


In the past few decades, it has become increasingly clear that any inquiry into the roots of psychopathology such as anxiety or depression, as well as other complex behaviors, requires accounting for possible interactions and correlations between genetic vulnerabilities and environmental factors. Historically, genetically informative models assumed that genetic and environmental influences on a particular trait were static across the population. But growing evidence points both to differential effects of the same environmental exposure across genotypes (gene-by-environment interaction) and to differential environmental exposures across genotypes (gene-by-environment correlation). Several methods have been proposed to model these more complex relationships, particularly within the context of twin and family studies (Eaves & Erkanli, Reference Eaves and Erkanli2003; Price & Jaffee, Reference Price and Jaffee2008; Purcell, Reference Purcell2002; Rathouz et al., Reference Rathouz, Van Hulle, Rodgers, Waldman and Lahey2008).
An important methodological consideration with the models proposed by ourselves and others in this recent literature is that these are full probability, non-linear structural equations models (SEM). As such, they are based on distributional assumptions, such as multivariate normality of latent genetic and latent environmental factors. In practice, many phenotypes of interest are not normally distributed. Data may be ordinal (e.g., behavior ratings of impulsivity), skewed (e.g., symptom counts of depression), or censored (e.g., age-of-onset). In contrast to recent work, classical twin and adoption study data analysis methods –– which do not posit any interaction effects –– rely on linear SEMs. Whereas normality may be a useful working assumption in these models, valid inferences are often based only on assumptions about the first two moments (mean, variance, and covariance) of the data. Violations of normality have a negligible effect on parameter estimates in such models, and methods are available to adjust standard errors for bias due to non-normality. In the presence of gene-by-environment interactions, however, because they involve the product or square of latent normal quantities, the manifest variables will be non-normal by construction. Alternatively, when the latent factors are normal and do not interact, but the latent errors or measurement errors are non-normal, the manifest variables will also be non-normal. Therefore, when the scale of measurement of the variable(s) of interest is inherently non-normal, it is questionable as to whether the data can distinguish between these two fundamentally different scenarios. The issue of robustness of current GxM analysis methods to violation of distributional assumptions is therefore critical to behavior genetic designs being used in investigations of psychopathology, in particular where many phenotypes are measured with highly skewed distributions (e.g., symptom counts), and requires thorough exploration before any of these methods can be reliably used in such studies.
The goal of the current article is to explore the existence and severity of consequences of such violations of distributional assumptions on statistical tests and estimators. We consider bivariate behavior genetic designs involving a measured environment M and its potential moderating effects (GxM) on variance components impacting on a phenotype of interest P. The models allow for correlation between M and variance components of P (rGM). The specific question is whether, in the context of the set of models laid out in Purcell (Reference Purcell2002) and Rathouz et al. (Reference Rathouz, Van Hulle, Rodgers, Waldman and Lahey2008), the data are able to distinguish between non-normality in manifest variables due to GxM versus that due to measurement properties of the phenotype.
In our previous work (Van Hulle et al., Reference Van Hulle, Lahey and Rathouz2013), we evaluated the Type I error rates, power, and performance of the BIC for testing and comparing a subset of the models proposed in Rathouz et al. (Reference Rathouz, Van Hulle, Rodgers, Waldman and Lahey2008), equations for which are shown in Table 1. In that article, data were simulated under a variety of conditions both with and without GxM interactions. To briefly summarize, we found that: (1) when comparing the Cholesky with GxM model with the various submodels, the false positive rates consistently fell short of the nominal Type I error rates (α = 0.10, 0.05, 0.01); (2) with larger sample sizes (N = 2,000), in nearly all cases the correct model had the lowest BIC value across all possible models; (3) with lower sample sizes (N = 500), models specifying non-linear main effects were more difficult to distinguish from models containing interaction effects. In that paper, all simulated latent quantities and error variables were normally distributed, thus matching the distributional assumptions of the models. For the current study, we examined Type I error rates and performance of the BIC for nested and non-nested models under similar data generating mechanisms (DGMs) as in Van Hulle et al. (Reference Van Hulle, Lahey and Rathouz2013), but where violations of normality in the measurement process were imposed on either the moderator (M) or the phenotype (P).
