1 INTRODUCTION
In numerous studies, language has been shown to vary according to a number of extralinguistic factors such as the age (Sankoff & Blondeau Reference Sankoff and Blondeau2007; Labov, Rosenfelder & Fruehwald Reference Labov, Rosenfelder and Fruehwald2013) and regional origin of the speaker (Glaser Reference Glaser2013; Grieve, Speelman & Geeraerts Reference Grieve, Speelman and Geeraerts2013), among many others. From perception studies, on the other hand, we know that listeners draw upon linguistic variation to infer social information about the speaker. For instance, in experiments on dialect perception, listeners were able to localise – more or less precisely – the regional origin of a speaker (Purnell, Idsardi & Baugh Reference Purnell, Idsardi and Baugh1999; Clopper & Pisoni Reference Clopper and Pisoni2004), and listeners of American English ascribed different social attributes to a speaker depending on her/his realisation of the variable -ING in English (Campbell-Kibler Reference Campbell-Kibler2009).
In the present study we draw upon these findings to investigate if speakers of two particular dialectal areas of Spanish possess linguistic awareness of a sound change in progress. We will show that the manipulation of a fine-phonetic consonantal detail, the syllable-final /s/ either realised as aspiration preceding or following a voiceless stop, is able to shift the listeners’ judgements about the speaker’s age and region of origin. Our study demonstrates that listeners from both varieties possess detailed knowledge of the sound change, with which their explicit answers are only partly consistent.
2 /S/-ASPIRATION IN SPANISH
/s/-aspiration is probably the most studied phenomenon in Hispanic linguistics and refers to the lenition of syllable-final /s/ to [h] or to its complete elision (e.g. gatos ‘cats’ [ˈga.toh]). /s/-aspiration can be described as debuccalisation of the alveolar fricative and is not only wide-spread among Spanish varieties, but also occurs in other Romance languages (Solé Reference Solé2010). Lenition of syllable-final /s/ is considered to be one of the main linguistic features for a division of the Spanish-speaking world into dialect areas (Samper Padilla Reference Samper Padilla2011; Canfield Reference Canfield1981; Lipski Reference Lipski1994). A large number of variationist studies have found that syllable-final /s/ in Spanish varies according to demographic variables of the speaker, e.g. with social class (López Morales Reference López Morales1983) or gender (Fontanella de Weinberg Reference Fontanella de Weinberg1973) as well as with speech style (Lafford Reference Lafford1986). Given this geographic and sociolinguistic variation in the production of syllable-final /s/, it is perhaps not surprising that listeners use this variable to geographically and socially categorise a speaker (see Section 3).
2.1 /s/-aspiration in Andalusian Spanish
Andalusian Spanish is spoken in the most southern part of continental Spain, in Andalusia. The most important characteristics of Andalusian Spanish that separate it from the Northern Spanish varieties are phonetic/phonological, the most prominent one being the lenition of coda consonants – including /s/ – and seseo/ceceo. The latter refers to the pronunciation of standard Spanish /s/ and /θ/ as [s] (seseo) or [θ] (ceceo), respectively, and is seen as being the result of a merger of the four medieval sibilants /ts/, /dz/, /z/, and /s/ by deaffrication and devoicing (Penny Reference Penny2000). Although many Andalusian features can be found all over Andalusia and beyond, a division into Eastern and Western Andalusian varieties according to phonetic/phonological, morphological, and lexical features is possible (Mondéjar Reference Mondéjar1991). In Eastern varieties, vowels preceding a lenited /s/ are generally lowered, or fronted in the case of /a/ (e.g. patos ‘ducks’ [ˈpa.tɔh]), a phenomenon which is often associated with vowel harmony (e.g. los monos ‘the monkeys’ [lɔ ˈmɔ.nɔ]; Narbona, Cano & Morillo Reference Narbona, Cano and Morillo2003; Henriksen Reference Henriksen2017). Ceceo and seseo occur in both Eastern and Western varieties, but in the last decades, Eastern varieties have been shown to converge towards standard Spanish and therefore to increasingly distinguish between /s/ and /θ/ (distinción; Moya Corral & García Wiedemann Reference Moya Corral and García Wiedemann1995; Villena Ponsoda et al. Reference Villena, Andrés, Sánchez Sáez and Ávila Muñoz1995; Moreno Reference Melguizo Moreno2007). This tendency seems to be less marked for Western varieties (Villena Ponsoda Reference Villena Ponsoda2008, but see García-Amaya; Regan Reference Regan2017 for findings on Jerez de la Frontera and Huelva Spanish). /s/-lenition to [h] or [∅] is very wide-spread in Andalusia, and in Seville (Western Andalusia) even used in formal situations by speakers with a university degree (Carbonero Cano Reference Carbonero Cano1982). In Granada (Eastern Andalusia), older speakers with a high education degree seem to favour the full alveolar fricative [s] in certain contexts (Tejada Giráldez Reference Tejada Giráldez2015).
This shows that Eastern and Western Andalusian Spanish not only differ according to linguistic, but also according to their sociolinguistic status and the orientation of speakers towards the northern, as opposed to the regional, southern norm. “The urban variety of Seville (norma sevillana) is accepted as a model of pronunciation for western varieties, but this regional trend of prestige does not reach eastern varieties” (Villena Ponsoda Reference Villena Ponsoda2008:144), which are instead oriented towards the northern norm. Given their different sociolinguistic status, eastern varieties seem to converge towards the northern standard, but at the same time conserve socially unmarked southern features, including the lenition of syllable-final consonants (Villena Ponsoda Reference Villena Ponsoda2008; Hernández-Campoy & Villena-Ponsoda Reference Hernández-Campoy and Villena-Ponsoda2009; Moya Corral et al. Reference Moya Corral, Montoro del Arco, Cruz, Sosinski, de la Sierra Tejada Giráldez, López, Furest and García2014; Villena Ponsoda & Vida Castro Reference Villena Ponsoda and Vida Castro2017). These different tendencies can be explained with demographic and structural differences between Eastern and Western Andalusia (Villena Ponsoda et al. Reference Villena Ponsoda, Corral, Muñoz and Castro2003). With Seville, Western Andalusia has a prominent cultural, social, and political centre, and the urban Seville variety (norma sevillana) has high prestige. In contrast, no equivalent centre exists in Eastern Andalusia. As mentioned above, recent research showed that tendencies towards the standard variety exist in Western Andalusia too. Jerez (García-Amaya Reference García-Amaya2008) and Huelva Spanish (Regan Reference Regan2017) strongly converge towards the northern norm by unmerging ceceo and adopting the northern norm, distinción. At a national level, Andalusian Spanish is generally considered to be a stigmatized variety (Snopenko Reference Snopenko2007), although this seems to have changed in the last decades as well (Gallego & Rodríguez Reference Gallego and Rodríguez2012; Turner Reference Turner2015).
Apart from vowel lowering mentioned above, phonetic consequences of /s/-lenition include the lengthening of following consonants (e.g. isla ‘island’ [ˈi(h).lːa]) (Alvar Reference Alvar1955; Mondéjar Reference Mondéjar1991). For /sp, st, sk/-sequences, the emergence of post-aspiration as a result of /s/-lenition has recently been documented for Western Andalusian varieties (Torreira Reference Torreira2007a; Torreira Reference Torreira2007b; Torreira Reference Torreira2012; O’Neill Reference O’Neill2010; Parrell Reference Parrell2012). In words such as resto ‘rest’, the aspiration resulting from /s/-lenition is increasingly realised as aspiration following ([ˈre.tho]; post-aspiration), instead of preceding the stop ([ˈreh.to]; pre-aspiration).
