moving window self-paced reading task. This means that the participant reads each sentence word by word; however, the participant is presented with a choice between two different words as possible sentence continuations. The participant was asked to choose the grammatical alternative from each pair of alternatives in order to continue the sentence. One of the alternatives was obviously ungrammatical given the previous context. For a more detailed description of the experimental design, see the methods section. Methodologically, we wanted to test the maze design’s sensitivity to anaphoric dependencies and its ability to detect them via interference between mentioned, ungrammatical alternatives and correct alternatives. If the antecedent was not activated the decision would be easy. Therefore, it was important to establish a baseline using similar NPs that were not mentioned in the sentence.
The second aim of this experiment was also to make close comparisons between two sentence construction types. We investigated non-finite Control clauses and the position of antecedent reactivation during on-line processing. We also investigated what we call their pronoun counterparts, containing a finite complement clause and an overt pronoun instead of PRO. These sentence types can be matched down to a minimal distinction between an infinitive marker and a complementizer prior to the first test position. An example of one of these comparisons is included in Example 1.5. Example 1.5 is a Subject Control sentence and (6-b) is its pronoun counterpart.

We predict that if there is an interference effect for either condition or test position, we should expect slower reaction times in comparison to an unrelated baseline. We have two test positions for each sentence, but only one of these contains a referent-dependent item. We predict that an effect will occur when we have competition with an antecedent (see Section 2.3). This can be expected based on the G-maze design.
If there is immediate reactivation of the grammatically correct antecedent of PRO and pronoun, as proposed by the Trace Reactivation Hypothesis (See Nicol & Swinney, Reference Nicol and Swinney1989; Sekerina, Reference Sekerina, Laurinavichyute and Dragoy2019), we should expect interference effects and longer reaction times for only the correct antecedent of PRO in competition with the infinitive marker. We should also see interference effects and longer reaction times for the correct antecedent of pronouns in competition with the pronoun in the complement clause. If the coreference processing of PRO and pronouns in Norwegian patterns similarly to English, interference effects and longer reaction times should be recorded for all potential antecedents in both Control and Pronoun conditions compared to an unrelated baseline (Nicol & Swinney, Reference Nicol and Swinney1989). Differences in interference effects and reaction time length across test positions for Control and Pronoun conditions should be obtained if PRO and pronouns undergo antecedent assignment differently.
2. Methods
The selection of the G-maze design was motivated by our previous work on Control (Larsen & Johansson, Reference Larsen and Johansson2020). Since our results using a priming design showed that antecedent reactivation was facilitated, we wanted to explore the possibility that the dependencies involved in coreference assignment could undergo interference, inhibiting reactivation, if the antecedent was activated in competition with the correct continuation (for example the infinitive marker). If there is no relation the choice should be easy, but if there is a pre-activated word it will be harder to ignore it and choose the correct continuation. This G-maze design forces the participant into an incremental processing mode in which all information must be processed before moving on to the next word in the sentence (Freedman & Forster, Reference Freedman and Forster1985; Forster et al., Reference Forster, Guerrera and Elliot2009). We recognized that this method can be used to investigate coreference processing. It enables us to more accurately analyze the timeline of antecedent (re)activation and assignment during on-line processing. Due to the task demands, we can assume that all context up to the test position(s) has been processed if the participant can make the correct choices (Witzel & Witzel, Reference Witzel and Witzel2016). This is not always possible with other self-paced reading designs.
2.1 Participants
A total of 56 participants voluntarily took part in the experiment and signed consent forms prior to the start of the experiment. The consent forms were not connected in any way to the data collected from the experiment. This was done in order to maintain anonymity. An experimenter was present outside of the testing room at all times so that the participants were able to ask questions before and after the experiment. Participants were also given notice that they had the right to leave the room and end their participation in the experiment at any time for any reason.
All the participants were native speakers of Norwegian and residents of the city of Bergen in Norway. Participants received a movie ticket as compensation for their participation. Table 1 shows the self-reported statistics concerning gender, age, education, and written language preference of the participants. The selected preference did not affect the language of the experiment (Norwegian - bokmål), but it was included as a factor in the data analysis.
Table 1. The 56 participants described by gender, age, education, and written language preference. NA means that the participant(s) declined to give an answer

