



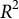
1 Introduction
Large language models have been gaining popularity among political scientists (Bestvater and Monroe Reference Bestvater and Monroe2023; Wang Reference Wang2023b). These models are known for being easy to use for end-to-end training and accurate in making predictions. The downsides of these large language models, however, are that they are slow to run and hard to interpret. In an effort to overcome these shortcomings, Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) introduce an interpretable deep learning approach to domain-specific dictionary creation. Such an approach, coupled with Random Forest or XGBoost (Wang Reference Wang2019), creates accurate and interpretable models. Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) claim that these new models outperform finetuned ConfliBERT models.Footnote 1 In this letter, we show that the apparent superiority of the newly proposed dictionary-based method stems from the fact that most of the parameters in the BERT model are excluded from training at the finetuning stage. We first illustrate the BERT model’s architecture and explain which components are actually being finetuned, then we demonstrate how we can maximize learning by making all parameters trainable, and lastly we report the new results with fully finetuned BERT models that outperform the dictionary-based approach by a large margin.
2 Finetuning BERT Models
2.1 The BERT Architecture
BERT models are first introduced in Devlin et al. (Reference Devlin, Chang, Lee, Toutanova, Burstein, Doran and Solorio2019). These are large language models that are initially pretrained with billions of words on tasks, such as masked language modeling and next sentence prediction. They are then finetuned on specific downstream tasks, such as topic classification and conflict prediction.Footnote 2 Under this pretrain-and-finetune paradigm, BERT models have achieved the state-of-the-art results in various natural language processing tasks. There have also been many variations of BERT models based on more training data (Liu et al. Reference Liu2019), new data domains (Hu et al. Reference Hu2022), and new pretraining tasks (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020).
In Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023), for the task of predicting the natural logarithm of fatalities on a country month level using the CrisisWatch text, the BERT model attains an
 $R^2$
of 0.60, which is lower than the 0.64 achieved by the recently introduced dictionary-based approach.Footnote
3
We demonstrate that BERT’s apparent inferior performance is due to the fact that Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) freeze all the parameters in the BERT model except the classification layer. In Figure 1, we illustrate the architecture of a BERT model. A BERT model consists of four components: embedding layers (2.3 million parameters), encoder (8.5 million parameters), the pooler layer (0.6 million parameters), and the classification layer (769 parameters). The majority of the parameters lie in the encoder and the embeddings (blue boxes).Footnote