2.2 Sound change in /sp, st, sk/
The hypothesis of a sound change in progress from pre-aspiration to post-aspiration (e.g. [ˈreh.to] → [ˈre.tho]) was addressed in an apparent-time study (Ruch & Harrington Reference Ruch and Harrington2014; Ruch & Peters Reference Ruch and Peters2016). By analysing isolated words spoken by 24 speakers from Seville and 24 from Granada it was found that younger speakers (age range 20-36 years) produced a significantly longer post-aspiration than older speakers (age range 55-79 years) in words with intervocalic /sp, st, sk/ (e.g. pestaña ‘eyelash’ or espalda ‘back’). This apparent-time difference in post-aspiration duration was more marked among Seville than among Granada speakers. Pre-aspiration was shorter in younger than in older speakers, but did not significantly differ between Seville and Granada Spanish. Words with intervocalic /p, t, k/ (e.g. etapa ‘stage’, separa ‘to separate’, 3rd p. sg.), in contrast, were consistently produced with a short voice onset time (i.e. without post-aspiration) in both varieties.
Ruch & Harrington (Reference Ruch and Harrington2014) and Ruch & Peters (Reference Ruch and Peters2016) concluded that a sound change in which pre-aspiration is fading and post-aspiration is increasing gradually is taking place not only in Seville, but also in Granada Spanish. Their results are in line with O’Neill (Reference O’Neill2010) who observed that, from an areal point of view, post-aspiration in /sp, st, sk/ was successively increasing when moving from Western (Cádiz, Seville) to Eastern Andalusia (Granada, Jaén). Post-aspiration, a long stop closure, and affrication in the case of /st/ have further been documented for Malaga Spanish (Vida Castro Reference Vida Castro2004; Vida Castro Reference Vida Castro2015).
Taken together, these findings suggest that the sound change from pre- to post-aspiration in /sp, st, sk/-sequences first started in Western varieties and is now spreading from Western to Eastern Andalusian Spanish.
To date it remains unclear to what extent Sevillian and Granadian speakers are aware of this sound change. Our own informal observations during fieldwork suggest that some speakers have knowledge of the sound change in the dental context, where the stop release is sometimes affricated (e.g. [retso]; Moya Corral Reference Moya Corral2007; Ruch Reference Ruch2012). Chariatte (Reference Chariatte2015) reports on Malaga speakers’ comments regarding [ts], who claim this variant to be typical for Malaga Spanish. In a vivid discussion in a forum on WordReference.com, some users state this sound has originated in Seville, while others vehemently negate its existence: Lo siento, pero yo no he oído en mi vida ese sonido que comentas. ‘I am sorry, but in my life I have not heard the sound you mentioned.’
3 PHONETIC VARIATION AND INDEXICALITY
Indexical linguistic features can broadly be defined as those features of spoken language that vary with extra-linguistic factors. Together with other kinds of linguistic variation, phonetic variation is available to speakers for the construction of social identity (Eckert Reference Eckert2008; Foulkes, Scobbie & Watt Reference Foulkes, Scobbie and Watt2010).
As already mentioned, indexical variation is also used by listeners to geographically and socially situate a speaker. Recent work suggests that the indexical function of a linguistic variable is not stable, but may be interpreted in different ways depending on the social and the linguistic context in which it is heard. In Campbell-Kibler (Reference Campbell-Kibler2011) some phonological variables were found to consistently affect ratings across conditions, while others interacted with the specific linguistic context and the regional accent of the speaker. Levon (Reference Levon2007) showed that masculinity and sexuality ratings were affected when sibilant duration and pitch range were manipulated in a recording previously judged as gay-sounding. When embedded in a recording originally rated as straight-sounding, the manipulation of the same two variables did not affect the judgements. Podesva et al. (Reference Podesva, D’Onofrio, Hofwegen and Kim2015) found that ratings of American politicians were not only affected by the manipulated phonological variable (released or unreleased /t/), but also by a politician’s more general use of the phonetic variants and her/his identity. The indexicality of a linguistic variant is considered to be constantly constructed and re-constructed by speakers and listeners in interaction and accordingly can acquire different meanings when used and heard in new contexts (Eckert Reference Eckert2008).
To contextualise the present experiment, the focus of the following literature review falls on perception of regional origin in Spanish, and on age perception more generally.
3.1 Perception of a Speaker’s Regional Origin in Spanish
Several studies have investigated attitudes towards different Spanish varieties (e.g. Alfaraz Reference Alfaraz2014; Chiquito & Pacheco Reference Chiquito and Pacheco2014) or lay persons’ mental representations of dialect regions. Moreno Fernández & Moreno Fernández (Reference Moreno Fernández and Moreno Fernández2002) asked residents in Madrid how differently they think people speak in different areas of Spain. Andalusian – together with Canarian, Extremeño and Murcian, all of them varieties spoken in southern Spain – were considered to be the most different. All of these varieties present /s/-lenition, which is probably crucial for their status as “different” from the perspective of Madrid speakers.
Research on the contribution of specific linguistic features to the recognition of Spanish dialects is more scarce. Boomershine (Reference Boomershine2006) tested how listeners of Puerto Rican and Mexican Spanish identified a stimulus containing syllable-final /r/, syllable-final /s/ or word-final /n/ as belonging to their own or another dialect. The participants of both dialects were most accurate in dialect categorisation when the stimulus contained syllable-final /s/.
The social interpretation of linguistic variation is not always in line with the actual distribution of variants in speech production, but can be influenced by stereotypes and linguistic ideologies. Delforge (Reference Delforge2012) showed how participants from Cusco associated vowel devoicing with rural Peruvian and not with Cusco Spanish, although only a few generations ago vowel devoicing was still common in Cusco Spanish. Babel (Reference Babel2014) describes for Bolivian Spanish how beliefs about different phonetic forms of the discourse marker pues – [ps] as typical for highlanders, [pweh] as typical for lowlanders – may diverge substantially from the actual distribution of these variants in production.
Walker et al. (Reference Walker, García, Cortés and Campbell-Kibler2014) used cross-spliced stimuli to test how syllable-final /s/ produced as either [s] or [h] affects how a speaker is evaluated socially, and how social evaluations vary according to the dialect of the listener – Puerto Rican or Mexican Spanish. In Puerto Rican Spanish, /s/-weakening is very common; in non-coastal Mexican Spanish, on the contrary, [s] is the most frequent and socially more prestigious variant. Although the direction of the answers was the same for the two listener groups, interactions between the speaker’s and the listener’s origin suggested that listeners consider the regional origin of the speaker when rating a phonetic variant according to its social status.
The reviewed literature underlines the important role of syllable-final /s/ as a social-indexical variable in Spanish. All these studies, however, deal with variants of /s/ – full alveolar fricative [s] vs. lenited /s/ ([h] or [∅]). In the present experiment for the first time more fine-grained variation of /s/-lenition, namely pre- and post-aspirated stops, will be used.