2.2 Experimental conditions
The design of the experiment contained four test sentence constructions: Object Control (OC) and Subject Control (SC) sentences and a pronoun counterpart of each Control type (Object pronoun (OPN) and Subject pronoun (SPN)). We used three test sentences of each type for a total of 12 test sentences. Each test sentence was presented in six different conditions. They were then repeated twice in each condition with the correct sentence continuation appearing once as the top selection and once as the bottom, making in total 144 unique test presentations (12*6*2). There were three levels of type of activation in relation to PRO (or pronoun): mentioned, intended (correct antecedent), and unrelated. Each of these sentence conditions were presented four times. Two independent presentations showed the correct answer either on the top or on the bottom. This was done for both positions.
There were also 12 unrelated filler sentences, which were presented once each. The participants had to make a decision on every word, so adding more fillers would have made the experiment much longer. This leads to increased fatigue, while not providing any more data. The main goal was to reduce the impact of the marked constructions, which were assumed to be the Control sentences. The Control and pronoun sentences were also considered different constructions. We assumed one would not facilitate the other.
In addition to the filler sentences, each participant was presented with 6 training sentences at the beginning of the experiment in order to get them familiar and comfortable with the task. A total of 162 sentence presentations were shown to each participant, with 144 of those being test conditions. For a full list of the test, filler, and training sentences used, see Appendix A, B, and C.
We used a repeated measures design, where the participants were their own controls. This allows for a more precise estimate of individual variance for each of the conditions. It permits the use of a smaller number of participants since more data can be obtained from each individual. Reaction time studies are often planned as factorial designs where the time of presentation or presentation order are considered handled by randomization (Stowe & Kaan, Reference Stowe and Kaan2006). The idea is that since conditions are randomly distributed across the presentation order, the main effect is not affected; however, this disregards the effect on the variance.
Baayen & Milin (Reference Harald and Milin2010) state that the inclusion of control predictors in the model “not only helps satisfy to a better extent the independence assumption of the linear model, but also contributes to a more precise model with a smaller residual error. Simply stated, these predictors allow a more precise estimation of the contributions of the other, theoretically more interesting, predictors.” There is no reason that the first presentations would be more accurate for the task at hand. Rather, on the contrary, the participants are initially less confident in their decisions (as mirrored in the slower reaction times). The solution to include more participants rather than presenting more items would thus not necessarily mean more accurate measurements of the phenomenon of interest
Even so, the learning effect is rarely handled using the statistical model. Baayen & Milin (Reference Harald and Milin2010) is an exception, and we have not seen it used previously for studies of linguistic coreference. This could be because some researchers may hesitate to add more factors for fear of making it harder for the model to converge since more parameters have to be estimated. Nonetheless, additional variables, such as those that control the effect of learning, often make it easier for the model to converge. Variables that control effects allow the model to account for more of the variance.
To account for the possible influence of a learning effect, we included the order of individual word presentation as a factor in our statistical analysis. Including the order of word presentation is an effective way to account for individual variance, across the entire experiment as well as the sentence stimuli. Additionally, this allows all conditions to be presented to each participant since we do not rely only on the randomization of sentence stimuli.
When constructing the sentence stimuli, we had to consider the role that the distance between a context-dependent item (pronoun, PRO, or trace) and its antecedent can play in regards to storage and computational demands. Previous studies have shown that the shorter the distance, the more readily available the antecedent is in working memory (Garrod & Sanford, Reference Garrod and Sanford1977; Clark & Sengul, Reference Clark and Sengul1979; Ehrlich, Reference Ehrlich1980; Ehrlich & Rayner, Reference Ehrlich and Rayner1983; Blanchard, Reference Blanchard1987). For example, evidence has been found that object relatives are more difficult to process than subject relatives (e.g. Holmes, Reference Holmes1973; Wanner & Maratsos, Reference Wanner, Maratsos, Halle and Miller1978; King & Just, Reference King and Just1991). One possibility proposed by these studies is that this increase in difficulty is due to the predictions in object relatives being maintained across a greater linear distance in comparison to subject relatives in which the gap predictions are satisfied immediately. Others have also suggested that the distance between predictions and their fulfillment leads to greater storage demands and, ultimately, greater processing difficulty (Kaan & Stowe, Reference Kaan and Stowe2002). With this in mind, we used modifying clauses throughout our test sentence stimuli in order to maintain a consistent linear distance between the PRO NP antecedent creating these predictions and PRO itself, where the predictions should be satisfied. This does not change the hierarchical distance between the two items, but it does provide the parser with additional units to process before encountering PRO in Object Control constructions.
Each of the 12 test sentences had three ungrammatical alternative templates. The top three conditions in Table 2 provide three examples of these templates. They were used twice in the six conditions so that the ungrammatical choices did not become obvious to the participants over time. The sentence-initial ungrammatical alternative was always the infinitive form of a verb. The correct and incorrect alternatives were presented equally as top and bottom choices across the experiment, but we show the correct choices on top in these examples so that it is easier to distinguish between the two.
Table 2. “The kind monkey offers [the elephant] to carry [the bag] home.” An example of a Subject Control sentence ((7-a)) appearing in the six different experimental conditions. The critical words in each condition are highlighted. The top three conditions show examples of ungrammatical alternatives. ’***’ is used to represent the ungrammatical alternatives in the other conditions. The predicted points of interference are highlighted
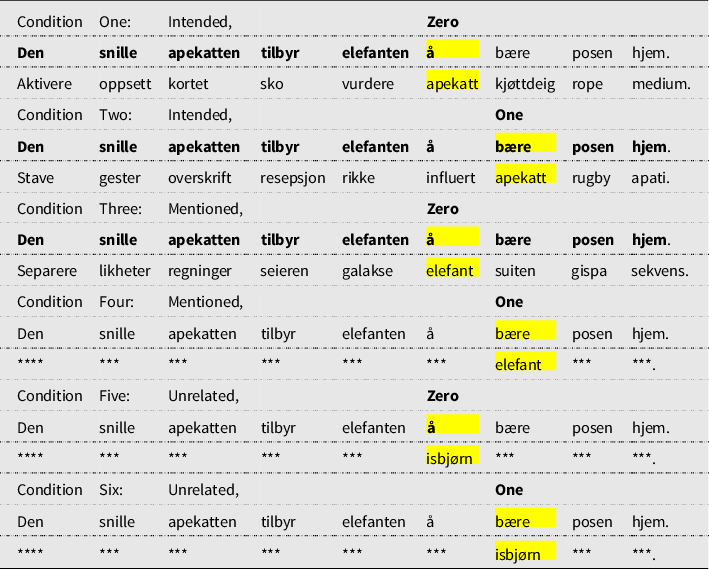
Example 2.2 provides a Subject Control sentence from the study. Table 2 shows this sentence in each of the six conditions (three levels of activation and two levels of position). A similar table is also included for Example 2.2, a Subject Pronoun sentence from the study (Table 3). A line of three asterisks is used to represent an ungrammatical alternative. It should be obvious to native speakers of Norwegian that the root form of a noun is ungrammatical at all test positions, even though the definite form of a noun could be grammatical in the pronoun conditions in position one.

