



1. Introduction
People use numbers to label products and quantify almost everything, which makes them an indispensable part of our daily lives. As a uniquely human cultural achievement, symbolic number representations have shaped our technologically advanced culture and enabled economic development. Although the ability to use numbers is universal, the numerical formats we encounter and process every day vary according to the spoken language. A number can be perceived either in its visual Arabic digit format (e.g., ‘9’), or in visual or auditory verbal formats (e.g., 九/jiu3/in Mandarin, nine in English, neun in German, or དགུ་ in Tibetan). Do these variations in the physical format of the number affect how number information is processed? To examine whether or not number processing is independent of physical format, it is important to investigate the nature of number representation. The current study reports the results of two experiments in which we investigated conceptual and lexical representations of numbers across the different number notations used among Tibetan–Mandarin bilinguals. The representation similarity between number and language was stressed in the study to benefit the understanding of number processing from a linguistic perspective.
Bilingualism is defined as the regular and necessary use of two or more languages in everyday life (Grosjean, Reference Grosjean and Nicol2001). In addition to mastering multiple languages, bilinguals can also process number facts in at least more than one format than monolinguals (e.g., Arabic digits, Mandarin number words, and Tibetan number words in Tibetan–Mandarin bilinguals). The Tibetan–Mandarin bilinguals recruited in the current study had studied Mandarin since they were children. The language and textbooks they used to learn mathematics were all in Mandarin. Most importantly, they lived outside the Tibetan area and lived among Mandarin speakers for studying. Arabic digits and Mandarin numerals are seen on product labels, traffic signs, buildings, and many other everyday situations. These individuals are well-suited to address the representation of numbers in bilinguals because they have extensive experience processing numbers in the context of two or more languages. In particular, this allows for more fine-tuned tests regarding the effects of number format on number cognition.
Increasing scientific evidence points to the language sensitivity of bilinguals in arithmetic fact retrieval (Bernardo, Reference Bernardo2001). Language sensitivity refers to the effects of language format on different number tasks with bilinguals (Klein, Reference Klein2021). For instance, Campbell et al. (Reference Campbell, Kanz and Xue1999) found that the Chinese–English bilinguals responded faster when the number was presented in Mandarin symbols, and this effect was even greater when they responded in Mandarin. Bernardo (Reference Bernardo2001) proposed that the language used for learning and practicing arithmetic tasks matters in number processing. Klein (Reference Klein2021) concluded that the number concepts and the mental manipulation of quantities seemed to be language-dependent. Studies regarding children, bilinguals, and new language learners have also proposed that aspects of language play a role in the development of numerical representations (Dehaene et al., Reference Dehaene, Izard, Spelke and Pica2008; Gordon, Reference Gordon2004; Pica et al., Reference Pica, Lemer, Izard and Dehaene2004; Spaepen et al., Reference Spaepen, Coppola, Spelke, Carey and Goldin-Meadow2011). Thus, different numerals’ representations in bilinguals may be similar to the language representation for native languages (L1) and second languages (L2), providing an ideal test ground for investigating cognitive representations in the numerical domain from a linguistic view.
1.1. Language representation in bilinguals
In the past, psycholinguists have searched for features of language representation in bilinguals. In particular, they have sought to determine whether knowledge of the two languages is stored in two separate language-specific systems in the brain or whether it is integrated with a language-independent system (Chen & Ng, Reference Chen and Ng1989; Fischler, Reference Fischler1977; Groot et al., Reference Groot, Dannenburg and Vanhell1994; Groot & Nas, Reference Groot and Nas1991; Kirsner et al., Reference Kirsner, Smith, Lockhart, King and Jain1984; Kolers, Reference Kolers1963; Kroll & Stewart, Reference Kroll and Stewart1994; Meyer & Ruddy, Reference Meyer and Ruddy1974; Meyer & Schvaneveldt, Reference Meyer and Schvaneveldt1971; Potter et al., Reference Potter, So, Eckardt and Feldman1984; Scarborough et al., Reference Scarborough, Cortese and Scarborough1977). With respect to bilingual memory organization, two representational levels have been distinguished: A whole word is represented in a single node at the lexical level and its meaning in a single node at the conceptual level. Most studies have focused on these two representational levels of language. Comparing between-language effects with corresponding within-language effects has been a common approach in this field. Two of the most studied phenomena that affect language processing are the repetition-priming effect and the semantic priming effect. The repetition-priming effect (Scarborough et al., Reference Scarborough, Cortese and Scarborough1977) refers to a faster reaction time the second time a verbal stimulus is presented in a lexical decision task (true-words or pseudo-words) than the first time. In addition to occurring in a single language, the repetition-priming effect can also occur between languages; reactions to a word in L2 are faster when they are primed by a presentation of the same word in L1. This indicates that the two languages are directly connected at the lexical level of representation (Chen & Ng, Reference Chen and Ng1989; Kirsner et al., Reference Kirsner, Smith, Lockhart, King and Jain1984). Priming effects also exist at the semantic level. The semantic priming effect (Fischler, Reference Fischler1977; Meyer & Schvaneveldt, Reference Meyer and Schvaneveldt1971) states that a word is processed faster when it is preceded by a word to which it is semantically related. When applied to between-language situations, the presence of a semantic priming effect indicates that the two languages are integrated at the conceptual level.
Based on these phenomena, three models of bilingual representation have been proposed, each providing different implications for between-language effects. The Independent Representational Model proposed by Kolers (Reference Kolers1963) assumes separate systems of memory representation for each language. The Shared Representational Model (e.g., Kroll & Stewart, Reference Kroll and Stewart1994; Potter et al., Reference Potter, So, Eckardt and Feldman1984) proposes that bilinguals have a shared conceptual store for both languages as well as a separate store for each language. The Distributed Feature Model (Groot et al., Reference Groot, Dannenburg and Vanhell1994) predicts that cross-language representation at the conceptual level depends on the degree of overlap between translation equivalents.