TABLE 1 Bivariate Variance Components Models for Latent Component-by-Measured Environment (GxM) Interaction

P refers to a phenotype of interest, M refers to a putative moderator, a, c, and e refer to additive genetic, shared environment, and non-shared environment influences respectively, and μ is the mean. A, C, and E are standard normal latent variables. The subscript ‘C’ refers to factors that affect both M and P, and the subscript ‘U’ refers to factors that are unique to P.
ashown here for the putative moderator.
Methods
Model Specification and Data Generation
For the purposes of the current study, M refers to a putative moderator and P to an outcome of interest. We chose M rather than E to highlight that the moderator may not be strictly environmental in nature. GxM refers to generic interaction effects that encompass interactions between the moderator and latent additive genetic (A) or latent shared (C) or non-shared (E) environmental influences. We refer in the same generic sense to correlations between A, C, or E, and the moderator as rGM. Further details on notation and interpretation are given in Van Hulle et al. (Reference Van Hulle, Lahey and Rathouz2013).
Jointly, the classical twin model and the bivariate Cholesky model, (1) and (2) respectively in Table 1, allow for rGM in the form of genetic (aC), shared (cC), and non-shared (eC) environmental influences common to M and P (denoted here by the subscript ‘C’). Corresponding influences unique to P (denoted by the subscript ‘U’) are given by a U, c U, and e U in (2). The remaining models are variations on (2) that together with (1) allow for both rGM and GxM. Model (3) is the ‘Cholesky GxM’ model proposed by Purcell (Reference Purcell2002), and model (4) is a special case of (3) proposed by Rathouz et al. (Reference Rathouz, Van Hulle, Rodgers, Waldman and Lahey2008) that replaces the common effects on P with direct (or ‘main’) effects of M on P. The remaining two are: a non-linear main effects model that drops GxM in the unique influences on P (4*), and a model that further drops the non-linear effect of M on P (4†).
To address the aims of this study, data were simulated for M under the classical twin model (1) and for P under models (2), (3), (4), (4*), and (4†). We simulated data using code written in Stata 12.1 (StataCorp, 2011) under the multiple specifications for each model shown in Table 2. To introduce violations of distributional assumptions, we either censored or ordinalized the manifest measures M or P. For censoring, scores in the bottom 30% of the distribution were given the value of the 30th percentile (e.g., -0.6 in Figure 1) to simulate a floor effect. For ordinalizing, the data were assigned a score from 0 to 5, with the bottom 30% assigned a score of 0, the top 2% assigned a score of 5, and the remaining data evenly distributed between scores of 2, 3, and 4 (see Figure 1). For each DGM in Table 2, non-normality was imposed on either M or P (but not both simultaneously) resulting in a total of 44 distinct DGMs. Note that for DGMs where P contained interaction effects and non-normality was imposed on M, P was generated after M was censored or ordinalized. We wanted to approximate a situation where the underlying mechanisms giving rise to the phenotype of interest were truly non-normal in nature.
TABLE 2 Models and Data Generation Mechanism (DGM) Parameter Values used in Data Simulation

DGM = data generating mechanism. DGM numbers correspond to model numbers in Table 1, with A–D enumerating specific simulation conditions. For all simulation conditions,
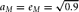 $a_M = e_M = \sqrt {0.9} $
,
$a_M = e_M = \sqrt {0.9} $
,
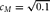 $c_M = \sqrt {0.1} $
, and
$c_M = \sqrt {0.1} $
, and
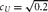 $c_U = \sqrt {0.2} $
; for DGMs 3A-D, interaction between shared environment and the moderator κC = κU = 0.01 and main effect of shared environment common to M and P, cC
= 0.01; for DGM's 4A-B interaction between the shared environment and the moderator, κU = 0.01.
$c_U = \sqrt {0.2} $
; for DGMs 3A-D, interaction between shared environment and the moderator κC = κU = 0.01 and main effect of shared environment common to M and P, cC
= 0.01; for DGM's 4A-B interaction between the shared environment and the moderator, κU = 0.01.

FIGURE 1 Example of distribution of simulated data after ordinalizing (left panel) or censoring (right panel). Data were ordinalized by grouping the top 2%, the bottom 30%, and evenly dividing the remaining scores. Data were censored by replacing scores in the bottom 30% with the value of the 30th percentile.