Table 3. “The fast leopard offers [the elephant] that he pay for [the taxi].” An example of a Subject Pronoun sentence appearing in the six different experimental conditions. The predicted points of interference are highlighted. ’***’ is used to represent the ungrammatical alternatives
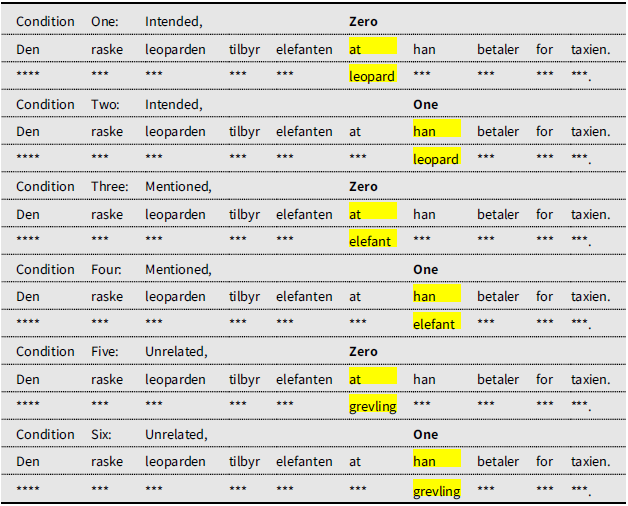
Another factor that was controlled for during the design phase was NP animacy features since they have been found to influence antecedent assignment (Bickel et al. Reference Bickel, Witzlack-Makarevich, Choudhary, Schlesewsky and Bornkessel-Schlesewsky2015a; Bickel et al. Reference Bickel, Witzlack-Makarevich, Zakharko, Bornkessel-Schlesewsky, Malchukov and Richards2015b; Bornkessel-Schlesewsky & Schlesewsky, Reference Bornkessel-Schlesewsky and Schlesewsky2009; Dahl & Fraurud, Reference Dahl, Fraurud, Fretheim and Gundel1996; Larsen & Johansson, Reference Larsen and Johansson2007, Reference Larsen, Johansson, Jordan Zlatev, Johansson Falck and Lundmark2009; Primus, Reference Primus, Ina Bornkessel, Comrie and Friederici2006, a.o.). The sentences were designed so that each one contained two potential NP antecedents. Considering the fact that animacy can affect coreference resolution in a variety of ways, our study was purposefully designed so that animacy was not a factor. All potential NP antecedents were animate and non-local, exotic animals. We used uncommon animal NPs that the participants presumably did not have daily interactions with so that they would not be able to use familiarity, world knowledge, or episodic memory to aid their decisions. The antecedents were matched for number of syllables and length. There were six potential antecedent NPs and three unrelated NPs used in the study. All pronouns were “han“(he), and all the animals had no obvious gender. This strategy for NP selection prevented gender and semantic associations from creating participant biases.
Finally, anthropomorphized stories are easy to process and often used in research on children. We assumed that adults would have no problem interpreting the sentences, and none of our participants expressed any such concerns in debriefings.
2.3 Predicting relevant positions: Zero and One
Our experimental design investigates the position in which inference effects occur during coreference processing. Based on the theoretical discussions concerning the position of the infinitive marker in Norwegian Control constructions, we selected two test positions. We also considered the possibility that the parser needs information from the subordinate clause verb prior to beginning the process of antecedent selection. For an illustration of these test positions, see Tables 2 and 3.
For PRO:
-
1. Position Zero – in competition with the infinitive marker.
-
2. Position One – in competition with the subordinate clause verb.
For pronoun counterparts:
-
1. Position Zero – in competition with the complementizer.
-
2. Position One – in competition with the pronoun of the finite clause.
2.4 Procedure
Participants were asked to sit in a sound-proof recording studio and use a computer to take part in the experiment. The experiment lasted for approximately 15 minutes, depending on the participant. Participant decisions were recorded using a Cedrus RB-540 Response Pad. The participant was asked to begin by reading the instructions on the screen. The first part of the experiment involved four short questions regarding the participant’s gender, age, level of education, and written language preference. The participant could choose to either answer the questions or to not respond.
The second part of the experiment began with an additional set of instructions. The participant was told that they would be asked a couple of comprehension questions at the end of the experiment. This ensured their attention would be held throughout the duration of the task. We asked the participant to read the sentences presented on the screen word by word. Each time, they had a choice between a grammatical or ungrammatical continuation. The participant was asked to choose the correct grammatical continuation of the sentence. The possible sentence continuations were presented with a top and a bottom alternative such that the participant could press the marked top or bottom button to select the correct continuation. The screen position of the alternatives was balanced with an equal number of correct top and bottom alternatives.
The sentences were displayed linearly across the computer screen. We first presented the participant with a series of training sentences. Participants were not informed that the first six sentence presentations were for training purposes. If the participant selected the incorrect answer, they were shown the word Feil (Wrong) on the screen and the sentence began again from the beginning.
After going through the training sentences, the experiment proceeded immediately to the presentation of test and filler sentences. There was no feedback after the training sentences. The participant was presented with a set of two asterisks at the beginning of each sentence in order to orient themselves and direct their attention to the appropriate point on the screen.
3 Results
3.1 Outlier analysis
The analysis was completed in R (R Core Team, 2021). The results were calculated using data from 55 of the 56 original participants. The overall data showed a high level of task compliance; however, one participant (P21) showed significantly more errors than the others, with only 86.2% (462/536) correct. This is illustrated in an association plot in Figure 2 that was created using the vcd package in R (Meyer et al., Reference Meyer, Zeileis and Hornik2006; Zeileis et al., Reference Zeileis, Meyer and Hornik2007; Meyer et al., Reference Meyer, Zeileis and Hornik2021). Therefore, we chose to exclude all data recorded for this participant from the data analysis, since this participant may have solved the task differently.

Figure 2. Error analysis per participant. Participant P21 has a significantly higher error rate.
Our data contained a few values for RT that were significantly longer than the average. To prevent extreme outliers from driving effects in the data, we set upper and lower RT boundaries based on the findings of a comparative study on RT outlier exclusion methods. Berger & Kiefer (Reference Berger and Kiefer2021) found that methods based on standard deviations (SDs) and z-scores showed small (absolute) biases, few Type-I errors, and excluded only small proportions of RTs. Therefore, the upper boundary was set at 1928ms, which was the mean of RT plus 2 SDs. The lower boundary could not be a negative value, so it could not be set based on SDs.
We still needed to account for the time it took for a participant to encode and react, so the lower boundary was set at 200ms (Ashby & Townsend, Reference Ashby, Gregory and Townsend1980; Luce, Reference Luce1991; Whelan, Reference Whelan2008). These boundaries kept 96% of the data and about 139 out of 144 data points per participant.
3.2 Overall effects for all sentence types and test positions
Figure 3 provides an illustration of the changes in mean reaction time across sentence position. Figure 4, created using the ggplot2 (Wickham, Reference Wickham2016), dplyr (Wickham et al., Reference Wickham, François, Henry and Müller2021), and tidyr (Wickham, Reference Wickham2021) packages in R, focuses on the mean reaction time from two words before the infinitive marker/complementizer up until 2 words after. For both Figure 3 and 4, the x-axis represents sentential positions, in words, relative to the infinitive marker or the complementizer (position 0). For test position zero, we expect interference at position 0, and for test position one, we expect it at position 1. Interference can be observed as a spike in slower reaction times.
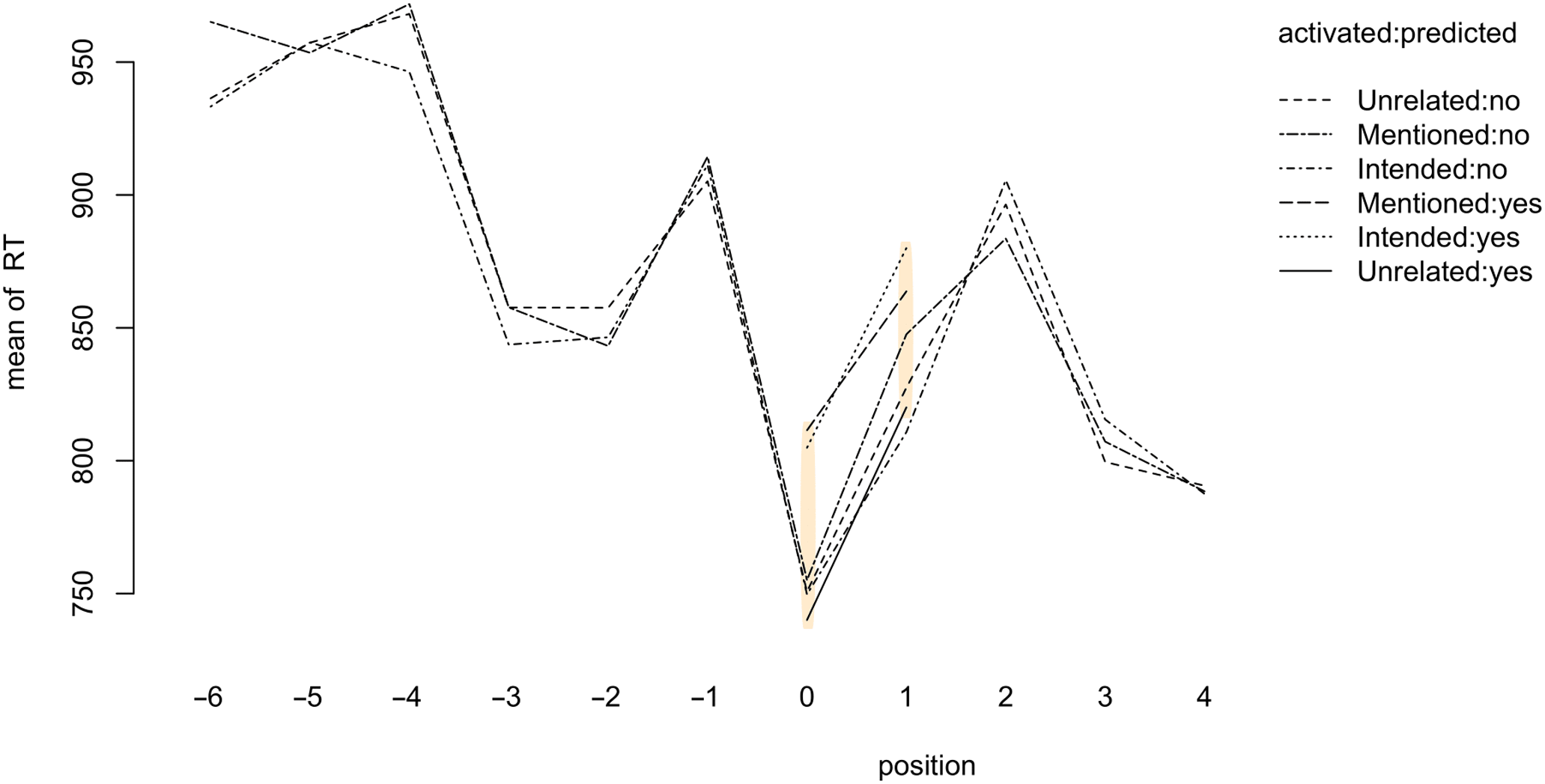
Figure 3. Interaction Plot showing the mean RT for the levels of activated and predicted across position. The shaded areas mark the difference between the levels of activated in the test positions.