As Campbell and Clark (Reference Campbell and Clark1988) suggested, the retrieval of arithmetic facts largely relies on the physical form of the number notation. For Tibetan–Mandarin bilinguals, Arabic digits and Tibetan numerals are studied first and used in everyday contexts. As their second language, Mandarin numerals are typically acquired later. Considering that these three number notations across two linguistic systems are different in physical form, from a linguistic perspective, two interesting questions arise: (1) Are the different number forms stored separately at the lexical level? (2) Is the meaning of different number notations shared at the conceptual level? The present study attempted to address these questions through a lexical decision task and a parity judgment task. Generally, to access the conceptual information of words, semantic judgment tasks are commonly used in the field of linguistics. However, the semantic judgment task usually makes participants decide whether the objects belong to living things or nonliving things (Becker et al., Reference Becker, Moscovitch, Behrmann and Joordens1997; Li et al., Reference Li, Mo, Wang and Luo2006; Zeelenberg & Pecher, Reference Zeelenberg and Pecher2003), which is inappropriate in the current study. Hence, given that previous studies have shown that parity judgment (e.g., odd or even) requires access to conceptual information (Dehaene et al., Reference Dehaene, Bossini and Giraux1993; Fias et al., Reference Fias, Brysbaert, Geypens and d’Ydewalle1996, Reference Fias, Reynvoet and Brysbaert2001; Reynvoet & Brysbaert, Reference Reynvoet and Brysbaert1999), we adopted a parity judgment task for judging the numerals instead of using a semantic judgment task in the present study.
1.2. Numeral representations in bilinguals
For monolinguals, three influential models have been proposed to explain number representation and processing. The abstract-modular model proposed by McCloskey (Reference McCloskey1992), McCloskey and Macaruso (Reference McCloskey and Macaruso1995), and McCloskey et al. (Reference McCloskey, Sokol and Goodman1986) states that different appearances of numbers are converted into a common notation-independent abstract representation before further number operations. According to their theory, number facts are assumed to be represented in abstract format and the calculation system is also based on abstract quantity codes. A production system is also suggested to transcode the abstract output into Arabic digits or other number notations. Like the abstract-modular model, a triple-code model (Cohen & Dehaene, Reference Cohen and Dehaene1995; Dehaene, Reference Dehaene1992) also assumes that numerical judgments and calculations are not affected by numeral appearance. However, the triple-code model also states that three types of codes are stored in the human brain: a visual-Arabic code is assumed to mediate digits and is active during parity judgments and multi-digit calculation; an auditory-verbal code is used to support spoken and written input and output, and to provide the representational basis for simple tasks involving math concepts and accurate calculation; and an analog-magnitude number code, which is thought to be used when performing quantity estimation and number comparison. According to the triple-code model, after the information is transcoded into the appropriate representation among these three, number processing proceeds independently of the input format. In contrast, the encoding-complex model (Campbell, Reference Campbell1994; Campbell & Epp, Reference Campbell and Epp2004) presumes that number processing is mediated by format-specific processes instead of an abstract code, and that number processing with regard to the retrieval of arithmetic facts is largely dependent on the physical formats of the number. Moreover, the encoding-complex model highlights the influence of cultural and idiosyncratic experiences on number processing.
Results from studies of number processing among bilinguals are more consistent with the encoding-complex model (Bernardo, Reference Bernardo2001; Campbell et al., Reference Campbell, Kanz and Xue1999; Frenck-Mestre & Vaid, Reference Frenck-Mestre and Vaid1993; Marsh & Maki, Reference Marsh and Maki1976; McClain & Huang, Reference McClain and Huang1982). Campbell et al. (Reference Campbell, Kanz and Xue1999) used different language formats to investigate the performance of Chinese–English bilinguals on different number tasks. They found that the arithmetic was faster when participants responded in Chinese than in English and that this advantage became greater when the stimuli were presented in Mandarin symbols. Based on this model, Bernardo (Reference Bernardo2001) proposed the bilingual encoding-complex model (BECM) to explain number representation and processing in bilinguals. The BECM assumes three distinct memory codes for different number representations in bilinguals: Arabic digits, verbal codes in L1, and verbal codes in L2. The activation and retrieval of number information depend on the stimulus format.
Models of number processing assume different representational modules in the human brain: an abstract format-independent representation code, three types of format codes, including Arabic digits and verbal numeral codes, or a variety of format-specific representational codes. However, no direct evidence has shown how bilinguals represent different numeral formats. The BECM proposes an Arabic code and verbal L1 and L2 codes. From the perspective of language processing, this model is consistent with the representation models of language in bilinguals. For instance, according to the Shared Representational Model, L1 and L2 share a conceptual representation, but their lexical representations are separate. In the current study, we directly investigated whether all three codes share representation at the conceptual level and whether each has a separate lexical representation.
1.3. Current study
This study investigated how numbers in different languages are represented in Tibetan–Mandarin bilinguals. Specifically, the question addressed here is whether Arabic digits, Tibetan numerals, and Mandarin numerals share a conceptual representation, but are stored separately from each other at the lexical level. We used a cross-language long-term repetition-priming paradigm because it is commonly used to investigate bilingual language representation (Zeelenberg & Pecher, Reference Zeelenberg and Pecher2003). If Tibetan numerals and Mandarin numerals share a conceptual representation, the cross-language long-term repetition-priming effect is expected when participants perform the parity judgment task in the paradigm. Thus, the presentation of the Tibetan numerals should facilitate responses to their subsequently presented Mandarin equivalents. At the lexical level, a shared representation would result in a priming effect during a lexical decision task.
Two main experiments were conducted to examine these questions. In the first experiment, we used a lexical decision task during which participants were asked to distinguish between true and pseudo-numerals. In the second experiment, they performed a parity judgment task involving a conceptual activation. We expected to find that number notations shared a conceptual representation but had distinct lexical representations.