3.2 Perception of Speaker Age Cross-Linguistically
Listeners have been shown to quite accurately estimate a speaker’s age from the acoustic signal (for reviews, see Nagao Reference Nagao2006; Moyse Reference Moyse2014). Given that participants were less accurate in backward than in forward played samples (Ptacek & Sander Reference Ptacek and Sander1966), it is clear that voice characteristics alone do not suffice to accurately pinpoint the age of a speaker. Apart from voice characteristics, a phonetic cue to speaker age is segment duration due to a generally slower articulation rate in elderly speakers (Harnsberger et al. Reference Harnsberger, Rahul Shrivastav, Brown, Rothman and Hollien2008).
Further potential sources of phonetic differences between older and younger persons are age-grading (Wagner Reference Wagner2012), a change in linguistic ideologies, and sound change. Changing linguistic ideologies may result in apparent-time differences, for instance, when certain forms have been “enregistered” to signal place identity (Johnstone, Andrus & Danielson Reference Johnstone, Andrus and Danielson2006) or social class (Delforge Reference Delforge2012) and, as a result, are more or less often used by younger speakers. Completed or on-going sound change, finally, may also result in phonetic differences between older and younger speakers (Bailey et al. Reference Bailey, Wikle, Tillery and Sand1991; Labov Reference Labov2001).
Very few studies have used age perception to assess the question of whether a sound change in progress is being noticed by listeners. Walker (Reference Walker2007) showed that the manipulation of the MOUTH diphthong and word-final /t/ is able to shift the listeners’ perceptions of age and social class of a speaker. Hay, Warren & Drager (Reference Hay, Warren and Drager2006) found that in a merger-in-progress in New Zealand English the category-boundary between the two vowels that were merged for younger, but not for older speakers, was shifted as a function of perceived speaker age. Similar effects were found by Koops, Gentry & Pantos (Reference Koops, Gentry and Pantos2008) using eye-tracking, and by Drager (Reference Drager2010) for vowels currently undergoing a chain shift.
Taken together, these studies provide evidence that listeners have knowledge of apparent-time differences occurring in their own variety, and that they use this knowledge in social and in speech perception.
3.3 Aims and Hypotheses
The present study asks whether speakers of Andalusian Spanish possess knowledge of the age-specific and regional variation occurring in their variety. More specifically, we test if the realisation of /s/+voiceless stop as post-aspirated stop [Ch] shifts a listener’s age judgement of the speaker towards younger and towards Sevillian. This is done by manipulating natural stimuli coming from younger and older speakers from Granada and Seville. We manipulated the phonetic variant of /s/ + voiceless stop without changing the many other cues in the speech signal potentially indicating a speaker’s age and regional origin. This procedure will allow to investigate how the context (i.e. a younger or an older voice; a Sevillian or a Granadian sounding speaker) interacts with the phonetic variant.
If native speakers of Granada and Seville Spanish possess knowledge of the age- and dialect-specific distribution of pre- and post-aspirated stops, they are expected to associate these phonetic variants with the respective speaker groups. This is tested by asking listeners of Andalusian Spanish to rate the regional accent and estimate the age of the speaker for each stimulus on a visual anologue scale. The following hypotheses will be tested:
H1: In a stimulus with a post-aspirated stop, the speaker will be rated as having a more Sevillian-like accent than in a stimulus that contains a pre-aspirated stop.
H2: If a stimulus contains a post-aspirated stop, the speaker will be estimated as being younger than when the stimulus contains a pre-aspirated stop.
As listeners seem to be sensitive to linguistic features that differ from their own dialect (Siegel Reference Siegel2010: 62) it is expected that Granada listeners are more sensitive to the post-aspirated variants and that their answers are shifted to a greater extent towards “Sevillian”. Andalusians who live in Seville can be assumed to be more frequently exposed to Seville speech – where the age-dependent differences in post-aspiration duration are more marked – and are therefore hypothesised to be more sensitive to these differences than listeners who live in Granada. These assumptions are phrased in Hypotheses 3 and 4:
H3: The effect of phonetic variant on dialect perception is greater for Granada than for Seville listeners
H4: The effect of phonetic variant on age perception is greater for Seville than for Granada listeners
Further analyses will be carried out to investigate how the effect of phonetic variant interacts with the other cues to regional origin and age that are present in the acoustic signal.
4 METHOD
4.1 Stimuli
Isolated words were used to create the audio stimuli. These words had been recorded as part of a production corpus and contained /s/ + voiceless stop sequences in intervocalic position (e.g. espanto, estanco, pescado; for details, see Ruch & Harrington Reference Ruch and Harrington2014; Ruch & Peters Reference Ruch and Peters2016). To facilitate the acoustic manipulation of pre- and post-aspiration duration for the present study, 34 tokens that contained both pre- and post-aspiration (e.g. espada [eh.ˈpha.ða]) were selected from the production corpus mentioned above.
Duration manipulation was achieved with PSOLA in Praat (Boersma & Weenink Reference Boersma and Weenink2013) using the Akustyk plugin (Plichta Reference Plichta2012). The 34 selected baseline tokens came from 24 different speakers who were either young (between 20 and 36 years old) or old (older than 55 years), and either from Seville or from Granada. The baseline tokens thus naturally contained other acoustic cues to the regional origin (e.g. vowel quality) and the age of the speaker (e.g. fundamental frequency or voice quality). Importantly, only the duration of pre- and post-aspiration and the duration of the oral stop closure were manipulated to obtain two variants from each basis token.
To generate the pre-aspirated variant, pre-aspiration duration was extended to ca. 15 ms for /sp/ and to 40 ms for /sk/, and post-aspiration was shortened to ca. 20 ms. After lengthening pre-aspiration and shortening post-aspiration, the stop closure was lengthened in such a way that the total duration of the /s/ + stop sequence was the same as in the originally produced token. This is important because total /sC/-duration has been found to be very similar across age groups in Granada and Seville Spanish, independently from the duration of pre- and post-aspiration (Ruch & Peters Reference Ruch and Peters2016). The post-aspirated variant was generated by shortening the pre-aspiration to 0, extending the post-aspiration to 50-60 ms (longer for velar, and shorter for bilabial stops; see Appendix 1 for details), and, again, lengthening the closure duration in such a way that the total /sC/-duration was the same as in the basis token.
This procedure was repeated for each of the 34 basis tokens to generate a total of 34 stimuli pairs. Fig. 1 displays the waveform and spectrogram of a stimulus pair. The newly generated stimuli were then amplified to 60 dB (using exactly the same factor for both stimuli of a pair). A native speaker of Seville Spanish who used to live in Granada for several years checked the stimuli for naturalness.
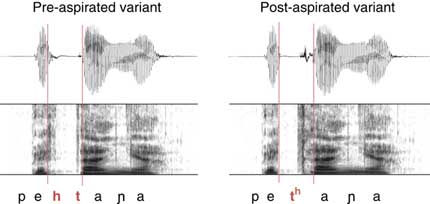
Figure 1 Waveform and spectrogram of a stimulus pair that has been generated by reducing post-aspiration duration and lengthening pre-aspiration (left), and reducing pre-aspiration and lengthening post-aspiration (right). The example comes from a 71 year old female speaker who grew up in Seville.
To make sure that the two stimuli of a pair were perceptually distinct enough, an ABX perception test was conducted using the online tool Percy (Draxler Reference Draxler2011). 16 listeners of Andalusian Spanish (age range: 27-38 years) decided whether the third stimulus within a triplet (X) was more similar to the first (A) or to the second (B). The stimuli of a pair were presented once in each possible combination (ABB, BAB, BAA, ABA). The proportion of correct answers ranged from 0.48 to 0.90. For the perception experiment only the 18 stimuli pairs with a value above 0.66 were used. The details on the acoustics of the selected stimuli are summarised in Appendix 1.