Note: For left panel M = 1.8, SD = 1.6, Skew = 0.2, Kurtosis = -1.3; for right panel M = 0.4, SD = 1.2, Skew = 1.6, Kurtosis = 3.2.
Data were simulated such that a high gene-moderator correlation (r AM) was paired with low environment moderator correlation (r EM) and vice versa, and a high gene-by-moderator interaction (AxM) was paired with low environment-by-moderator interaction (ExM) and vice versa, with the exception of DGM (4). For DGMs that included r AM, high correlations were set at 0.5 and low correlations were set at 0.1, with the same values assigned to high and low r EM. For DGM (3), high AxM was defined as interactions with the common (α C ) and unique (α U ) influences on P set to one half of the main effect of common (α C ) and unique (α U ) genetic influences on P. Low AxM was defined as one quarter of the main effect of common or unique genetic influences. Doing so ensured that the effect of AM or AU on P would be either absent (high AxM) or reduced by half (low AxM) when M is two standard deviations below its mean. An analogous definition was used to specify high and low ExM (ɛC, ɛU). Similarly, for DGMs (4) and (4*), the quadratic main effect of M on P (β 2 ), was set such that the effect of M on P was absent (large) or reduced by half (small) when M was two standard deviations below its mean. Note that for simplification, shared environment correlations and interactions with M, cC, κC, and κU, were set to 0.01 where applicable and were not considered further. All values are collected and presented in Table 2.
For each of the 44 scenarios, we simulated sample sizes of n = 1,000 pairs (500 each of MZ and DZ pairs). All simulations were performed with 2,000 replicates.
Data Analysis
We used the structural equation modeling software Mplus 6.1 (Muthén & Muthén, Reference Muthén and Muthén2011) to fit the models (2), (3), (4), (4*), and (4†) to each set of replicates. In our analysis, we treated ordinal and censored data as continuous because the integration algorithm needed to calculate the log-likelihood, is not available for categorical or censored data in Mplus and because treating the data as continuous reflects the lack of concordance between the data generation and the modeling assumptions. We calculated the empirical Type I error rates for nominal rates of 0.1, 0.05, and 0.01 for nested models. These analyses evaluate the ability of the maximum likelihood statistical procedure to detect when non-linear (latent or manifest) model terms are needed. GxM interactions were tested by comparing the Cholesky with GxM model (3) to the non-linear main effects with GxM model (4), and to the non-linear main effects only model (4*) and the classical bivariate Cholesky (2). The non-linear main effects with GxM model (4) was compared to the non-linear main effects only model (4*). Finally, the non-linear main effects model (4*) and the Cholesky (2) were compared to a linear effects only model (i.e., β 2 = 0). We also empirically assessed the degree to which BIC could differentiate nested or non-nested models when neither model reflected the true DGM. A BIC difference of 10 corresponds to a Bayesian odds of 150:1 that the model with the more negative value is the better fitting model (Raftery, Reference Raftery1995). Thus, a difference of 10 should be considered ‘very strong’ evidence in favor of the model with the more negative value. We computed the difference in BIC for each pair of models and indicate how often one model was chosen over the other. We interpreted BIC differences between -10 and 10 as indicating that the models were equivocal (i.e., described the data equally well). For each DGM, we determined the best model among all the alternatives according to lowest BIC, allowing us to see how often the correct model was chosen and, when it was not, which other models were chosen.