2. Experiment 1
Experiment 1 explored three types of numerical representations at the lexical level. The between-language relationships in focus were Tibetan numerals versus Arabic digits, Mandarin numerals versus Arabic digits, and Mandarin versus Tibetan numerals. According to the cross-language long-term repetition paradigm, the experiment included a learning phase and a testing phase. Participants performed a lexical decision task (i.e., true-numeral or pseudo-numeral). If the presentation of the Tibetan numerals during the learning phase facilitated responses to their Arabic equivalents in the testing phase, it would indicate that they activate each other (i.e., a shared representation). In experiment 1a, Arabic numerals were used during the testing phase, and Tibetan and Mandarin numerals were used as primes during the learning phase. In Experiment 1b, Tibetan numerals were used during the testing phase and Mandarin numerals were used as primes.
2.1. Experiment 1a: lexical representation of Arabic digits, Tibetan numerals, and Mandarin numerals
2.1.1. Methods
Participants
Ninety Tibetan students (52 females, mean age: 16.1 years, range from 13 to 18) were recruited from a high school for students from ethnic minority regions.Footnote 1 All the participants were high-school students who came to mainland China to prepare for the university entrance examination, and they lived in mainland China for an average of 0.75 years. As their native language, Tibetan was learned earlier than Mandarin which was exposed in the family from an early age. The systematic learning of Mandarin started as participants entered primary schools. As their school language, they used Mandarin most of the time in middle and high school. The teachers taught in Mandarin, including mathematics teaching. While they spoke Tibetan with their parents when they were at home. All participants were able to easily switch between Mandarin and Tibetan. Participant abilities for listening, reading, speaking, and writing Mandarin were evaluated by a five-point scale, in which ‘5’ stands for very proficient. The average Mandarin proficiency for listening, reading, speaking, and writing was 4.35, 4.43, 4.43, and 4.26, respectively. The average Mandarin proficiencies were 4.37, indicating a very proficient Mandarin level. All participants were physically and mentally healthy and none had participated in similar psychological experiments before. Participants who completed the experiment received compensation for participating.
Materials and design
Thirty Tibetan students (15 male, 15 female) were randomly selected from the high school for ethnic minorities. They were asked to evaluate the familiarity of the different number systems (i.e., Arabic digits, Tibetan numerals, and Mandarin numerals) by a five-point scale, in which ‘5’ stands for very familiar and ‘1’ stands for very unfamiliar. They had average scores of 4.90 out of 5 for familiarity with Arabic digits (1 through 100), 4.93 for familiarity with Tibetan numerals, and 4.90 for familiarity with Mandarin numerals. A t-test analysis found no significant difference in familiarity depending on the number format (p > 0.05).
Sixty pairs of corresponding two-digit Tibetan–Arabic and Mandarin–Arabic numerals (total 120) were randomly chosen (half even and half odd) and then divided into two groups for each pair (half even and half odd). One group of pairs for each language condition (e.g., Tibetan–Arabic) was randomly selected to be used in the learning phase and both groups appeared during the testing phase.
An equal number of pseudo-numerals for each of the three number formats were used as fillers for the lexical decision task. To match the Mandarin numerals, 10 Mandarin pseudo-numerals were chosen from simple characters that do not represent any quantities (甲, 乙, 丙, 丁, 天, 上, 人, 刀, 口, 云). Similarly, to match the Tibetan numerals and Arabic digits, 10 Tibetan pseudo-numerals were chosen from the Tibetan alphabet (ཆ, ས, བ, མ, ཤ, ཁ, ཉ, ཇ, ཕ, ཡ) and 10 symbols (#, *, ↓, ↑, ¥, △, ○, @, ♂, ♀) were chosen from a symbol font, respectively. Within each pseudo-numeral set, the pseudo-numerals were randomly paired to form nonnumerals two characters in length (matching the 2-digit pairs of real numerals).
The learning phase included 30 true-numerals and 30 pseudo-numerals. The testing phase included 60 true-numerals (30 studied-numerals or translation equivalents of the studied-numerals and 30 unstudied-numerals) and 60 pseudo-numerals. All numerals were randomly presented once, and the pseudo-numerals that appeared in the learning phase did not appear again in the testing phase.
The experiment adopted a 2 (testing numeral type: unstudied-numerals or studied-numerals) × 3 (language in learning phase-test phase set: Arabic–Arabic [A–A], Tibetan–Arabic [T–A], and Mandarin–Arabic [M–A]) factor mixed experimental design. The testing numeral type was the within-subjects variable, the phase set was the between-subjects variable, and the dependent variables were reaction time and accuracy of the decision-making task for Arabic digits during the testing phase.
Procedure
Before the formal experiment, participants were required to read and understand the instructions. Then they familiarized themselves with the task by completing a practice session. Throughout the experiment, they sat 50 cm from a computer monitor. The procedure for a trial is shown in Fig. 1. First, a red fixation cross appeared for 500 ms in the middle of the screen. Then, the stimuli appeared, and participants were asked to perform a decision task quickly and accurately. For each word, they pressed the ‘A’ key on the keyboard with their left hand if the word was a true-numeral and the ‘L’ key with their right hand if it was a pseudo-numeral. During the experiment, the left- and right-hand buttons were balanced (i.e., true-numeral with an ‘L’ key and pseudo-numeral with an ‘A’ key). If there they did not respond within 1,500 ms, the word disappeared automatically. After the response or the 1,500-ms limit, a blank screen was presented for 500 ms, and then the next trial began. After completing the practice task, the formal experiment began. The formal experiment had two stages: the learning phase and the testing phase. Instructions were given in Mandarin before each phase. A visual word (correct or wrong) feedback was provided after responses in the learning phase, but not in the test stage. The reaction time in ms and performance accuracy were recorded throughout the experiment.

Fig. 1. Procedure of Experiment 1a.
2.1.2. Results and discussion
The data was excluded from the results if participants were not serious during the experiment and had accuracy rates higher than 70%. A three-sigma rule (Chen et al., Reference Chen, Wang and Peng2006, Reference Chen, Zhou, Gao and Dunlap2014; Pukelsheim, Reference Pukelsheim1994) was performed to delete the outliers, that is, the data beyond 3 standard deviations of the mean reaction times were excluded. No data was excluded in experiment 1a. The results are shown in Table 1 and Fig. 2. We performed ANOVA by participants (F 1) and items (F 2) separately.