In addition to the 18 selected stimuli pairs, 19 fillers were chosen from the same production corpus. Fillers were isolated words, each produced by a different speaker, either a younger or an older person from Granada or Seville, and did not contain any /s/+voiceless stop sequence (e.g. etapa ‘stage’ [e.ˈta.pa], tienen ‘to have’, 3rd person sg., [ˈtje.nen]). The full list of fillers is included in Appendix 2. The intensity of the fillers was amplified to 60 dB, and fillers were duplicated to generate filler pairs. Table 1 contains a summary of the demographic data of the speakers of whom the stimuli and fillers had been selected.
Table 1 Demographic data of the speakers from whom the basis tokens for generation of the aspiration stimuli (left) and the fillers (right) were chosen.

4.2 Experiment
The 2 (phonetic variants)×18 (baseline tokens)=36 aspiration stimuli and the 2 (equal variants)×19 (baseline tokens)=38 fillers (74 stimuli coming from a total of 36 speakers) were embedded in a randomised order in an online perception experiment using Soscisurvey.de (Leiner Reference Leiner2013). The randomisation was organised in four blocks to make sure that the two stimuli of a pair never occurred one after another.
Each stimulus or filler was presented on one page together with its orthographic transcription (see Fig. 2), and participants could listen to the stimulus by clicking on “play” as many times as they wanted. They were asked to listen to the stimulus and then answer the questions “What accent do you think this person has? How old do you think he/she is?” by clicking on a visual analogue scale and moving the cursor freely to where they thought would fit best; between “Granadian” and “Sevillian” for the first, and between “young (20 years)” and “old (80 years)” for the second question.

Figure 2 Screenshot of the experiment. At the top of the page, the orthographic form (estanco) of the stimulus appears; at the bottom, the two visual analogue scales for accent and age ratings.
Demographic data were collected at the beginning of the experiment. After listening to the 74 audio files and estimating the speaker’s accent and age for each of them, participants were invited to answer questions about their strategies for recognising the age and origin of the speaker, and whether any of the speakers sounded familiar to them. The completion of the whole experiment took about 20 minutes and participants were paid for their time.
4.3 Participants
The listeners were recruited via acquaintances of the author through social media and word of mouth. 112 persons participated in the experiment. The data of 12 subjects were removed because they did not grow up in Granada/Seville or because at the time of the experiment they had been living outside the two cities for more than three years. The data of 17 further listeners was removed because they indicated having recognised one or several of the speakers. The remaining 83 listeners were aged between 16 and 72 (median: 29) years; 45 were female and 38 were male. Table 2 shows the distribution of the listeners according to region of origin and gender.
Table 2 Distribution of the listeners in the perception experiment according to demographic variables.

5 RESULTS
In 5.1 the effect of the phonetic variant on age and dialect perception is presented. In 5.2 additional analyses are presented to investigate how the phonetic variant interacts with the context in which it is occurs, i.e., the speaker’s voice and other phonetic cues to age and regional origin.
5.1 Effect of phonetic variant
Fig. 3 shows the density curves for the dialect answers according to the phonetic variant (pre- vs. post-aspirated) and a listener’s origin (Granada vs. Seville). The density curve displays for each range on the rating scale (x-axis) the likelihood (y-axis) that a listener put the cursor in this range when rating a stimulus. The bimodal distribution shows the tendency of the listeners towards the extremes of the scale, either more Sevillian or more Granadian-sounding. The fact that the dark and the light grey areas do not completely overlap indicates that dialect ratings were influenced by the phonetic variant: both listener groups were more likely to rate a stimulus as more Seville-sounding when it contained a post-aspirated stop, which is apparent from the higher density under the dark curve at the right edge of the plots.
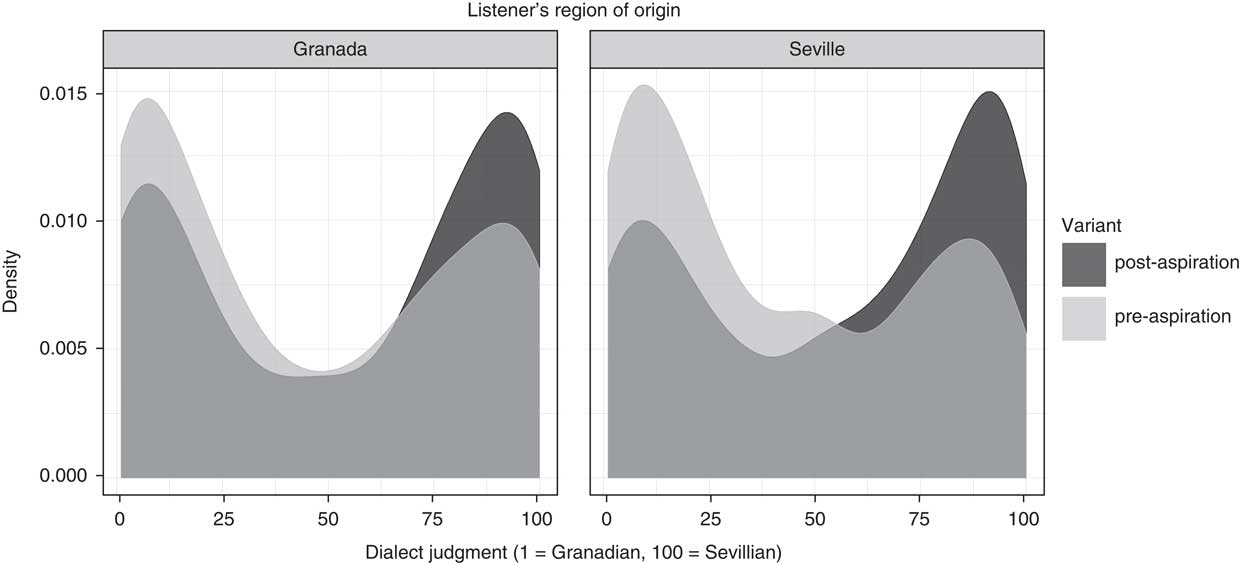
Figure 3 Density curves for the dialect ratings according to the phonetic variant (pre- vs. post-aspirated stop). Distributions are shown separately for Granada (left panel) and Seville listeners (right panel). Low values on the x-axis stand for “Granadian”, high values for “Sevillian” ratings.
For the statistics the data from Fig. 3 were averaged over listener (83 levels) and phonetic variant (two levels: pre-aspiration, post-aspiration), resulting in two mean values per listener. Fig. 4 shows the aggregated dialect ratings by Seville and Granada listeners to pre- and post-aspirated stimuli. A repeated measures ANOVA, with the listener’s dialect as a between-subjects factor and the phonetic variant as a within-subjects factor, confirmed the effect of phonetic variant (F[1,81]=45.7, p<0.001), but showed no effect of the listener’s dialect and no interaction between the two factors. The statistics therefore confirmed H1 that post-aspirated variants were rated as sounding more Seville-like. The effect of the phonetic variant did not differ between the two listener groups, thus contradicting H3 that Granada listeners would be more sensitive to the phonetic difference.