Results
Type I Error Rate for Comparing Nested Models
For each hypothesis test, when data were generated under the null model, we present the empirical (i.e., simulated) Type I error rates for nominal rates of 0.1, 0.05, and 0.01 in Tables 3 (ordinalized) and 4 (censored). The first column lists the alternative model, HA, and the second column lists the null model used to generate the data, H0. For example, the first row in Table 3 indicates that when data are generated under the non-linear main effects model (4) with large β2 and M is ordinalized, the number of false positives (4.9%) is about half the expected rate for alpha = 0.10 when comparing the Cholesky with GxM model (3) to non-linear main effects with GxM model (4). In general, when M is ordinalized the Type I error rates, though not perfect, are close to or lower than the nominal values and in line with the results reported in Van Hulle et al. (Reference Van Hulle, Lahey and Rathouz2013). Tests of the common GxM influences (model (4) vs. model (3), for example, were underpowered. Tests of the unique GxM influences (e.g., model (4*) vs. model (4) or the non-linear main effect (model (4*) vs. model (4†)) were well calibrated. When P is ordinalized, the error rates tend to be lower than expected (in keeping with our earlier findings) when comparing two models with interaction effects (e.g., (3) vs. (4)), However, empirical Type I error rates are higher than expected when the true model does not contain GxM (or GxM was weak) but the alternative model does. That is, when GxM is present, the LRT is underpowered. However, in the absence of true GxM, non-normality in the phenotype P is mistaken for interaction effects. We found similar results when M or P are censored (Table 5). The empirical Type I error rates are lower than expected when M is censored but generally in keeping with our earlier findings with normally distributed data. A notable exception occurred when comparing the Cholesky GxM model (3) with the Cholesky model (2) when M is censored. In this case, Type I error rates were much higher than expected. We cannot at this time fully explain this discrepancy. When P is censored, the true model is overwhelmingly rejected in favor of a model containing GxM in cases where DGMs had weak or no GxM effects. When β2 in model (4) was large, the magnitude of the non-linear main effect overwhelmed the violation of assumptions and led to good performance in the Type I error rates.
TABLE 3 Ordinalized Data Simulation: Percent of Simulated LRT Statistics under the Null Hypothesis Exceeding Critical Value for Pairs of Nested Models Based on 2,000 Replicates of n = 1,000

P refers to a phenotype of interest, M refers to a putative moderator. LRT refers to the likelihood ratio test.
aDGM does not contain GxM effects.
TABLE 4 Censored Data Simulation: Percent of LRT Statistics under the Null Hypothesis Exceeding Critical Value for Pairs of Nested Models Based on 2,000 Replicates of n = 1,000

P refers to a phenotype of interest, M refers to a putative moderator. LRT refers to the likelihood ratio test.
aDGM does not contain GxM effects.
TABLE 5 Ordinalized Data Simulation: Percent Each Model is Favored Via Comparison of BIC valuesa for All Pairwise Comparisons, and Percent Each Model has Lowest BIC: n = 1,000

P refers to a phenotype of interest, M refers to a putative moderator. Bold type indicates the correct model.
aabsolute BIC difference >10
bPercentage of replicates for which indicated model has minimum BIC across models (2), (3), (4), and (4*).
As shown in Figure 1, we imposed rather severe deviations from normality on the data. To see if LRT improved with less severe deviations from normality we simulated data (2,000 replicates) under models (2) and (4†) without GxM. We again imposed two types of non-normality on P: censored (bottom 10% and top 5%) and ordinalized, such that distribution of P was roughly bell-shaped with scores divided into groups of size 12%, 20%, 30%, 20%, 10%, and 8% and assigned a value from 0 to 5 (see Supplementary Figure 1). Type I error rates were reduced modestly (by 2–4%) when P was ordinalized, but the empirical error rates were still higher than expected. When we imposed a less severe censoring scheme on P, the empirical error rates were reduced dramatically (see Supplementary Table 1) and were generally in line with the empirical error rates reported in our paper on normally distributed data (Van Hulle et al., Reference Van Hulle, Lahey and Rathouz2013).
BIC for General Model Comparison
The BIC is often used to choose one best fitting among two or more nested or non-nested models. It imposes a greater penalty on complexity than the likelihood ratio test. We generated data under a variety of models (2), (3), (4), and (4*), and calculated the BIC difference for every pairwise model comparison, nested and non-nested. For each pair of model comparisons, the percentage of replicates for which BIC differences indicated that one model is favored over the other is given in Tables 5 (ordinal data) and 6 (censored data). The results largely mirror the LRTs. That is, when the data are ordinalized the correct model (or the model that most closely approximates the correct model) is favored over the incorrect model the majority of the time and the correct model nearly always has the lowest BIC among the five alternatives, with one notable exception. When data are generated under the Cholesky with GxM model (3), the non-linear main effects with GxM (4) is equivocal to or preferred over the true model (3) in the majority of cases, regardless of whether M or P was ordinalized. In many cases (38–95%), model (4) has the lowest BIC among the five alternatives. When P is censored (Table 6), models that include GxM are preferred to models that do not, even when the DGM does not include GxM, such as models (2) and (4*). For instance, when P is censored and the DGM is the non-linear main effects model (4*), a model with GxM effects is preferred over the true model in a majority of replicates. In fact, model (4) had the lowest BIC in 80–100% of replicates when the DGM was model (4*). As with ordinalized data, non-linear main effects with GxM model (4) is consistently preferred over or equivocal to the Cholesky GxM model (3) when data were generated under the latter. In our previous work we showed that with smaller samples sizes, it is difficult to detect significant differences among αC, κC, and ɛC and we replicated that finding here with data distributions that deviate from normality.