Table 1. Average reaction time (ms) and average accuracy rate (%) for Arabic digits in the test phase


Fig. 2. Reaction times for the three learning-phase sets in the unstudied and studied conditions (ms).
The ANOVA for reaction time showed a significant main effect of testing numeral type for the participant analysis, F 1(1, 87) = 7.23, p < 0.05, η 2 = 0.08. The mean reaction time in the studied condition (528.12 ms) was significantly shorter than in the unstudied condition (535.01 ms), p < 0.05. However, we did not find a significant effect of testing numeral type in the item analysis (p > 0.05). The main effect of the learning-phase set was not significant (p > 0.05) for the participant analysis, but it was significant for the item analysis, F 2(2, 57) = 44.84, p < 0.05, η 2 = 0.61. The reaction time in the A–A condition (503.93 ms) was the fastest, followed by the T–A condition (541.58 ms), and the M–A condition (542.05 ms). Pairwise comparisons revealed a significant difference between A–A and T–A conditions (p < 0.05) and between A–A and M–A conditions (p < 0.05), but not between T–A and M–A conditions (p > 0.05). The interaction between testing numeral type and the learning-phase set was marginally significant, F 1(2, 87) = 2.77, p = 0.07, η 2 = 0.06. Further simple effect analysis showed that when the stimuli in the learning phase were Arabic digits, the reaction time in the test phase for the studied numerals (506.40 ms) was significantly faster than for the unstudied numerals (521.81 ms), F 1(1, 87) = 12.06, p < 0.05, η 2 = 0.12. However, when the stimuli in the learning phase were Tibetan and Mandarin numerals, there were no significant differences between the studied and unstudied conditions in the test phase (p > 0.05).
Therefore, although experiment 1a showed a long-term repetition-priming effect of Arabic numerals on Arabic numerals, the effect disappeared if the numerals in the learning phase were Tibetan or Mandarin (i.e., the cross-language conditions). This indicates that neither Tibetan numerals nor Mandarin numerals can activate Arabic digits at the lexical level. Thus, the results suggest that Arabic digits, Tibetan numerals, and Mandarin numerals are represented independently at the lexical level.
2.2. Experiment 1b: lexical representation of Tibetan and Mandarin numerals
2.2.1. Methods
Participants
Sixty Tibetan students (25 males and 35 females, mean age: 16.2 years, range from 15 to 19) were recruited. They were in the same high school as the participants in experiment 1a and had also lived in mainland China for an average of 0.75 years. The average Mandarin proficiency for listening, reading, speaking, and writing was 4.28, 4.37, 4.41, and 4.32, respectively. The average Mandarin proficiencies were 4.32.
Materials and design
As in experiment 1a, Tibetan and Mandarin numerals were selected according to the purpose of the experiment. Tibetan–Tibetan (T–T) and Mandarin–Tibetan (M–T) phase sets were selected for the learning and test phases. The experiment adopted a 2 (testing numeral type: unstudied numerals or studied numerals) × 2 (learning-test phase set: T–T or M–T) two-factor mixed experimental design.
Procedure
The procedure was the same as that used in experiment 1a, except that Arabic digits were not used and the test phase used Tibetan numerals.
2.2.2. Results and discussion
Data were analyzed in the same manner as in experiment 1a. No data were excluded. The results are shown in Table 2 and Fig. 3.
Table 2. Average reaction time (ms) and average accuracy rate (%) for Tibetan numerals in the test phase


Fig. 3. Reaction times for the two learning-test phase sets in the studied and unstudied conditions (ms).
The ANOVA revealed a significant main effect of testing numeral type in the participant analysis, F 1(1, 58) = 5.52,p < 0.05, η 2 = 0.09, but not in the item analysis (p > 0.05). We also found a significant main effect of the learning-phase set, F 1(1, 58) = 6.02, p < 0.05, η 2 = 0.09; F 2(1, 58) = 18.51, p < 0.05, η 2 = 0.24. The interaction between the two factors was marginally significant, F 1(1, 58) = 3.33, p = 0.07, η 2 = 0.05. Further simple effect analysis showed that when the stimuli in the learning phase were Tibetan numerals, the mean reaction time in the studied condition (576.33 ms) was significantly faster than in the unstudied condition (593.23 ms), with a 16.90-ms difference, F 1(1, 58) = 8.71, p < 0.05, η 2 = 0.13. No significant differences between studied and unstudied conditions were found in the participant analysis or the item analysis when the stimuli in the learning phase were Mandarin numerals (p > 0.05).
In summary, experiment 1b also showed a repetition-priming effect, provided that the numerals in the learning and test phases were presented in the same language (Tibetan). However, we did not observe a cross-language priming effect, indicating that Mandarin numerals failed to activate Tibetan numerals at the lexical level, again suggesting that Tibetan and Mandarin numerals are stored independently at the lexical level.
3. Experiment 2
In experiment 2, the representation of the three types of numerals was explored at the conceptual level. The design and logic were similar to experiment 1, except that participant performed a parity judgment task (i.e., even or odd judgment) in which conceptual information must be accessed. If the presentation of Tibetan numerals in the learning phase facilitates responses to their Arabic equivalents in the testing phase, it indicates that they activate each other at the conceptual level.
3.1. Experiment 2a: conceptual representation of Arabic digits, Tibetan numerals, and Mandarin numerals
3.1.1. Methods
Participants
Ninety Tibetan students (36 males and 54 females, mean age: 16.0 years, range from 13 to 18) were recruited. They were in the same high school as the participants in experiment 1 and had also lived in mainland China for an average of 0.75 years. The average Mandarin proficiency for listening, reading, speaking, and writing was 4.42, 4.23, 4.31, and 4.03, respectively. The average Mandarin proficiencies were 4.12.