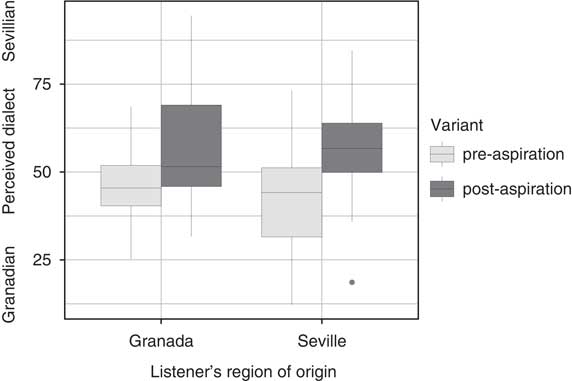
Figure 4 Boxplots showing the mean dialect rating per phonetic variant for each listener. Low values stand for a perceived Granadian accent, high values for a perceived Sevillian accent.
Fig. 5 shows the effect of phonetic variant (pre-/post-aspiration) on the perceived age for Granada and Seville listeners. For both listener groups age judgements are slightly left-shifted when the stimulus contains a post-aspirated stop, as compared to stimuli with a pre-aspirated stop. This effect seems to be more marked for Seville than for Granada listeners. Fig. 6 visualises the averaged age ratings for each phonetic variant and each listener. A repeated measures ANOVA, with the averaged age ratings as the dependent variable, a listener’s dialect as between-subjects factor and phonetic variant as a within-subject factor, showed a significant effect of phonetic variant (F[1,81]=76.0, p<0.001) on the perceived speaker age, a significant interaction between a listener’s dialect and phonetic variant (F[1,81]=4.4, p<0.05), but no effect of a listener’s dialect. The test therefore confirmed H2 stating that speakers are estimated as being younger when the stimulus contained a post-aspirated stop, and H4 predicting that this effect would be more marked for Seville than for Granada listeners.
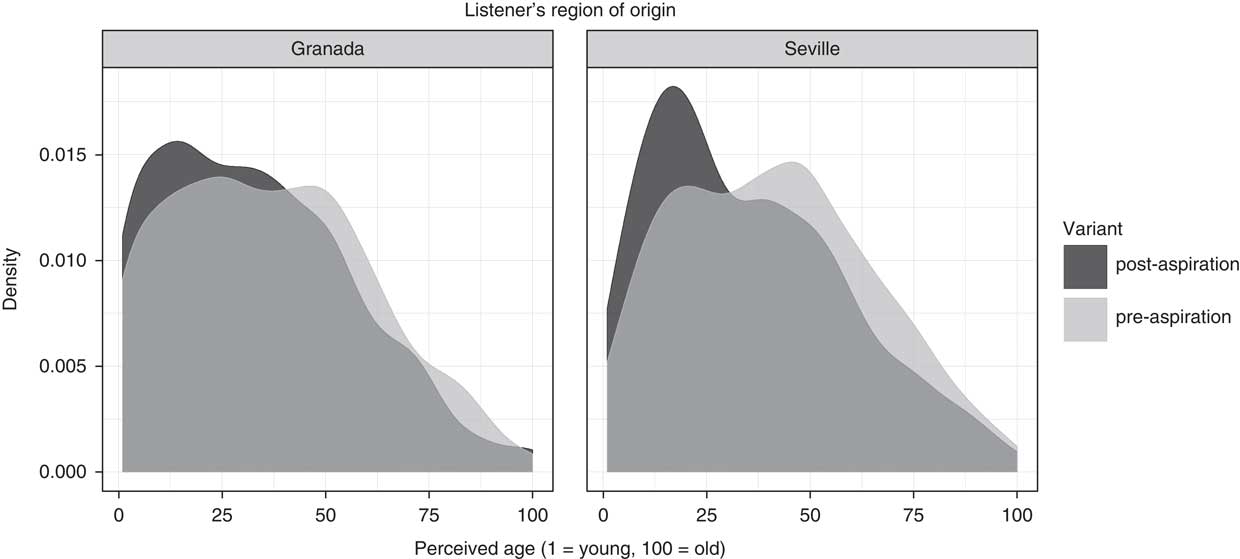
Figure 5 Density curves for the listeners’ age ratings according to the phonetic variant. The left panel shows the data for Granada, the right panel for Seville listeners. Low values on the x-axis stand for “young”, high values for “old” ratings.
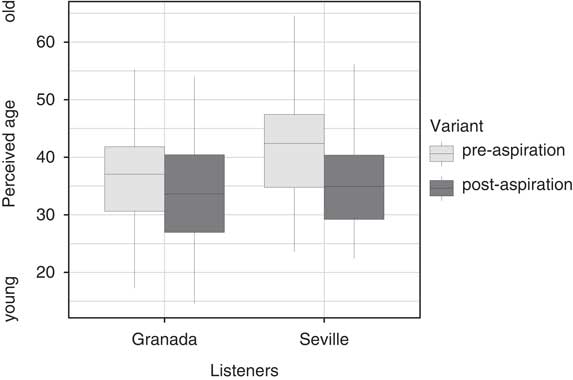
Figure 6 Boxplots showing the averaged age ratings per phonetic variant for each listener. Low values indicate the speakers were perceived as young, high values, as old.
Additional analyses were conducted to test 1) whether the listeners’ responses were affected by place of articulation, and 2) how age and dialect responses relate to each other.
As mentioned in the Introduction, the listeners’ knowledge of regional variation and change might depend on the place of articulation of the /s/ + stop sequence. In the following it will be tested whether not only /st/, but also /sp/ and /sk/ sequences carry indexical meaning. To do so, mean age and mean dialect ratings were calculated for each listener, place of articulation, and phonetic variant, resulting in six mean values per listener. A separate ANOVA was conducted for each place of articulation with age or dialect ratings as the dependent variable, a listener’s dialect as between-subject factor, and the phonetic variant as a within-subject factor. As for dialect ratings, the phonetic variant showed a significant effect in the expected direction for all three places of articulation and did not interact with a listener’s dialect (bilabial: (F[1,82])=5.3, p<0.05; dental: (F[1,82]=56.2, p<0.001); velar: (F[1,82]=9.0, p<0.01). The effect of phonetic variant on age ratings was significant for the bilabial (F[1,82]=23.4, p<0.001), but not the velar context (p=0.88). For /st/, a significant interaction was found between the aspiration variant and a listener’s dialect (F[1,81]=7.5, p<0.01). Separate analyses for each listener group showed that age ratings to pre- and post-aspirated stimuli containing /st/ significantly differed in both groups, but more significantly so in Seville than in Granada listeners (Granada F[1,38]=13.6, p<0.001; Seville: F[1,43]=54.8, p<0.001).
The more marked effect of phonetic variant in /st/ than in /sp, sk/ is in line with the previous findings and informal observations described above. However, and more importantly so, the results suggest for the first time that not only /st/, but also /sp/ and /sk/ possess socio-indexical meaning.
In a next step, a statistical test will be conducted to explore the relationship between age and dialect ratings. A linear mixed effect model was used with age rating as the dependent variable, dialect response, the phonetic variant, and a listener’s dialect as the fixed factors and word, listener, and speaker as random factors. The residuals followed a normal distribution and did not show auto-correlation, and therefore satisfied the model assumptions. Given that there were significant interactions between the phonetic variant and a listener’s dialect (χ2[2]=6.1, p<0.05) and between the phonetic variant and dialect response (χ2[2]=23.2, p<0.001), separate models were applied to each combination of fixed factors. A significant negative relationship between dialect response and age responses was found for post-aspirated stimuli in both Granada (χ2[1]=7.1, p<0.01) and Seville listeners (χ2[1]=22.8, p<0.001), but not for pre-aspirated stimuli or fillers. According to the results, post-aspirated stimuli rated as more Sevillian sounding tended to be at the same time rated as younger. Therefore, they showed the relationship that was expected based on the production results.