4
$R^2$
of 0.60, which is lower than the 0.64 achieved by the recently introduced dictionary-based approach.Footnote
3
We demonstrate that BERT’s apparent inferior performance is due to the fact that Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) freeze all the parameters in the BERT model except the classification layer. In Figure 1, we illustrate the architecture of a BERT model. A BERT model consists of four components: embedding layers (2.3 million parameters), encoder (8.5 million parameters), the pooler layer (0.6 million parameters), and the classification layer (769 parameters). The majority of the parameters lie in the encoder and the embeddings (blue boxes).Footnote
4
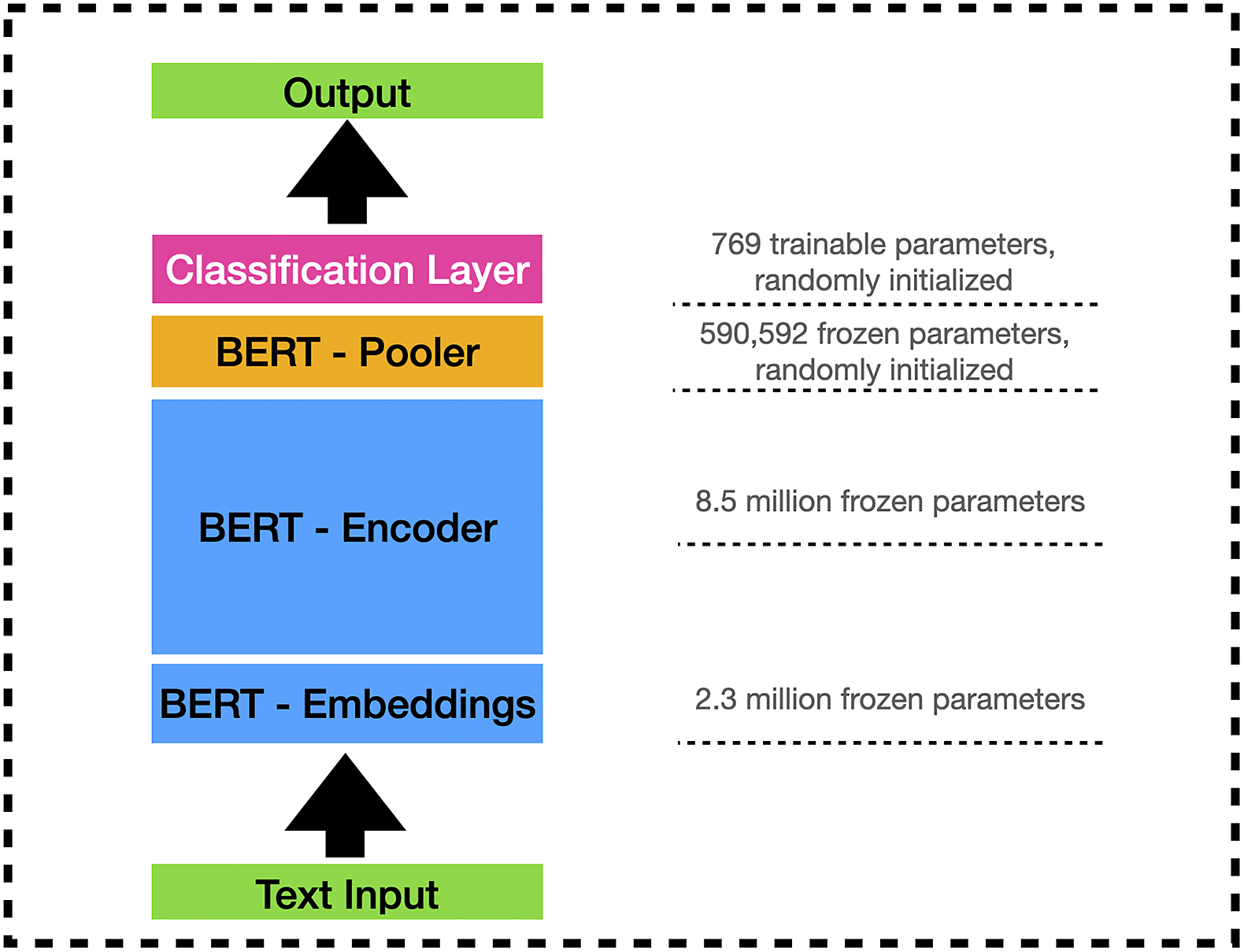
Figure 1 Illustration of the BERT model’s architecture. Numbers are based on Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) and Hu et al. (Reference Hu2022). Code for calculating the number of parameters is included in the replication package. Diagram is not drawn to proportion.
There are two observations with regard to training exclusively over the classification layer (pink box).Footnote 5 One is that this layer accounts for only a tiny portion (less than 0.1%) of the BERT model. As a result, this considerably limits the model’s expressive power. Another is that the pooler layer (yellow box), which has 0.6 million parameters, is not pretrained, but randomly initialized.Footnote 6 By freezing the pooler layer, we end up with 0.6 million randomly initialized parameters that are neither pretrained nor finetuned. Both observations contribute to limiting the performance of the finetuned BERT model.
2.2 Finetuning over All Parameters
In this subsection, we study the effects of making all the parameters trainable. We use the same setting as in Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023), except that we change the learning rate from 2e-3 to 2e-5 (Devlin et al. Reference Devlin, Chang, Lee, Toutanova, Burstein, Doran and Solorio2019). We need to lower the learning rate during finetuning to reflect the fact that most of the parameters are pretrained (Howard and Ruder Reference Howard and Ruder2018).Footnote 7 We also reduce the number of training epochs from 20 to 10, as it becomes clear that we do not need that many epochs. This is mostly to save computational costs. In Table 1, we compare the learning trajectories of finetuning only the classification layer as is done in Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) (left) and finetuning the entire BERT model (right). We observe that compared with finetuning only the classification layer, by finetuning the entire model, we are able to learn at a much faster pace and achieve a training loss and validation loss, both calculated in terms of mean squared error (MSE), that are considerably lower. As a matter of fact, by finetuning the classification layer only, we reach the lowest validation loss at 1.776 after training for 8,000 steps. By contrast, we can attain a validation loss of 1.229 after training for the first 500 steps once we allow the entire model to be finetuned.