TABLE 6 Censored Data Simulation: Percent Each Model is Favored via Comparison of BIC Valuesa for All Pairwise Comparisons, and Percent Each Model has Lowest BIC: n = 1,000

P refers to a phenotype of interest, M refers to a putative moderator. Bold type indicates the correct model; italics indicates AxM or ExM detected when it does not hold (i.e., DGM is Chol or NLMain).
aabsolute BIC difference >10.
bPercentage of replicates for which indicated model has minimum BIC across models (2), (3), (4), and (4*).
Discussion
Our goal was to follow up our earlier work, describing the operating characteristics of alternative models testing for GxM by extending that work to some commonly occurring deviations from normality. In our previous work, we showed that deviations from expected Type I error rates were mild to moderate. In this study, we show that when data fail to meet distributional assumptions, deviations from expected Type I error rates are unpredictable and in some cases quite extreme.
In general, violations of normality in the moderator M have little impact on the operating characteristics of the models. Tests of non-linear main effects versus common GxM are somewhat underpowered, whereas tests of unique GxM or non-linear main effects are calibrated as expected, in keeping with our earlier work. In contrast, when the ultimate phenotype P violates assumptions of normality, GxM may be detected when it does not exist. In addition, it is difficult to distinguish among GxM interactions that involve latent factors that are common to the putative moderator M and outcome variable P when the data are non-normally distributed. In cases where P was ordinalized, tests of GxM were underpowered when the data generating model and alternative models both contained unique GxM and/or strong non-linear main effects. The true model was rejected in favor of a model with GxM effects more often than expected when the data generating model lacked GxM effects or such effects were small. These issues were exacerbated when P was censored. Under the censoring scheme imposed here, the null model was rejected in favor of a model containing GxM effects or non-linear main effects the vast majority of the time, when the data generating model lacked or had only weak GxM effects or non-linear main effects.
These results were generally supported by BIC comparisons. BIC differences were largely in the expected direction when P was ordinalized. However, when P was censored, BIC tests led to favoring models with GxM or non-linear effects over those that do not, even when the true model does not include any GxM or non-linear effects. For instance, when the data were generated under the Cholesky with high r GM, and P was censored, the non-linear main effects with the GxM model had the lowest BIC value in 85% of replicates. Perhaps more troubling is the failure to detect GxM when it does exist. In particular, it was difficult to distinguish between moderation of the genetic and environmental influences common to M and P and non-linear main effects. This was true whether M or P were ordinalized or censored. However, when data were censored, common GxM effects were mistaken for non-linear main effects in the majority of replicates under most conditions. Unfortunately, these problems cannot be solved with transformation ‘to normality’ before analysis because such transformation may then serve to eliminate GxM should it actually exist.
This study shows that violations of normality, particularly in the phenotype of interest, result in problems in both distinguishing non-linearity from GxM and in detecting moderation of the common factors influencing both the moderator and the phenotype. Underlying GxM effects themselves may lead to mild deviations from normality in the phenotype. Therefore, researchers should interpret model fitting results with caution when the phenotypic data may deviate from distributional assumptions.
Acknowledgments
This study was funded by the NIH grant R21 MH086099 from the National Institute for Mental Health. Infrastructure support was provided by the Waisman Center via a core grant from the National Institute of Child Health and Human Development (P30 HD03352).
Supplementary Material
To view supplementary material for this article, please visit http://dx.doi.org/10.1017/thg.2014.81.