Figure 4. The mean RT for each sentence type for each level of activated. A vertical dotted line marks the test positions. The position being tested and whether or not an effect is predicted is displayed in the legend. Interference effects are noted as a positive difference between unrelated and the other two levels of activated, as indicated by the shaded regions.
The y-axis shows the mean reaction time. The overall processing of the sentences shows that potential antecedents (Mentioned and Intended) stand out, creating a visible interference effect (Figure 3) that we will analyze in more detail. The typical sentence processing signatures are present with higher reaction times for the first (unpredictable) item of a sentence or clause (position -6 or -5, depending on sentence length). The contrast between unrelated and potential antecedents is highlighted by a shading in the graph. The two lines that stand out at position 0 and 1 are the lines for potential antecedents (mentioned or intended). This provides additional evidence that the experimental design is capable of capturing the intended interference effects at our test positions.
Figure 4 gives the mean RT of the levels of activated and the levels of type across sentence positions, after honing in on the immediate context. It shows interference effects as peaks at either position 1 (see x-axis) if the test position is one or position 0 if the test position is zero. No effects were predicted at any positions other than 0 and 1. Shaded ovals are used to highlight the differences between when an effect was predicted or not in one of the test positions. The most important differences lie in the comparison of mentioned and intended to the unrelated baseline condition. The mean reaction time for SC and OC when the test position was zero is much larger than that for unrelated. The same trend occurs for SPN and OPN but in test position one.
To get an idea of which factors and conditions should be looked at more in depth, we ran an Analysis of Variance (ANOVA) on a linear mixed effects model. This was done using the lmerTest package in R (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017).
The following factors were included in our initial model:
-
Predicted (yes, no)
-
– Presentations in which the position 0 or 1 was indeed the test position and an interference effect was predicted. Both positions occur in all sentence presentations, but they cannot both be the test position in the same presentation.
-
-
Type (Object Control, Subject Control, Object Pronoun, and Subject Pronoun)
-
Activated (intended, mentioned, unrelated)
-
Position (0/zero, 1/one)
-
Order
-
– This represents the unique order of presentation for all the items for each participant.
-
-
Language (Bokmål, Nynorsk, NA)
-
Gender (Man, Woman, NA)
-
Education (High School, Bachelors, Masters, NA)
-
Age (18-25, 26-35, 36-45, 46+)
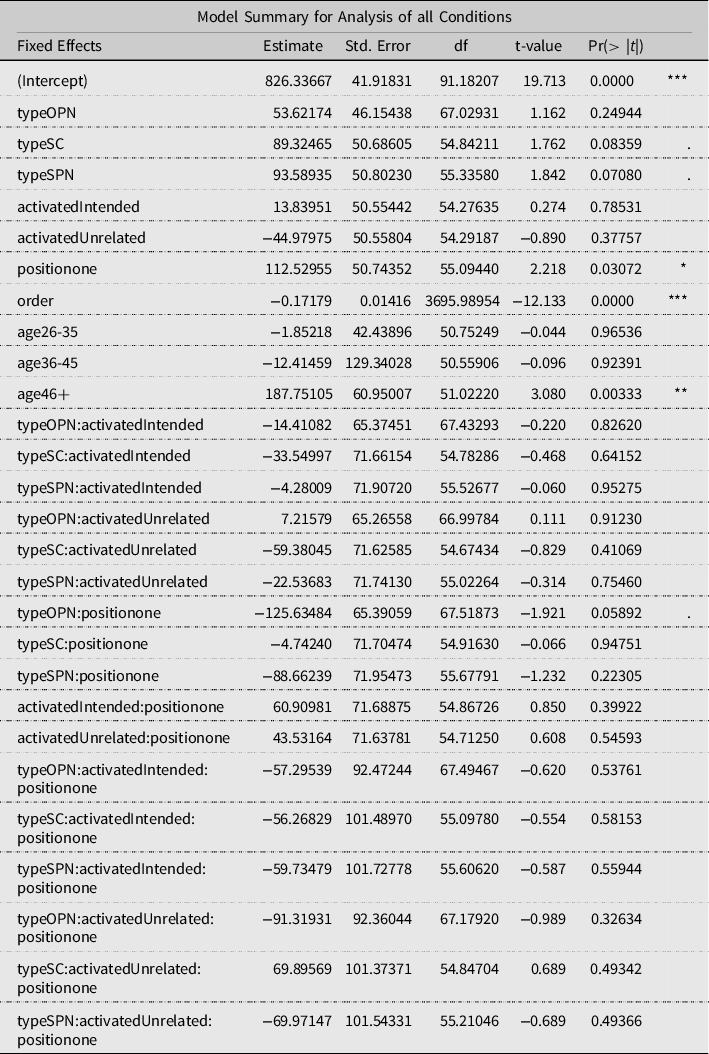
Participant and item (each individual word) were included as random effects with a random intercept. The items were encoded so that each item was unique per condition, in total 144 items. Recall that the participant is supposed to choose the non-antecedent, so the item is the (unique) combination of the two choices in that situation. Therefore, there was no possibility to add slopes, as we do not have repetitions for these items. Gender, Education, and Language did not show any significant effects. Thus we removed them from our model. The complete ANOVA table (Table 11) and summary for the model (Table 10) are shown in Appendix D. The mixed effects model formula used to obtain the variance for the ANOVA is lmer(RT predicted * type * activated * position + order + age + (1 | participant) + (1 | item)). The factors age and order are used to regress out the effect of age and presentation order on the reaction times. The main factors are: predicted (yes, no), type (OC, SC, OPN, SPN), activated (mentioned, intended, unrelated), position (0/zero, 1/one). For activated, it is possible to think of mentioned and intended as potential antecedents and unrelated as a non-antecedent.
Table 11 shows significant effects for predicted, type, activated, position, order, and age. There are significant interaction effects between predicted and activated, and between type and position. Since the ANOVA shows a highly significant effect (p = 0.0008) of predicted, we concluded that our design is effective in provoking effects in the selected test positions. We then focused on the yes level of predicted.
Our final model was made using this formula: lmer(RT type * activated * position + order + age + (1 | participant) + (1 | item)). The significant factors remain the same as in our previous model; however, removing predicted as a factor allows the model to better calculate the effect of activated since there is no longer an interaction effect involved. These effects will be discussed in detail in the following subsections. Estimated Marginal Means (EMMs) from the emmeans package in R (Lenth, Reference Lenth2021) will be used as post-hoc results for the factors with more than two levels. This post-hoc function uses the variance estimated by the mixed effects model.
3.3 Activated
The significant effect for activated shows an observed difference between the unrelated, mentioned, and intended levels (p = 0.0009). Table 5 includes the EMMs for our post-hoc investigation within the factor activated. The unrelated level is 62.89ms faster than the intended (p = 0.0054) and 53.34ms faster than the mentioned (p = 0.0007). These differences do not take into account other experimental factors though.
Table 4. Type III ANOVA table for the final model. Degrees of freedom within conditions (
 $d{f_W}$
) are estimated using Satterthwaite’s method
$d{f_W}$
) are estimated using Satterthwaite’s method
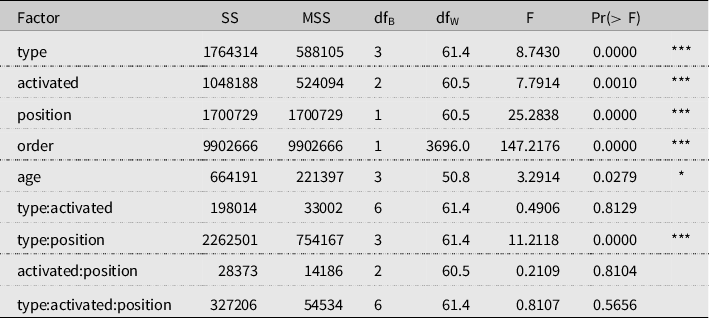
Table 5. Pairwise model comparisons for the levels of activated