Materials and design
Forty pairs of corresponding two-digit Tibetan–Arabic and Mandarin–Arabic numerals were randomly selected from those used in experiment 1 (half odd and half even), and 60 numerals (1–100, not including the 40 selected numerals) were used as fillers. The 40 pairs were randomly divided into two groups (half even and half odd in each group). One group of pairs was selected as the stimuli for the learning phase, while both groups were included in the testing phase. Thus, the learning phase contained 20 numerals and 20 fillers, and the testing phase included 40 numerals (20 previously seen numerals or their translated equivalents and 20 new numerals) and 40 fillers. Data analysis was the same as in Experiment 1a.
Procedure
The experimental procedure was almost the same as in experiment 1, except that participant made parity judgments instead of lexical decisions (see Fig. 4).
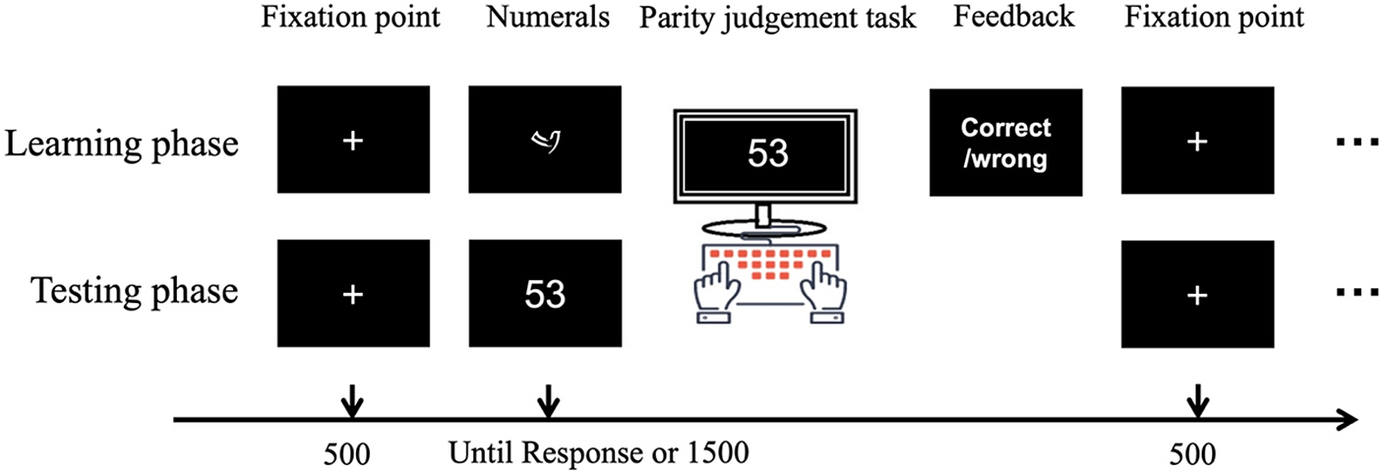
Fig. 4. Procedure for Experiment 2a.
3.1.2. Results and discussion
We excluded three participants’ data because their accuracy rates were lower than 70%. We also excluded data beyond 3 standard deviations from the mean. Overall, 3.33% of the data were excluded from the analyses. The results are shown in Table 3 and Fig. 5.
Table 3. Average reaction time (ms) and average accuracy rate (%) for Arabic digits in the test phase


Fig. 5. Reaction times for the three learning-test phase sets in the studied and unstudied conditions (ms).
The ANOVA analysis for reaction time showed a significant main effect of testing numeral type in the participant analysis, F 1(1, 84) = 16.63, p < 0.001, η 2 = 0.17, but not for the item analysis (p > 0.05). We also found a significant main effect of the learning-phase set, F 1((2, 84) = 5.72, p < 0.01, η 2 = 0.12; F 2(2, 37) = 57.90, p < 0.05, η 2 = 0.76. Participants responded fastest in the A–A condition, followed by the M–A and T–A conditions. Pairwise comparisons showed significant differences between A–A and T–A conditions (p < 0.05) and between A–A and M–A conditions (p < 0.05), but not between T–A and M–A conditions (p > 0.05). The interaction between the two factors was not significant (p > 0.05). In all three learning-test phase sets (A–A, T–A, M–A), reaction times for the studied numerals were significantly faster than those for the unstudied numerals (A–A: studied vs. unstudied = 615.04 vs. 630.85 ms, F 1(1, 84) = 4.78, p < 0.05, η 2 = 0.05; T–A: 676.70 vs. 692.88 ms, F 1(1, 84) = 5.19, p < 0.05, η 2 = 0.06; M–A: 662.01 vs. 681.08 ms, F 1(1, 84) = 6.72, p < 0.05, η 2 = 0.07).
In summary, experiment 2a showed a priming effect for Arabic digits regardless of the number format in the learning phase. Specifically, we observed a cross-language long-term repetition-priming effect, indicating that the conceptual representation of Arabic digits was activated in the learning phase by the Mandarin and Tibetan numerals, suggesting that the semantic representation of Arabic digits and the semantic representation of Tibetan and Mandarin numerals are not stored separately.
3.2. Experiment 2b: conceptual representation of Tibetan and Mandarin numerals
3.2.1. Methods
Participants
Sixty Tibetan students (26 males and 34 females, mean age: 16.2 years, range from 15 to 19) were recruited. They were in the same high school as the participants in experiment 1 and had also lived in mainland China for an average of 0.75 years. The average Mandarin proficiency for listening, reading, speaking, and writing was 4.14, 4.24, 4.32, and 4.01, respectively. The average Mandarin proficiencies were 4.21.
Materials and design
As in experiment 2a, Tibetan and Mandarin numerals were selected according to the purpose of the experiment. Tibetan–Tibetan (T–T) and Mandarin–Tibetan (M–T) sets were selected for the learning and test phases. The experiment adopted the same two-factor mixed experimental design as Experiment 1b.
Procedure
The procedure was the same as in experiment 2a, except that Arabic digits were not used and the test phase was always Tibetan numerals.
3.2.2. Results and discussion
Data were analyzed as in experiment 2a and data from the same individuals were removed, as were data beyond 3 standard deviations from the reaction time mean. The experimental results are shown in Table 4 and Fig. 6.