5.2 Identification of a Speakers’ Actual Age and Regional Origin
Given that the stimuli were created from words that originally had been produced by younger and older speakers from Seville and Granada, they naturally provided the listener with a number of other cues (e.g. vowel quality or voice quality) to localise the speaker. The aim of the subsequent analyses is to compare the effect of the manipulated phonetic variants against the stimuli’s other acoustic cues to age and regional origin. This will be done by calculating how well a speaker’s dialect and age was identified and how the proportion of correct answers was influenced by the phonetic variant. The listeners’ responses to the fillers, which were not manipulated, will be used as a baseline.
Identification of actual dialect
In a first step, the dialect responses were converted to two nominal categories “Seville” and “Granada”. Responses with values from 45 to 55 were excluded (527/6142 tokens; 8.6%). because they can be considered to represent a participant’s intention to mark the middle of the scale (50). Values above 55 were assigned to the category “Seville”, and values below 45 to the category “Granada”. These categories were then compared with the speaker’s actual origin and, according to a match/non-match, converted into a binary correct/false value.
Several trends can be observed in Fig. 7, which displays the proportion of correct answers for listeners from Seville and Granada. First, the proportion of correct answers on a whole was mostly above chance level (>0.50), indicating that the listeners’ responses indeed were affected by the actual dialect of a speaker. Second, listeners tended to assign a filler to their own dialect, as indicated by the higher proportion of correct responses when the speaker’s matched the listener’s dialect. And third, among the aspiration stimuli, the proportion of correct answers was higher when the phonetic variant matched the speaker’s origin, i.e. in pre-aspirated stimuli spoken by Granadians, and post-aspirated stimuli spoken by Sevillians. Among Seville listeners, two bars represent values below chance level precisely where the stimuli contained a phonetic variant that did not match the remaining dialect cues in the acoustic signal: pre-aspirated variants produced by Seville speakers, and post-aspirated stops by Granada speakers.
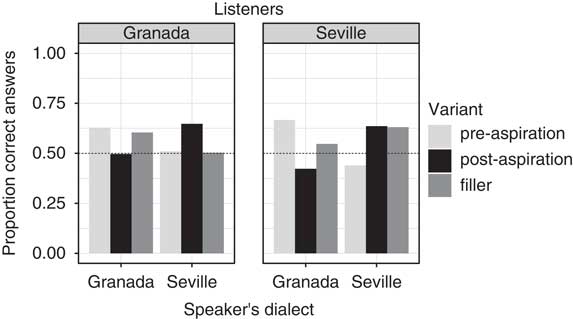
Figure 7 Proportion of correct dialect categorisations displayed separately for Granada (left panel) and Seville listeners (right panel), the dialect of the speaker (x-axis) and the phonetic variant (bars).
To test if the observed trends in Fig. 7 are significant, generalised linear mixed models (GLMM) were run. A first model with the binary dialect response (Granada/Seville) as the dependent variable, phonetic variant (3 levels: pre-aspirated, post-aspirated, filler), the speaker’s, and the listener’s origin as the fixed factors and word, listener, and speaker as random factors showed a significant three-way interaction (χ2[2]=6.6, p<0.05). Separate models were run to test each of the observations made above.
To assess whether dialect recognition was above chance, a GLMM with the same random factors, but only a speaker’s and a listener’s dialect as fixed factors was conducted. The test showed a significant effect of a speaker’s dialect (χ2[1]=13.1, p<0.001), confirming that overall, listeners’ responses were affected by a speaker’s actual dialect and thus above chance. The participants’ inclination to assign fillers to their own dialect was tested in a second GLMM with phonetic variant and a listener’s dialect as fixed factors. Given that there was a significant interaction between the fixed factors (χ2[2]=21.7, p<0.001), post hoc Tukey tests were conducted. They confirmed that Granada and Seville participants significantly differed in their responses to fillers (p<0.01), but not in their answers to pre- and post-aspirated stimuli.
On the whole, a speaker’s actual origin significantly influenced dialect perception, and when the actual origin of the speaker matched the phonetic variant (as in, e.g., a post-aspirated variant coming from a Sevillian speaker), the proportion of correct answers was boosted. When the two types of cues did not match (e.g. in a post-aspirated variant coming from a Granadian speaker), dialect recognition was at chance level. For Sevillian participants, the presence of the conservative or innovative phonetic variant in some cases even shifted the listener’s answers towards the other category, indicating that the phonetic variant can overweigh the remaining cues to regional origin.
Recognition of actual age
To see how a speakers’ actual age interacted with the phonetic variant present in the stimulus, the values on the visual analogue scale (VAS) were converted to years using the following formulaFootnote 1 :
 $$age_{{years}} \,{\equals}\,60/\left( {100/age_{{VAS}} } \right){\plus}20$$
$$age_{{years}} \,{\equals}\,60/\left( {100/age_{{VAS}} } \right){\plus}20$$
In Fig. 8 the converted age-ratings are plotted against a speaker’s actual age. A positive relationship between the actual and the perceived speaker age can be observed for both listener groups. The figure further shows that in their ratings, listeners underestimated the age of old speakers, and overestimated that of young speakers. This trend is consistent with earlier studies on age perception (Shipp & Hollien Reference Shipp and Hollien1969; Harnsberger et al. Reference Harnsberger, Rahul Shrivastav, Brown, Rothman and Hollien2008) and is likely due to a general “central tendency effect” in these kind of tasks (Moyse Reference Moyse2014: 259). A linear mixed effect model with a speaker’s actual age and a listener’s dialect as fixed factors and word, speaker and listener as random factors showed a significant effect of a speaker’s actual age on perceived age (χ2[1]=28.1, p<0.001).
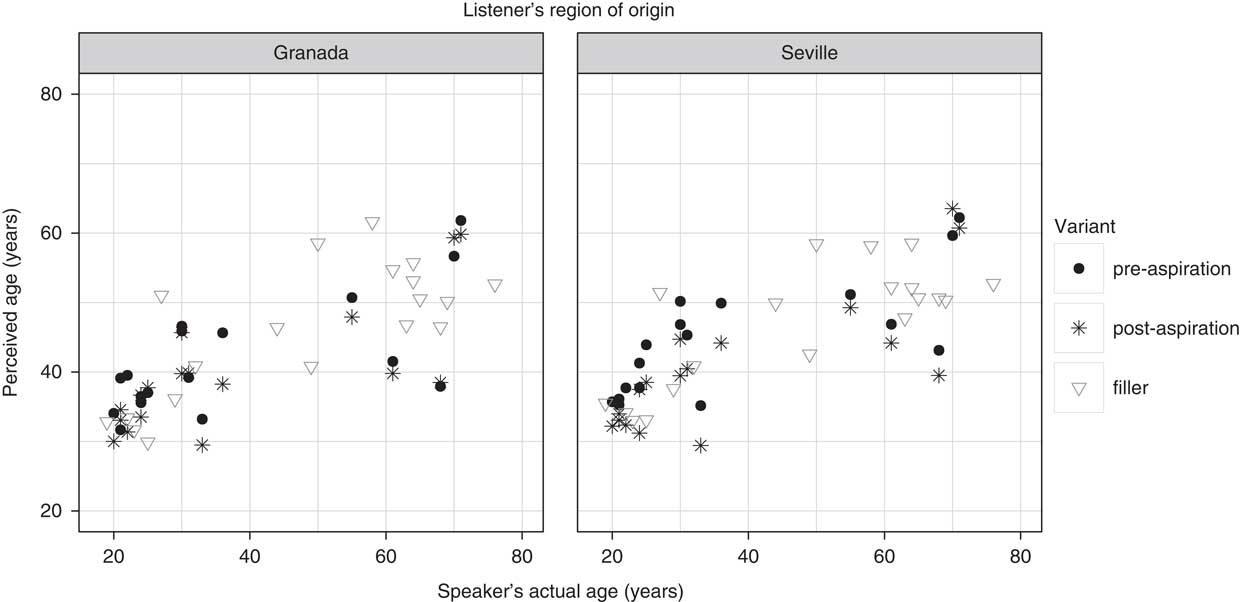
Figure 8 Perceived age in years (y-axis) plotted against the actual age of a speaker (x-axis).