3.4 Type
There is a significant difference between the sentence types (p = 0.0000). Both types assigning the object as the correct antecedent are faster than their subject-assigning counterparts. EMMs were calculated as a poc-hoc test to determine where the significant differences lie within the levels of the factor type. Table 6 presents the results. There is a significant difference between OC and SC (p = 0.0253), OPN and SC (p < 0.0001), and OPN and SPN (p = 0.0190). The main contrast is between types that assign the subject as the antecedent and those that assign object as the antecedent. The interaction between type and position will affect these relationships as well.
Table 6. Pairwise model comparisons between types of sentences

3.5 Position
A significant effect of position (p = 0.0000) was detected. Participants made quicker decisions in position zero (826.34ms) in comparison to position one (938.87ms). This is likely because starting a new clause causes an increase in cognitive load at the first content word. Since position has a significant interaction effect with type, this relationship between position zero and one may be related to a larger interference effect.
3.6 Interaction of type and position
The factors of type and position are significant main effects. There is also a significant interaction between the two (p = 0.0000, Figure 5). Table 7 lists the results of the post-hoc EMMs for the differences between all combinations of type and position. The important comparisons to consider are those between the levels of type for the same level of position and those between the levels of position for the same level of type.

Figure 5. The model prediction of difference in estimated marginal means of RT per sentence type and position. Position one for SC and OC involves competition with a verb.
Table 7. Pairwise model comparisons of type and position. The interesting comparisons are highlighted

In position one, OC is 123.95ms slower than its pronoun counterpart (p < 0.0001) and SC is 105.40ms slower than its pronoun counterpart (p = 0.0080). There are no significant differences between any of the sentence types at position zero. SC is 147.14ms slower at position one than it is at position zero (p < 0.0001). Similarly, OC is 147.34ms slower at position one than zero (p < 0.0001). SPN and OPN show no significant difference in reaction time between test positions.
Figure 5 illustrates the interaction between type and position. The two lines for SPN and OPN show no significant differences between the levels of position. Both SC and OC are represented with lines that have comparable slopes, which is confirmed by the EMMs.
3.7 Order: The learning effect
Order of presentation showed a significant effect in our model (p = 0.0000). With each sentence presentation, the participant’s decision time was on average 0.17ms faster. This seems like a small effect, but it adds up and is highly significant. The learning effect due to order of presentation is plotted in Figure 6.