Table 4. Average reaction time (ms) and average accuracy rate (%) for Tibetan numerals in the test phase


Fig. 6. Reaction times for the two learning/test phase sets in the studied and unstudied conditions (ms).
ANOVA analysis for reaction time showed a significant main effect of testing numeral type in both participant and item analyses, F 1(1, 55) = 4.84, p < 0.05, η 2 = 0.08; F 2(1, 38) = 4.47, p < 0.05, η 2 = 0.11. The main effect of the learning-phase set was not significant for the participant analysis (p > 0.05), but it was significant for the item analysis, F 1(1, 38) = 4.99, p < 0.05, η 2 = 0.12. The interaction between the two factors was not significant for the participant analysis (p > 0.05), but it was for the item analysis, F 2(1, 38) = 2.08, p < 0.05, η2 = 0.05. Further simple effect analysis showed that in both the T–T and M–T conditions, the reaction time was faster for the studied numerals than for the unstudied numerals, with the difference being significant for the T–T condition and marginally significant for the M–T condition (T–T: 760.69 vs. 773.52 ms, F 1(1, 55) = 1.62, p > 0.05, η 2 = 0.03; M–T: 770.78 vs. 789.56 ms, F 1(1, 55) = 3.36, p = 0.07, η 2 = 0.06).
Therefore, experiment 2b again revealed a repetition-priming effect in the cross-language condition. Specifically, conceptual representations of Tibetan numerals were activated in the learning phase by the Mandarin numerals, again suggesting that the semantic representations of Tibetan and Mandarin numerals are stored together.
4. General discussion
The present study used a cross-language long-term repetition-priming paradigm to investigate how number symbols and number words in different languages are represented in Tibetan–Mandarin bilinguals at lexical and conceptual levels. In experiment 1, the lexical decision task showed that neither presentation of Tibetan numerals nor Mandarin numerals facilitated subsequent responses to Arabic digit equivalents. Further, Mandarin numerals did not facilitate responses to Tibetan numerals. Thus, no cross-language repetition-priming effect was found between Tibetan and Mandarin numerals. The result of experiment 1 indicated that Arabic digits, Tibetan number words, and Mandarin number words are stored separately at the lexical level. Participants performed a parity judgment task in experiment 2, we found that the presentation of Tibetan numerals and Mandarin numerals did facilitate subsequent responses to Arabic digit equivalents. Additionally, Mandarin numerals facilitated responses to Tibetan numerals. Results from experiment 2 thus indicated that Arabic digits, Tibetan number words, and Mandarin number words share conceptual representations. In summary, different number formats shared conceptual representations, but their lexical representations were independent.
4.1. Lexical and conceptual representations of numbers in Tibetan–Mandarin bilinguals
In our two experiments, we treat the three kinds of number notations as three languages. They have different physical forms (e.g., the Arabic digit ‘9’, the mandarin word 九, and the Tibetan word དགུ་) but have the same meaning. We want to know how these number notations are represented in the brain at the lexical and conceptual levels. Thus, in experiment 1, to examine the characteristics of their lexical representations, bilingual participants completed the task in which they judged whether they were seeing true-numerals or pseudo-numerals, but did not have to access the meaning of the number. In experiment 2, to examine characteristics of the conceptual representation of these number formats, participants perform a parity judgment task in which semantic access to the number was required. Evidence of a priming effect at the lexical or conceptual level would indicate that the number notations share lexical or conceptual representations.
In the current study, neither the Tibetan nor Mandarin numerals presented in the learning phase activated the lexical information of their corresponding Arabic digits, nor did the Mandarin numerals presented in the learning phase activate the corresponding Tibetan numerals. This indicates that the lexical information for Arabic digits, Tibetan numerals, and Mandarin numerals are stored independently. The fact that the facilitation effect of Tibetan numerals and Mandarin numerals on Arabic digits, and the facilitation effect of Mandarin numerals on Tibetan numerals at the conceptual level illustrate that Arabic digits, Tibetan number words, and Mandarin number words share conceptual representations. Thus, our results are inconsistent with the Independent Representational Model (Kolers, Reference Kolers1963), which suggested that each language has a separate system of memory representation. Rather, our results were more in line with the Shared Representational Model (e.g., Kroll & Stewart, Reference Kroll and Stewart1994; Potter et al., Reference Potter, So, Eckardt and Feldman1984) or the Distributed Feature Model (Groot et al., Reference Groot, Dannenburg and Vanhell1994); bilinguals have a shared conceptual store and separate lexical stores for these three number notations.
Our results were consistent with previous studies of bilingualism. For example, Li et al. (Reference Li, Mo, Wang and Luo2006) and Mo et al. (Reference Mo, Li and Wang2005) both examined Chinese–English bilinguals in their studies on the lexical representation of words, finding that the two languages are represented independently at the lexical level. Cui and Zhang (Reference Cui and Zhang2009) and Gao et al. (Reference Gao, Wang, Guo, Zhang and Bai2015) also studied the representation of words in bilingual Chinese minorities. They also found that in Tibetan–Chinese bilinguals, lexical information was stored separately. Like results on conceptual representation, previous studies have also found that the semantic representations of equivalent words in bilinguals are costored (Cui & Zhang, Reference Cui and Zhang2009; Gao et al., Reference Gao, Wang, Guo, Zhang and Bai2015; Li et al., Reference Li, Mo, Wang and Luo2006a; Li & Li, Reference Li and Li2019; Mo et al., Reference Mo, Li and Wang2005; Wen & Rabigul, Reference Wen and Rabigul2006). Although there is a very strong argument that numerical concepts have an ontogenetic origin and a neural basis that are independent of language (see Gelman & Butterworth, Reference Gelman and Butterworth2005, for a review), we found that for skilled bilinguals, representation of numbers at the lexical and conceptual levels was similar to that for general words. Moreover, connections between number and language have been proposed on theoretical and empirical grounds (Dehaene & Cohen, Reference Dehaene and Cohen1991; McCloskey, Reference McCloskey1992; Spelke & Tsivkin, Reference Spelke and Tsivkin2001).