These additional analyses have shown that the manipulated phonetic variant operated not in isolation, but interacted with the other acoustic cues to age and regional origin present in the stimulus. Overall, participants were more accurate in their age than in their dialect ratings. Some effects were found that had been observed in previous studies on age and dialect perception, namely the trend towards over-estimating the age of younger and under-estimating the age of older speakers, and the participants’ tendency towards assigning an ambiguous stimulus (filler) to their own dialect, similar to an own-age bias (Moyse, Beaufort & Brédart Reference Moyse, Beaufort and Brédart2014).
6 DISCUSSION
6.1 Perception experiment
This study investigated if native speakers of Andalusian Spanish possess linguistic knowledge of the geographic variation and a sound change which is currently affecting /s/+voiceless stop sequences in their variety. Phonetic variation in the aspiration of voiceless stops was able to shift the listeners’ ratings of speaker age and dialect significantly: when the stimulus contained a post-aspirated stop (e.g. [e.ˈthaŋ.ko]), the same speaker was estimated as being younger and as more Seville-sounding than when the stimulus contained a pre-aspirated stop (e.g. [eh.ˈtaŋ.ko]).
Previous perception experiments on Spanish have used a lenited /s/ (e.g. [eh.ˈtaŋ.ko]) and the full alveolar fricative (e.g. [es.ˈtaŋ.ko]) and have shown that these two variants possess social-indexical meaning (Boomershine Reference Boomershine2006; Walker et al. Reference Walker, García, Cortés and Campbell-Kibler2014). The present study for the first time has shown that not only /s/-lenition per se, but also more subtle phonetic variation within the lenited variants possess social-indexical meaning.
By using both age and dialect ratings and including listeners from two varieties, this study was able to investigate whether the different stages of the sound change is reflected in the listeners’ responses. The fact that Seville listeners’ age ratings were to a greater extent affected by the phonetic variant than those of Granada listeners’ ratings further mirror the findings from speech production (Ruch & Harrington Reference Ruch and Harrington2014; Ruch & Peters Reference Ruch and Peters2016) that the sound change is more advanced in Seville than in Granada Spanish. According to the production data it is plausible to assume that our participants from Seville are in their everyday life exposed to a more marked age-dependent difference in post-aspiration duration, and thus likely to be more aware of it than the participants from Granada.
The different stage of the sound change in the two speech communities was further apparent in a statistical relationship between dialect and age ratings to the same stimulus. Age and dialect responses were not independent from each other, but negatively correlated: the more a stimulus was rated as Sevillian-sounding, the lower the age rating it received. This result was found in both listener groups, but appeared to be significant only in stimuli with post-aspiration. On the one hand, this finding is in line with the production studies (Ruch & Harrington Reference Ruch and Harrington2014; Ruch & Peters Reference Ruch and Peters2016), where post-aspiration was longer in young Sevillian than young Granadian speakers, and where pre-aspiration did not differ between these two groups. On the other hand, this result can be interpreted in terms of acoustic and possibly also social salience. Post-aspiration can be considered to be acoustically more salient than pre-aspiration because it represents a noisy phase at the syllable onset between acoustic silence (i.e. the oral stop closure) and the following vowel, with abrupt transitions on either side. In contrast, pre-aspiration occurs at the syllable offset and is characterised by gradient transitions to neighbouring segments (Kingston Reference Antonio Kingston1990).
Post-aspiration thus meets several acoustic criteria to be noticed more easily than pre-aspiration, which however do not suffice to make post-aspiration socially salient (see Auer Reference Auer2014; Pharao et al. Reference Pharao, Maegaard, Møller and Kristiansen2014). More importantly, post-aspirated stops represent the new, innovative variant. Given that pre-aspirated stops still occur in both varieties (Ruch & Peters Reference Ruch and Peters2016) we hypothesise that they are less conspicuous to listeners than the new variant, and less likely to acquire social-indexical meaning. This could explain why the listeners’ age and dialect responses are correlated in stimuli with post-aspiration, but not in such with pre-aspiration.
Although overall, the phonetic variants in this study were able to shift the listeners’ age and dialect responses, the linguistic context nonetheless appeared to be relevant. This is apparent in the results from Section 5.2 in which dialect recognition was shown to be boosted when the phonetic variant fitted within its phonetic context (e.g. post-aspiration occurring in a stimulus recorded by a Sevillian speaker). This finding is in line with previous work that used the matched-guise technique to study social-indexical meaning (Levon Reference Levon2007; Campbell-Kibler Reference Campbell-Kibler2011; Podesva et al. Reference Podesva, D’Onofrio, Hofwegen and Kim2015; Pharao et al. Reference Pharao, Maegaard, Møller and Kristiansen2014). Unlike in Levon’s (Reference Levon2007) work on the perception of sexuality in American English, however, the phonetic variant in our study in some cases was able to override the other cues present in the acoustic signal. The social dimensions tested in the two studies, sexuality vs. regional origin and age, are of course very different and not directly comparable. Yet another reason for the less marked effect of linguistic context in our study may lie in the stimuli used. In contrast to the studies cited above, which worked with longer speech excerpts, the present experiment used isolated words which provided the listeners with less linguistic material to contextualise the speaker.
At this point it is not clear how the differences in dialect ratings between the two phonetic variants came about. At least two scenarios are possible: When a listener from Seville hears a post-aspirated stop, her decision criteria could be “does sound Sevillian” or “does not sound as I do”. The following subsection shall shed light on this issue by discussing the participants’ comments in the post-task questionnaire.
6.2 Post-task questionnaire
When asked in the post-task questionnaire what they focused on to recognise the different accents, several participants reported to have relied on previous experience with the dialects, what suggests that they are familiar with them.
En los acentos, sé cómo pronuncian unos y otros. ‘On the accents, I know how some and others pronounce’ (male, 69 years, Granada)
Intentaba recordar cómo habla un sevillano o un granadino y ya pues elegía por intuición. ‘I tried to remember how a Sevillian and how a Granadian person speaks and then selected according to my intuition’ (female, 18 years, Seville)
Two participants explicitly mentioned the second strategy, i.e., a comparison of the stimulus with their own dialect, suggesting that they do not possess a mental representation of the other variety (or at least are not aware of it).