Figure 6. The mean RT for the learning effect for each sentence type over the time course of the experiment. Ellipses of uncertainty are included as shaded areas in the graph.
The graph shows a similar negative slope for all sentence types as the experiment progresses; it is just the starting point that is different. Including the presentation order as a factor in the model allows us to regress out the unavoidable learning effect that takes place when a participant is presented with the same, and very similar, stimulus in various conditions. Note that the order of presentation was randomized so that each test item is presented in a different order for each participant.
The participants become more confident in their decisions, resulting in faster reaction times. Regressing out such “learning effects” makes it possible to better account for variance in the main contrasts. The repeated measures design makes it possible to collect data for all conditions from each participant, permitting us to better account for variance due to individual participants. Individual differences related to our conditions are thus accounted for by repeated measures and explicitly regressing out the expected learning effect. Detrending is often necessary in longer experiments, and randomization of items is not enough since the participants change their behavior as they gain experience.
3.8 Age
Age significantly contributed to the RT of participants (p = 0.0279). The group of participants who were 46 years of age or older were 187.75ms slower than the youngest age group (18-25) and 189.6ms slower than the 26-35 age group. These significant differences (p = 0.0111 and p = 0.0274) are apparent in the EMMs in Table 8 as well. We chose to regress out this effect of age rather than remove the few older participants.
Table 8. Pairwise model comparisons between age groups

