
Contents
Research Article
On Generalized Networks of Queues with Positive and Negative Arrivals
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 301-334
-
- Article
- Export citation
G-Networks with Signals and Batch Removal
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 335-342
-
- Article
- Export citation
Regularity of Stochastic Processes: A Theory Based on Directional Convexity
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 343-360
-
- Article
- Export citation
Some Monotone Almost Balanced Knockout Tournament Plans
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 361-368
-
- Article
- Export citation
Optimal Occupation in the Complete Graph
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 369-385
-
- Article
- Export citation
Optimal Sampling for Identifying a Cluster: An Application in Sorting
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 387-407
-
- Article
- Export citation
A Note on Equivalence Classes of Directed Acyclic Independence Graphs
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 409-412
-
- Article
- Export citation
A Note on the Residual Entropy Function
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 413-420
-
- Article
- Export citation
Stochastic Comparison of Some Wear Processes
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 421-435
-
- Article
- Export citation
-
Let [NA(t), t≥0] and [NB(t), t≥0] be two counting processes with independent interarrivals Ai and Bi, respectively, i ∈
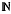 + ≡ [1,2,… ], and let [Xi, i ∈ +] and [Yi, i ∈ +] be two sequences of independent non-negative random variables. Consider the two compound processes [U(t), t ≥ 0] and [V(t), t ≥ 0] defined as U(t) =
+ ≡ [1,2,… ], and let [Xi, i ∈ +] and [Yi, i ∈ +] be two sequences of independent non-negative random variables. Consider the two compound processes [U(t), t ≥ 0] and [V(t), t ≥ 0] defined as U(t) = 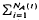 Xi, t ≥ 0, and V(t) =
Xi, t ≥ 0, and V(t) = 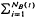 Yi, t ≥ 0. Then it is well known (and not hard to verify) that if the Ai's are independent of the Xi's, and if the Bi's are independent of the yi's, and if Ai ≥st Bi and Xi ≤st Yi, for all i ∈ +, then [U(t), t ≥ 0] ≤st [V(t), t ≥ 0]. In this paper we provide conditions under which this stochastic order relation holds even if Ai ≤st Bi and/or Xi ≥st Yi for all i ∈ +. In fact, we derive the stochastic order relationships among processes that are much more general than the cumulative ones described above. For example, it is not necessarily assumed that the Ai's are independent of the Xi's or that the Bi's are independent of the Yi's. Examples that illustrate the applications of the theory are included.
Yi, t ≥ 0. Then it is well known (and not hard to verify) that if the Ai's are independent of the Xi's, and if the Bi's are independent of the yi's, and if Ai ≥st Bi and Xi ≤st Yi, for all i ∈ +, then [U(t), t ≥ 0] ≤st [V(t), t ≥ 0]. In this paper we provide conditions under which this stochastic order relation holds even if Ai ≤st Bi and/or Xi ≥st Yi for all i ∈ +. In fact, we derive the stochastic order relationships among processes that are much more general than the cumulative ones described above. For example, it is not necessarily assumed that the Ai's are independent of the Xi's or that the Bi's are independent of the Yi's. Examples that illustrate the applications of the theory are included.
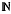
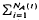
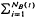
Preservation of Some Ageing Properties by Order Statistics
-
- Published online by Cambridge University Press:
- 27 July 2009, pp. 437-440
-
- Article
- Export citation
Back matter
PES volume 7 issue 3 Cover
-
- Published online by Cambridge University Press:
- 27 July 2009, p. b1
-
- Article
-
- You have access
- Export citation