En la pronunciación que conozco, y he puesto más hacia Granada la que no conozco. ‘On the pronunciation I know, and I opted towards Granada for the one I did not know (male, 43 years, Seville)
'En la pronunciación de las vocales y en ver si pronunciaban como yo, soy sevillano. ‘On the pronunciation of the vowels and on whether they pronounced as I do, I am Sevillian’ (male, 34 years, Seville)
The use of two separate scales “from Granada – not from Granada” and “from Seville – not from Seville”, respectively, could be used in future experiments to better understand how the listeners’ answers came about.
90 of the original 100 participants were able to mention at least one, the majority two or more typical characteristics to distinguish between the two dialects. Participants most frequently mentioned consonantal (82 out of 156 mentions) followed by prosodic (35 mentions) and vocalic (32 mentions) features. Among the mentioned consonantal features participants most frequently referred to the pronunciation of final consonants and /s/, as exemplified below:
Si termina de decir la palabra completa. ‘If they ended saying the word completely’ (male, 26 years, Seville)
Generalmente en la “s”. ‘Generally on the s’ (male, 35 years, Seville)
En que los sevillanos pronuncian más la “s” mientras los granadinos la omiten. ‘On the fact that the Sevillians pronounce the s more while the Granadians omit it’ (female, 35 years, Granada)
These statements are difficult to interpret because they may refer to /s/-lenition more generally, to the lenition of word-final /n/, or to seseo. However, eight participants from Granada and four from Seville explicitly mentioned aspiration of voiceless stops, as illustrated by the following comments:
El origen sevillano se reconoce por la fuerte sonoridad del paso st/sk/sp. ‘The Sevillian origin can be recognised by the strong sonority of the transition st/sk/sp.’ (male, 23 years, Seville)
Las consonantes como “t” o “k” son menos fuertes en Granada. ‘Consonants like t or k are less strong in Granada.’ (male, 43 years, Seville)
Mayor o menor ímpetu en la pronunciación de la “t”. ‘Greater or lesser weight in the pronunciation of the t’ (female, 27 years, Granada)
These participants seem to have explicit knowledge of the two dialects differing in the pronunciation of /s/+voiceless stops and, possibly, actively focused on this feature while doing the task.
When asked about their strategy for age estimation, the most frequent answers referred to the tone or sound of voice (e.g. tono de voz ‘tone of the voice’, timbre de voz ‘sound of the voice’, or voz ronca ‘hoarse voice’; 94 mentions). Nine listeners referred to speech rate, and only eight mentioned pronunciation-related features. However, with the exception of the first, none of these comments was as explicit and concrete as the comments about dialect distinction:
Los mayores a veces eliminan directamente la “s” final y no suelen pronunciar tan fuertes algunas “t” o “k”. ‘Older people sometimes eliminate directly the final s and do not usually pronounce some t or k so strongly.’ (male, 43 years, Seville)
En cómo al final, se comen el final de las palabras hablantes más jóvenes. ‘On how at the end, younger speakers eat the ends of words’ (male, 16 years, Seville)
Acento, pronunciación de todas las letras de la palabra. ‘Accent, pronunciation of all letters of a word’ (male, 23 years, Seville)
It is interesting to see that in production (Ruch & Harrington Reference Ruch and Harrington2014; Ruch & Peters Reference Ruch and Peters2016), Granada speakers seem to adopt a feature that, according to the present study, is perceptually associated with Seville Spanish. One possible interpretation of this apparent contradiction is that the sound change in production is taking place below the speakers’ awareness. It is also important to recall that in speech production, unlike in the current perception experiment, pre- and post-aspiration duration vary gradually, and that the more subtle amount of post-aspiration in Granada Spanish might not yet have captured their speakers’ attention.
On the other hand, a recent change in linguistic attitudes towards their own variety might favour the diffusion of an apparently Western feature towards Eastern Andalusia. Hofseth (Reference Hofseth2012) found the stereotype that Andalusians hablan mal ‘speak badly’ to be still present in younger Granadians. However, this group also declared to have less will to change their speech (e.g. by adopting a Madrid accent) than older generations. Thus, it is possible that younger Granadians have more positive attitudes towards Andalusian Spanish and, as a result, are more likely to adopt non-stigmatised Western Andalusian features such as post-aspirated stops. For other regional varieties and languages in Spain the speakers’ attitudes towards their own variety has been found to become more positive over the last decades, a change probably related to the recognition of multilingualism as well as to other socio-political changes in Spain (Hernández-Campoy & Villena-Ponsoda Reference Hernández-Campoy and Villena-Ponsoda2009:184; for details on socio-political changes, see Dietz Reference Dietz2001). In this light, a more-positive perception of the variety by its own speakers and an increasing prestige of some Andalusian features seems to be a plausible scenario.
At a first sight, this argumentation might contradict the trends documented for both Eastern, and more recently, Western Andalusian varieties to converge towards the northern standard, at least for the stigmatised ceceo (Villena Ponsoda Reference Villena Ponsoda2008; García-Amaya Reference García-Amaya2008; Moya Corral et al. Reference Moya Corral, Montoro del Arco, Cruz, Sosinski, de la Sierra Tejada Giráldez, López, Furest and García2014; Regan Reference Regan2017). However, it is important to keep in mind that post-aspirated stops represent only one out of several possible outcomes of lenited /s/+ voiceless stop clusters (Ruch Reference Ruch2008). Along with pre-aspirated variants [hp, ht, hk], post-aspirated stops and, in particular, the affricated [ts] can be interpreted as an attempt to conserve the underlying phonological /s/ (in contrast to geminated forms [pː, tː, kː] with complete loss of [h]) (Vida Castro Reference Vida Castro2016). In this sense, adoption of post-aspiration by Eastern Andalusian speakers not necessarily contradicts the general tendencies observed in Andalusian varieties to converge towards standard Spanish. Furthermore, different Andalusian features also differ in terms of social salience and values ascribed to them. While ceceo and seseo are considered to be highly salient, subtle variation in pre- and post-aspiration is certainly less conspicuous (see Regan Reference Regan2017), and might therefore have a very different faith.
To investigate the differences in Eastern and Western Andalusians’ attitudes towards Andalusian features and their variety more thoroughly, future work should explore a more ample set of Andalusian features and social dimensions, including traits such as pijo ‘snobbish’, correcto ‘correct’, educado ‘cultured’, and andaluz ‘Andalusian’. This would allow to gain a broader understanding of how post-aspirated stops are evaluated socially and how this may have favoured their spread within Andalusian Spanish.
7. ACKNOWLEDGEMENTS
I am grateful to the listeners for participating, to the speakers for lending their voice, and to everyone who helped finding participants by spreading the word. I would like to thank Sandra Schwab, Anne-France Pinget, and two anonymous reviewers for very helpful comments on earlier versions of this manuscript. I further thank Radu Tanase for statistical advice and Roberto Arias for insightful discussions on Andalusian Spanish. This paper also benefited from discussions with colleagues at the IPS Munich and from constructive comments of four anonymous reviewers during an earlier review process.
This work was supported by University of Zurich’s Research Priority Program Language and Space and a fellowship of the Swiss National Science Foundation 144359 to Hanna Ruch.
APPENDIX 1: Demographic data of the speakers from whom the recordings for the aspiration stimuli were taken; acoustic measurements of pre-aspiration, closure, and post-aspiration duration in the manipulated stimuli pairs.

APPENDIX 2: Phonetic transcription of the fillers together with the demographic data of the respective speakers.