3.9 Control
Since no difference between mentioned and intended antecedents was found in the EMMs of our overall model, we chose to combine the mentioned and intended levels of activated to take a closer look at the levels of Control. The data set was subsetted such that only SC and OC remained for sentence types. We ran a linear mixed effects model with the same formula as our main model. Like in the results from the main model, the ANOVA reported a significant effect of type, order, and position. Activated trends towards significance (p = 0.0502). Both types of Control presented with slower reaction times in position one in comparison to position zero (p ≤ 0.0001), which is an additional effect after the main effects are accounted for. From the EMMs, we found a trend towards significance for activated, but this was only evident for the difference between the potential antecedents and the unrelated NP in position zero (p = 0.0728).
3.10 Pronoun
To investigate the levels of the pronoun constructions, we combined the mentioned and intended levels of activated and subsetted the data set such that only SPN and OPN remained for sentence types. The same formula as our main model was used to create a new linear mixed effects model. The ANOVA results confirmed the overall significant effect for type, activated, order, and age. Unlike the Control conditions, the Pronoun conditions show no effect of position and a significant effect of activated (p = 0.0007). There is a significant difference between potential antecedents and the unrelated NP in position one only (0.0104). We only see a significant difference between levels of activated for SPN (p = 0.0458). This difference in activated trends towards significance for OPN (p = 0.0726).
4 Discussion
A significant main effect of position was detected. Position zero marks the start of a new clause, but the grammatically correct option is a high-frequency function word. Therefore, the large, general difference in RT across positions is likely due to the grammatically correct option in position one being a less frequent content word (Schmauder et al., Reference Schmauder, Morris and Poynor2000).
There is a significant main effect of predicted, which tells us the predicted test positions were effective. There is a significant main effect of activated, both potential antecedents are significantly slower compared to the unrelated NP. There is also a main effect of sentence type, which tells us (after looking at specific effects) that sentences involving subject antecedents (SC and to some extent SPN) are slower, indicating greater interference than sentences involving object antecedents. Finally, we found a significant main effect of activated, but we detected no difference between the two levels of potential antecedents (mentioned and intended). This indicates that both are activated to some extent, which is in line with previous research but in conflict with accounts that hypothesize immediate reactivation of only the correct antecedent of a referent-dependent item. The results are consonant with a dynamic model of language processing, where antecedents are activated based on probabilities estimated by the available context. Antecedents may not always be activated and can potentially always be activated to some degree.
There is one significant interaction effect in the final model, between type and position. This effect tells us that Control sentences and their pronoun counterparts have different effects related to position, so PRO and pronouns may use different processing strategies. When we restricted the data set to only data points obtained when an effect was predicted (and tested for), we found support for a difference between the sentence types.
4.1 Control sentences
For Control sentences, we found an additional slowdown in position one relative to position zero for both Object and Subject Control, but there was only a trend towards significance for a main effect of activated in position zero. Therefore, the difference between the potential antecedents (intended and mentioned together) and the unrelated NP is a rather weak effect. One possible explanation (or complication) is that the unrelated were similar animals that might be partly activated due to their semantic similarity to the potential antecedents (i.e., they are all names of exotic animals). A stronger contrast might provide a clearer difference between potential antecedents and non-antecedents. This would suggest a (lexical) semantic, or spreading activation, account.
The pattern of interference effects recorded for Control sentences can be interpreted as supporting Nicol & Swinney (Reference Nicol and Swinney1989)’s results. Nicol and Swinney reported processing effects for all potential antecedents in Control conditions. We found a trend towards interference effects for both potential antecedents in competition with the infinitive marker. These results conflict with the Trace Reactivation Hypothesis which presumes immediate reactivation of only the correct antecedent of PRO. This suggests that the parser lacks the complete information needed to assign the correct antecedent at the time that PRO is processed. The reactivation of two potential antecedents allows both to be stored in short-term memory for later use. This is also observed for the pronoun counterparts, as both mentioned and intended are associated with interference effects relative to unrelated.
Our results suggest that the antecedent selection process has already begun at the infinitive marker. We cannot claim to know when this selection has been finalized, but we can predict the start of this process by combining our current results with those from previous research on Control in Norwegian. Using a priming paradigm, we observed similar activation patterns for potential PRO antecedents (Larsen & Johansson, Reference Larsen and Johansson2020). Both potential antecedents of PRO showed a facilitation effect directly after the presentation of the infinitive marker. There was no facilitation directly before the infinitive marker. Since no processing effects have been found before the infinitive marker or at subordinate clause verb, we can assume that antecedent selection begins following the processing of the infinitive marker. This suggests that the Norwegian infinitive marker allows for early activation.
The difference that was recorded between the potential antecedents and the unrelated NP was not as strong as it was for the pronoun condition. It is possible that PRO is less susceptible to interference effects in comparison to pronouns. Another reason for this could be that the syntactic and semantic constraints on PRO are not as absolute as those for pronouns. Pronouns can be matched for grammatical gender and other such features, unlike PRO. That would suggest discourse and sentence context play a greater role in PRO antecedent assignment.
4.2 Pronoun sentences
The pronoun sentences did not exhibit a significant main effect of position, but we saw a difference between potential antecedents and unrelated NPs specifically in position one, in competition with the pronoun itself. This is in line with results recorded for English pronouns: all structurally appropriate antecedents were reactivated simultaneously in a similar manner at the position of the pronoun (Corbett & Chang, Reference Corbett and Chang1983; Nicol, Reference Nicol1988; Nicol & Swinney, Reference Nicol and Swinney1989; MacDonald & MacWhinney, Reference MacDonald and MacWhinney1990; Nicol & Swinney, Reference Nicol, Swinney and Barss2002, a.o.). Our results imply that a similar reactivation pattern takes place in Norwegian.
The pronoun sentences show a similar pattern of antecedent reactivation to the Control sentences in that all potential antecedents are reactivated; however, we see that these effects occur in two different sentence positions. This reinforces previous research on English that found that PRO and pronouns undergo antecedent resolution at different points during sentence processing (Nicol & Swinney, Reference Nicol and Swinney1989). One possible explanation is that the parser has enough information to predict the occurrence of PRO after encountering the infinitive marker in Norwegian but that it does not have enough information to predict the occurrence of a pronoun after encountering the complementizer at. This could also be a potential explanation for why pronoun antecedent reactivation patterns similarly to English, but PRO antecedent reactivation does not, as English does not have a distinctly unique infinitive marker.
4.3 Summary
The results show that our experimental design functioned as expected based on previous G-maze research and was capable of detecting interference effects in the selected test positions. Sentence types that assign the matrix clause subject as the antecedent differ significantly from their object-assigning counterparts. Test position zero is always faster than position one, and there is a significant interaction effect between position and type. The possibility to control variance from presentation effects (learning effects) is demonstrated by using the order of individual word presentation as a model factor rather than trial number (cf. Baayen & Milin, Reference Harald and Milin2010).
Considering the detected differences, our results support the presence of an interference effect for Control and pronoun conditions. We were able to detect these effects using written stimuli, disproving the suggestion that effects would only be found for auditory stimuli (Nicol & Swinney, Reference Nicol, Swinney and Barss2002). Both the Control and pronoun sentences recorded no significant difference between the intended antecedent and the mentioned NP, so antecedent resolution is not complete at the test positions in this study, which opposes the predictions of the Trace Reactivation Hypothesis. We find no indication of a preference for the most recent antecedent as has been found previously for Japanese and nominal Control in English (Witzel & Witzel, Reference Witzel and Witzel2016; Kwon & Sturt, Reference Kwon and Sturt2016). These results suggest that coreference processing for Control and pronouns in Norwegian patterns similarly to English in that all potential antecedents show signs of processing differences compared to NPs that are not potential antecedents. If this similarity to English also extends to NP traces in that traces cause immediate reactivation of only their antecedent, then we can exclude a trace account of PRO.
In addition to a difference between Control and Pronoun sentences, our results reflect the results from our previous study that used a priming paradigm to investigate Control and Raising (Larsen & Johansson, Reference Larsen and Johansson2020). The priming study revealed a priming effect for both potential PRO antecedents following the presentation of the infinitive marker in Subject Control sentences. The current study replicated a trend of this effect directly succeeding the presentation of and in competition with the infinitive marker. We found the predicted interference effect at the predicted position. We also detected a trend towards significance for activated for Object Control, which did not reach significance in the priming study.
5. Conclusion
Throughout this article we have discussed coreference processing in relation to Control sentences as well as their pronoun counterparts. The results demonstrate that antecedent reactivation effects can be observed using a G-maze design, similar to earlier (word-to-picture) priming and L-maze studies. We see a rise in reaction times at all test positions where interference was predicted, which supports the validity of the study.