Table 1 Metrics comparison between finetuning only the classification layer and finetuning the entire model. Due to space limit, we only report the first 5,000 steps. Interested readers could find all the training steps in the replication package.

2.3 Experimental Results
In this subsection, we report two groups of experimental results: one group, ConfliBERT Unrestricted, where we make all parameters trainable, and another group, ConfliBERT Max Length, where we not only make all parameters trainable but also increase the maximum sequence length from 256 (Häffner et al. Reference Häffner, Hofer, Nagl and Walterskirchen2023) to 512 (Wang Reference Wang2023b).Footnote 8 In Table 2, we compare the performance of these different models. OCoDi-Random Forest is the dictionary-based model that leverages random forest, where OCoDi stands for Objective Conflict Dictionary. OCoDi-XGBoost is the dictionary-based model that leverages XGBoost. ConfliBERT Restricted is the model from Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) where most parameters are excluded from finetuning.
Table 2 By making all parameters learnable, finetuned BERT models outperform dictionary-based models by a large margin. Results in columns 1–3 are from Table 2 in Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023). By increasing the maximum sequence length to 512, we are able to further improve the performance of those finetuned models. Best results in bold.

We observe that while OCoDi-Random Forest (column 1) and OCoDi-XGBoost (column 2) both achieve lower MSE and higher
 $R^2$
than ConfliBERT Restricted (column 3) where we finetune only the classification layer of ConfliBERT, once we finetune the entire ConfliBERT (column 4), we are able to achieve much lower MSE and higher
$R^2$
than ConfliBERT Restricted (column 3) where we finetune only the classification layer of ConfliBERT, once we finetune the entire ConfliBERT (column 4), we are able to achieve much lower MSE and higher
 $R^2$
than the dictionary-based approaches. Further, by increasing the maximum sequence length from 256 to 512, we observe that the MSE on the test set deceases from 0.99 to 0.87 and that the
$R^2$
than the dictionary-based approaches. Further, by increasing the maximum sequence length from 256 to 512, we observe that the MSE on the test set deceases from 0.99 to 0.87 and that the
 $R^2$
on the test set increases from 0.77 to 0.80 (column 5). Comparing OCoDi-XGBoost and ConfliBERT Max Length, we observe that ConfliBERT is able to achieve an MSE that is 46% lower than OCoDi-XGBoost and an
$R^2$
on the test set increases from 0.77 to 0.80 (column 5). Comparing OCoDi-XGBoost and ConfliBERT Max Length, we observe that ConfliBERT is able to achieve an MSE that is 46% lower than OCoDi-XGBoost and an
 $R^2$
that is 27% higher.
$R^2$
that is 27% higher.
In terms of computational costs, ConfliBERT Restricted takes 37 minutes to run on an A100 GPU, ConfliBERT Unrestricted (column 4) 50 minutes, and ConfliBERT Max Length (column 5) 98 minutes. While finetuning over all parameters takes some more time, we believe both models are well within the time budget for most researchers. Moreover, there are various ways to further speed up the training process, including, for example, using larger input batch sizes.Footnote 9
3 Conclusion
Häffner et al. (Reference Häffner, Hofer, Nagl and Walterskirchen2023) have made a significant contribution to the study of interpretable machine learning by developing a method for domain-specific dictionary creation and demonstrating its effectiveness and interpretability in conflict prediction. In this letter, we have discussed the architecture of BERT models and explained the limitations of finetuning only the classification layer. While the dictionary-based approaches are definitely easier to interpret, we have shown that when fully finetuned, BERT models still outperform these dictionary-based approaches by a sizeable margin. Researchers interested in large language models, text classification, and text regression should find our results useful.
Acknowledgments
We thank the reviewers and the editor for their excellent comments and guidance, which substantially improved the paper.
Data Availability Statement
The replication materials are available in Wang (Reference Wang2023a) at https://doi.org/10.7910/DVN/7PCLRI.
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2023.36.