4.2. Relationship between the central findings and current models of number processing
How can we relate the current critical findings to current models of number processing? We mentioned three number processing models in the introduction: the abstract-modular model proposed by McCloskey (Reference McCloskey1992), McCloskey and Macaruso (Reference McCloskey and Macaruso1995), and McCloskey et al. (Reference McCloskey, Sokol and Goodman1986), the triple-code model proposed by Cohen and Dehaene (Reference Cohen and Dehaene1995) and Dehaene (Reference Dehaene1992), and the encoding-complex model proposed by Campbell (Reference Campbell1994) and Campbell and Epp (Reference Campbell and Epp2004). These models agree that Arabic digits and number words are processed by separate input modules. For example, the abstract-modular model proposed two different input systems for Arabic digits and number words onto a common abstract representation of magnitude (McCloskey, Reference McCloskey1992). The triple-code model specifies three different modules, including a visual Arabic system for mediating Arabic digital input, an auditory-verbal system for mediating the written and spoken number-word input, and a system for estimation (Dehaene, Reference Dehaene1992). Dehaene et al. (Reference Dehaene, Dehaene-Lambertz and Cohen1998) proposed that verbal numerals and Arabic digits have independent visual recognition systems. The encoding-complex model also involves format-specific activation in one or more representational codes (e.g., visual and verbal). Our results from experiment 1 were consistent with the proposition hypothesized by these models of number processing; different number notations are stored separately at the lexical level (i.e., physical forms) in the brain. This is consistent with the idea of different input systems found in the three number-processing models.
At the conceptual level, it seems that our results are consistent with the abstract-modular model (McCloskey, Reference McCloskey1992). The numeral comprehension module in this model converts different number forms (e.g., Arabic digits, Tibetan numerals, Mandarin numerals) into a common abstract code, which is much the same as a common conceptual representation shared by number notations. Similarly, the triple-code model also assumes that tasks that activate semantics are not affected by the numeral form.
Interestingly, we analyzed the data from the learning phase to examine the response difference between the three notations. In detail, a significant difference was found between number words and Arabic numerals (M = 511 ms, SD = 69.8 ms) when they performed a lexical decision task (Tibetan: M = 607 ms, SD = 89.5 ms, t (29) = 4.32, p < 0.001; Mandarin: M = 602 ms, SD = 75.1 ms, t (29) = 4.85, p < 0.001). And the significant difference was also found in the parity judgment task (Arabic: M = 666 ms, SD = 78.0 ms; Tibetan: M = 776 ms, SD = 133.5 ms, t (29) = 3.51, p < 0.01; Mandarin: M = 757 ms, SD = 97.1 ms, t (29) = 3.87, p < 0.001). Obviously, the current results are inconsistent with the abstract-modular model. According to this model, the responses to the three number notations should be the same. However, responses to both Tibetan and Mandarin numerals were found to be slower than those to Arabic digits, which supported the triple-code model or the encoding-complex model. Moreover, our results were consistent with previous studies of number processing in which Arabic digits were processed faster than number words in numerical and magnitude-judgment tasks or in simple addition and multiplication tasks (Campbell et al., Reference Campbell, Kanz and Xue1999; Damian, Reference Damian2004).
Here, we would like to adopt the encoding-complex model proposed by Campbell and Epp (Reference Campbell and Epp2004) and the work by Bernardo (Reference Bernardo2001) to explain the characteristics of number processing in Tibetan–Mandarin bilinguals. The encoding-complex model contains five representational systems: L1 visual codes and Arabic visual codes for numeral input and output processes; L1 and L2 verbal number codes for processing the language-based components, including the lexical processes; and a magnitude code that provides the conceptual foundation of quantity and serves as the central nexus of the model. The efficiency of interactions between these codes is expected to correspond to how our participants’ history of experience of tasks, numeral formats, and languages affect the encoding pathways. This model explains our research results very well: a shared conceptual representation (i.e., the magnitude code) and a separately stored lexical representation. Specifically, it assumes that one more code, the Tibetan visual code, is included in addition to the five codes proposed by Campbell and Epp (Reference Campbell and Epp2004). Fig. 7 depicts an encoding-complex model of Tibetan–Mandarin bilinguals’ number representation. The result that Arabic digits, Tibetan number words, and Mandarin number words are stored separately corresponds to three independent visual codes for Arabic, Tibetan, and Mandarin in the model. The magnitude code corresponds to the fact that all the numerals share a common conceptual representation. In the model, darker arrows represent stronger links between the codes. The result that the responses were faster for Arabic digits was shown in the model by darker-arrow links than the links between visual code and magnitude code. In addition, a faster response for the Mandarin numerals than the Tibetan numerals was shown in the model by darker-arrow links between Mandarin visual code and magnitude (see more discussion below). However, the current study did not explore all the links in the model, such as the pathways between the verbal number code and the magnitude code, which were shown by bidirectional arrows with a dotted outline. The model will be improved by future research.