Due to the prediction of interference rather than facilitation, G-maze studies complement the more commonly used priming studies. The combination of techniques demonstrates that we can predict the direction of reaction times by predicting either facilitation (priming) or interference (G-maze). G-maze can be used to test previous findings as an alternative to repeating a priming study.
Our results confirm the findings of our previous study, which found priming effects for both potential antecedents of PRO following the infinitive marker in Subject Control sentences in Norwegian. This study used a method that tested for interference, and thus slower reaction times rather than facilitation. Both sets of results point to PRO antecedent processing beginning directly following the appearance of the infinitive marker. This data might support the infinitive marker being positioned in C as a complementizer in Norwegian, as opposed to T like in other languages with similar Control surface structures, such as English. Our findings indicate that Norwegian may trigger antecedent activation earlier at the infinitive marker. This activated tense phrase (TP) could be marked for tense and an active PRO before seeing the subordinate clause verb. This predicts that the effects we associate with PRO will occur later in languages with more ambiguous markers for the start of an infinitive clause, such as Swedish. The Swedish infinitive marker (“att”) and complementizer (“att”) share a common written form.
In a similar manner to our priming study, which exposed a difference between the processing of PRO and NP traces in Raising constructions in Norwegian, the current G-maze study recorded a difference between the processing of PRO and pronouns in complement clauses in Norwegian. Though the sentence structures of these three constructions are extremely similar to the untrained eye, our experimental work has detected differences in priming and inhibitory effects during sentence processing. That there is a difference suggests that speakers process the constructions differently despite the superficial similarity up to the test position. This argues that there is an underlying difference, such as the early commitment to a non-finite clause by means of a clear infinitive marker.
This article has also introduced some improvements to the analysis of reaction time experiments, which may explain earlier difficulties in detecting effects of coreference processing. We found a way to regress out the effect of increasingly faster responses from participants that get increasingly confident and familiar with the task. We extended this to account for the effect of slower responses in our older participants, and thus were able to keep more participants and a slightly more representative sample of the population. These improvements led to an increased power to detect small differences since more of the variance could be accounted for.
Our impression is that the length of the study was appropriate to avoid fatigue, especially since each decision was fairly easy to make, which is evidenced by a low average error rate. The randomized order of the trials makes it unlikely that a training effect can explain any association between our controlled factors, but rather the participants get increasingly confident in their decisions resulting in faster reaction times. This effect was handled by the statistical model.
It is interesting that neither the present nor the previous study (Larsen & Johansson, Reference Larsen and Johansson2020) observed a significant difference between the mentioned NP and the intended antecedent for PRO. This suggests that the binding and eventual assignment, or selection, of the antecedent occurs at a later stage in sentence processing. In the Control constructions, the Control information supposedly provided by the matrix clause verb is not enough to assign immediate coreference upon encountering PRO. When is this information available, where does it come from, and can we exclude an trace account of PRO?
Future research may expand the range of languages for which coreference processing has been investigated and its relation to how clearly non-finite clauses are marked lexically and structurally. Swedish, which is similar to Norwegian, is one interesting case with an ambiguous infinitive/complementizer marker (“att”). Comparing data on the processing of referent-dependent items across languages may provide insights into the role of syntactic, semantic, and pragmatic dependencies and restrictions in coreference resolution, and at what point coreference is resolved for different types of sentence constructions. Since the data shows that both potential antecedents (mentioned and intended) are activated, there is a chance that contextual information will affect the selection of antecedents and affect the timing of selection. Branching out to other methods such as eye-tracking and the use of visual world paradigms could provide additional insight into the time course of coreference processing. In controlled experiments contextual, information could be provided that predicts only one potential antecedent at the relevant positions. Will both antecedents still be activated, with selection occurring at a later stage?
Acknowledgments
We are grateful for the feedback and suggestions from three anonymous reviewers that greatly improved the clarity and argumentation of our article. We would also like to thank Carl Börstell from the University of Bergen and Christine Howes from the University of Gothenburg for feedback on earlier drafts. Finally, we greatly appreciate the enthusiasm for our research that Marit Julien from Lund University showed prior to us writing this article.
Appendix
A. Test sentence templates
Subject Control
-
1. Den snille apekatten tilbyr elefanten å bære posen hjem.
The kind monkey offers the elephant to carry the bag home.
-
2. Den grønne krokodillen skylder sjiraffen å lage lunsj.
The green crocodile owes the giraffe to make lunch.
-
3. Den store neshornet lover krokodillen å spise alle grønnsakene sine.
The big rhinoceros promises the crocodile to eat all his vegetables.
Subject Pronoun
-
4. Den raske leoparden tilbyr elefanten at han betaler for taxien.
The fast leopard offers the elephant that he pays for the taxi.
-
5. Den høye sjiraffen skylder apekatten at han må ut søppelet.
The tall giraffe owes the monkey that he takes out the trash.
-
6. Den grå elefanten lover neshornet at han drikker tre liter vann hver dag.
The gray elephant promises the rhinoceros that he drinks three liter of water each day.
Object Control
-
7. Elefanten anbefaler krokodillen som er søvnig å meditere før sengetid.
The elephant recommends the crocodile who is sleepy to meditate before bedtime.
-
8. Apekatten tillater leoparden som er sulten å stjele en moden banan.
The monkey allows the leopard who is hungry to steal a banana.
-
9. Leoparden lærer neshornet som er uerfaren å finne mat i skogen.
The leopard teaches the rhinoceros who is inexperienced to find food in the forest.
Object Pronoun
-
10. Krokodillen anbefaler apekatten som lukter dårlig at han dusjer hver dag.
The crocodile recommends the monkey who smells bad that he shower every day.
-
11. Sjiraffen tillater leoparden som er rar at han har på seg to forskjellige sko.
The giraffe allows the leopard who is unconventional that he wears two different shoes.
-
12. Neshornet lærer sjiraffen som er usikker at han tenker for mye på hvordan han ser ut.
The rhinoceros teaches the giraffe who is self-conscious that he thinks too much about how he looks.
B. Filler sentences
-
1. Apekatten som er forelsket tenker på krokodillen når han ser en fin blomst.
The monkey who is in love thinks about the crocodile when he sees a pretty flower.
-
2. Elefanten som er bekymret ringer leoparden fem ganger i uken bare for å høre hvordan han har det.
The elephant who is worried calls the leopard five times a week just to hear how he is doing.
-
3. Elefanten treffer den vennlige apekatten på den store og flate steinen hver annen dag.
The elephant meets the friendly monkey at the big and flat stone every other day.
-
4. Leoparden som alltid står opp tidlig vekker apekatten med en gøy sang om egg og bacon.
The leopard who always wakes up early wakes the monkey with a fun song about eggs and bacon.
-
5. Leoparden synger bursdagssangen til den sjenerte sjiraffen hvert år i desember.
The leopard sings the birthday song to the shy giraffe every year in December.
-
6. Neshornet overnatter hos apekatten på fredag og de skal spille fotball sammen.
The rhinoceros is sleeping over at the monkey’s on Friday and they will play soccer together.
-
7. Neshornet leter etter elefanten, men han fant bare katten hans.
The rhinoceros is looking for the elephant, but he only found his cat.
-
8. Sjiraffen sender den kjekke krokodillen en pakke med godteri på Valentinsdagen.
The giraffe sends the handsome crocodile a pack of candy on Valentine’s Day.
-
9. Sjiraffen dusjer mye tidligere på dagen enn elefanten hver dag i uken.
The giraffe showers much earlier in the day than the elephant each day of the week.
-
10. Sjiraffen hjelper det trette neshornet med hans mattelekser fordi han klarer det ikke selv.
The giraffe helps the tired rhinoceros with his math homework because he cannot do it himself.
-
11. Krokodillen som er fattig føler seg trist fordi leoparden har mer penger enn ham.
The crocodile who is poor feels sad because the leopard has much more money than him.
-
12. Krokodillen gifter seg med neshornet, og de vil være sammen for resten av livet.
The crocodile marries the rhinoceros, and they will be together for the rest of their lives.
C. Training sentences
-
1. Apekatten arbeider sammen med det grinete neshornet på onsdager.
The monkey works together with the grumpy rhinoceros on Wednesdays.
-
2. Apekatten som allerede har en kjæreste, vet at sjiraffen fortalte alle om hans forelskelse.
The monkey who already has a significant other knows that the giraffe told everyone about his crush.
-
3. Elefanten som er omtenksom stemmer for at sjiraffen blir kongen av jungelen ved neste valg.
The elephant who is thoughtful votes for the giraffe to become the king of the jungle in the next election.
-
4. Leoparden forklarer til den unge krokodillen alt om hvordan han klatrer i trær.
The leopard explains to the young crocodile everything about how he climbs in trees.
-
5. Neshornet barberer leoparden gratis fordi de har vært venner siden de var små.
The rhinoceros shaves the leopard free of charge because they have been friends since they were little.
-
6. Krokodillen eter middag så fort at elefanten som også er sulten er redd for at han ikke får noe mat.
The crocodile eats dinner so quickly that the elephant who is also hungry is scared that he will not get any food.
D. Tables
Table A1. Estimated Model characteristics for Table 10

Table A2. Model summary for the analysis of all conditions. Predicted is included as a factor

Table A3. Type III ANOVA table for the final model. Degrees of freedom within conditions (
 $d{f_W}$
) are estimated using Satterthwaite’s method
$d{f_W}$
) are estimated using Satterthwaite’s method

Table A4. Estimated Model characteristics for Table 13
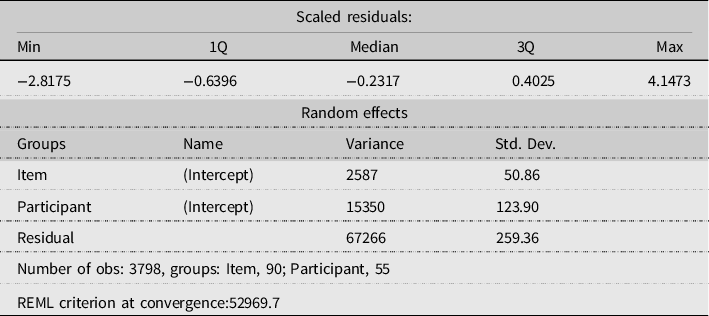
Table A5. Model summary for the analysis of all conditions. Predicted is excluded as a factor






















 Open access
Open access