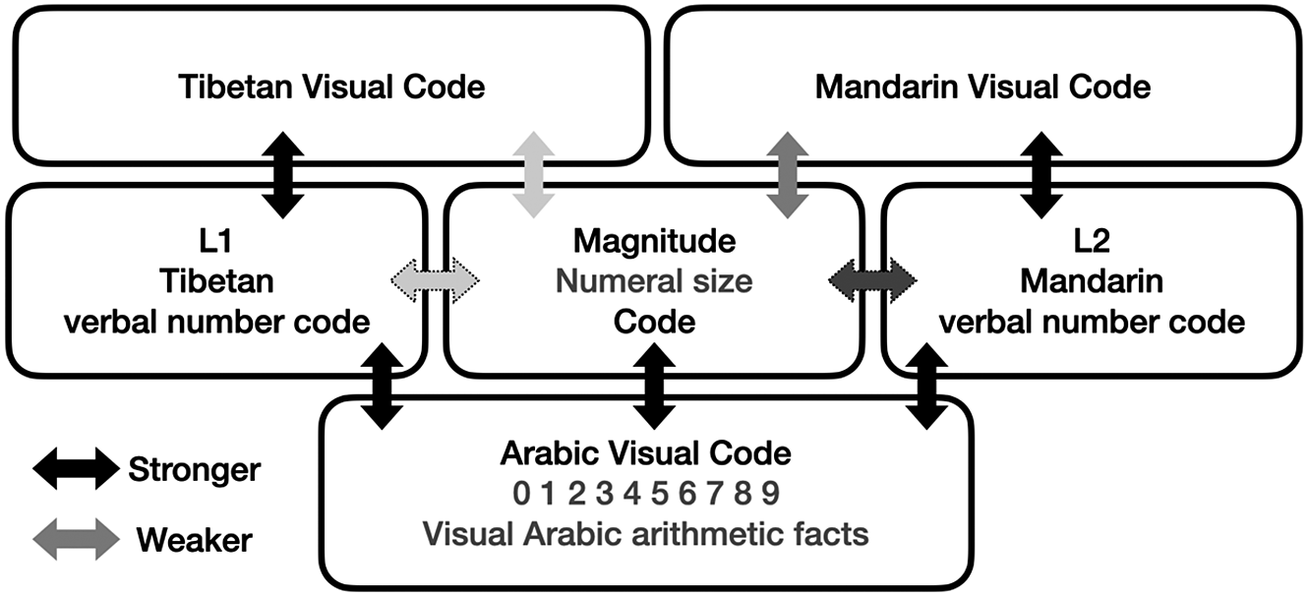
Fig. 7. Encoding-complex model of number processing in Tibetan–Mandarin bilinguals.
Two problems regarding the participants whom we recruited should also be clarified. On one hand, we would like to explain the relationship between the Tibetan and Chinese languages. Although the Sino-Tibetan language family includes early literary languages such as Chinese and Tibetan, there are great differences between the language types within the Sino-Tibetan language family. The Sino-Tibetan language family is traditionally presented as divided into Sinitic (i.e., Chinese) and Tibeto-Burman branches, which show many differences in typological contrasts such as written form, word order, and morphology. For the word order, Chinese word order is subject-verb-object while Tibetan word order is subject-object-verb. For the written form, Chinese is ideographic while Tibetan is recorded in alphabetic scripts. In the number domain, just like the languages, Tibetan number words are in alphabetic written form while Chinese number words are in ideographic written form. Hence, we consider those who master both Tibetan and Chinese to be bilinguals and these two languages can cause differences in information processing.
On the other hand, the participants’ language proficiency should also be illustrated. The Tibetan–Mandarin bilinguals in the current study have been studying and speaking Mandarin for a long time, and they have been living in mainland China for a period of time as we described in the method. Moreover, we asked participants about their daily use of Mandarin in mainland China after the experiment. The participants and the people around them speak Mandarin in their daily lives. Most of the participants recruited in the current study passed the national Chinese language test or the practice test for the college entrance examination. The examination is proved to be more scientific, and more comprehensive than the Chinese proficiency test for minorities (Level 3) (Hua, Reference Hua2020). Thus, we consider them to be balanced bilinguals, and they have no impact on the findings of numeral representations, which is also consistent with the finding of no effect of language experience on brain activity underlying arithmetic by Brignoni-Pérez (Reference Brignoni‐Pérez, Matejko, Jamal and Eden2021).
Another finding of the current experiment further supports this problem. In the present study, we found a faster response for the Mandarin numerals than the Tibetan numerals, even though Tibetan was the native language (L1). It should be noted that Arabic digits were assumed to be processed much the way objects are; the semantic information was accessed directly just like in picture naming (Damian, Reference Damian2004; Fias, Reference Fias2001; Fias et al., Reference Fias, Reynvoet and Brysbaert2001; McCloskey, Reference McCloskey1992). Studies in Chinese word recognition found that the word meaning is mainly achieved directly through orthography (Zhou et al., Reference Zhou, Bai, Shu and Qu1999; Zhou & Marslen-Wilson, Reference Zhou and Marslen-Wilson2000). Thus, the reason why Chinese number words were processed faster than Tibetan numerals could be that the semantic information for both Mandarin numerals and Arabic digits could be accessed directly through the written form. Interestingly, this result was also consistent with the more specific propositions of the BECM (Bernardo, Reference Bernardo2001). In Bernardo’s study, they suggested that the stronger verbal code is not always in the native language, but in the language used for learning and practicing arithmetic tasks. The Tibetan–Mandarin bilinguals recruited here not only learned and used Arabic digits at an early age in school but also have been studying and living in mainland China for a period of time. Using Mandarin verbal numbers more frequently might strengthen the link between the Mandarin visual code and the magnitude code.
In summary, by conducting two experiments, we investigated the representation of Arabic digits, Tibetan numerals, and Mandarin numerals at the lexical and conceptual levels. Results showed that these number notations shared a conceptual representation but had independent lexical representations. Among three number-processing models, our results are best explained by the encoding-complex model.
5. Conclusion
The current study found that the representation of lexical information for Tibetan numerals, Arabic digits, and Mandarin numerals was independent for skilled Tibetan–Mandarin bilinguals. At the conceptual level, the representations were shared. Our results support the encoding-complex model of number processing.
Acknowledgments
This work was supported by a grant from the Natural Science Foundation of China (31671151); the 111 Project (BP0719032); and a grant from the Advanced Innovation Center for Future Education (27900-110631111); the Projects of the Hebei Social Science Foundation (HB19JY025; HB22JY041); Humanities and Social Sciences Research Project of Colleges and Universities in Hebei Province (SQ2022133).
Author contributions
All authors contributed to the study design. Z.C. developed the study concept. H.H. performed the experimental program and the data analysis, and drafted the manuscript. Testing and data collection were performed by N.A. Z.C. and X.Z. provided critical revisions. All authors contributed to the study design. All authors approved the final version of the manuscript for submission.
Conflict of interests
The authors declare none.
Data availability statement
Study materials and data are posted at https://doi.org/10.6084/m9.figshare.19450826.











