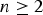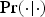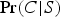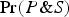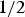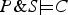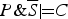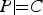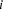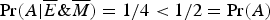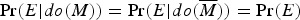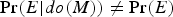1. SIMPSON'S PARADOX: THE USUAL DIALECTIC
There was a period in the 1970s when the admissions data for the UC–Berkeley graduate school (hereafter, BGS) exhibited some (prima facie) peculiar statistical correlations.Footnote 1 Specifically, a strong negative correlation was observed between being female and being accepted into BGS. This negative correlation (in the overall population of BGS applicants) was (initially) a cause for some concern regarding the possibility of gender bias in the admissions process at BGS. However, closer scrutiny of the BGS admissions data from this period revealed that no individual department’s admissions data exhibited a negative correlation between being female and being admitted. In fact, every department reported a positive correlation between being female and being accepted. In other words, a correlation that appears at the level of the general population of BGS applicants is reversed in every single department of BGS. This sort of correlation reversal is known as Simpson's Paradox. Because admissions decisions at BGS are made (autonomously) by each individual department, the lack of departmental correlations seems to rule-out the gender bias hypothesis as the best (causal) explanation of the observed correlations in the data. As it happens, there was a strong positive correlation between being female and applying to a department with a (relatively) high rejection rate. That is, women tended to apply to departments within BGS that have low(er) acceptance rates. And, this is what explains the observed correlations.
This informal presentation is typical of (most) discussions of Simpson's Paradox that one finds in the literature. Typically, one sees causal explanations of how some set of (“Simpson's-Paradoxical”) statistical correlations could have arisen in the first place (i.e., causal “how-possibly” explanations of the “paradoxical” correlational patterns in the statistical data). In this paper, I will be doing something different. I will be discussing what I will call rationalizing explanations of the paradoxicality of Simpson's Paradox. That is, I will be examining some explanations of why the cases may seem paradoxical in the first place.Footnote 2 In this sense, my treatment of Simpson's Paradox will be more similar to the way philosophers have approached (many) other “paradoxes” — by trying to explain (away) the sense of paradoxicality itself.Footnote 3 In the next section, I will provide some background on confirmation theory. In the remaining sections, I will (a) discuss some existing treatments (both causal and confirmation-theoretic) of Simpson's Paradox, and (b) offer a new (purely confirmation-theoretic) rationalizing explanation of the paradoxicality of Simpson's Paradox.
Here is a simplified, precise version of the BGS example, which will serve as our canonical example of Simpson's Paradox for the remainder of the paper. Let there be two departments: E and
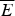 $\overline E $
(think: easy and not easy) and two genders (of applicants): M and
$\overline E $
(think: easy and not easy) and two genders (of applicants): M and
 $\overline M $
(think: male and not male).Footnote
4
And, let A (
$\overline M $
(think: male and not male).Footnote
4
And, let A (
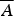 $\overline A $
) express the proposition than an applicant is accepted (not accepted). The following table gives all the relevant acceptance rates (i.e., statistical frequencies, which we will assume align with the objective probabilities/chances, in this situation) regarding this simplified characterization of BGS admissions (involving a total of 260 applicants, 130 of which applied to department E and 130 of which applied to
$\overline A $
) express the proposition than an applicant is accepted (not accepted). The following table gives all the relevant acceptance rates (i.e., statistical frequencies, which we will assume align with the objective probabilities/chances, in this situation) regarding this simplified characterization of BGS admissions (involving a total of 260 applicants, 130 of which applied to department E and 130 of which applied to
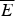 $\overline E $
).
$\overline E $
).
These acceptance rates are to be understood as follows. For instance,
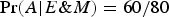 $\Pr (A \vert E\& M) = {60}/{80}$
means that the probability of acceptance for male applicants to department E is
$\Pr (A \vert E\& M) = {60}/{80}$
means that the probability of acceptance for male applicants to department E is
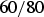 $ {60}/{80}$
— i.e.,
$ {60}/{80}$
— i.e.,
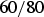 $ {60}/{80}$
of the male applicants to department E were accepted (and this frequency accurately reflects the corresponding objective probability of acceptance).
$ {60}/{80}$
of the male applicants to department E were accepted (and this frequency accurately reflects the corresponding objective probability of acceptance).
The crucial thing to notice here is that
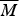 $\overline M $
is negatively relevant to acceptance in the overall population, i.e.,
$\overline M $
is negatively relevant to acceptance in the overall population, i.e.,
 $\Pr (A \vert \overline M ) \lt \Pr (A \vert M)$
, while
$\Pr (A \vert \overline M ) \lt \Pr (A \vert M)$
, while
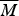 $\overline M $
is positively relevant to acceptance within each of the two departments, i.e.,
$\overline M $
is positively relevant to acceptance within each of the two departments, i.e.,
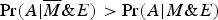 $\Pr (A \vert \overline M \& E) \gt \Pr (A \vert M\& E)$
and
$\Pr (A \vert \overline M \& E) \gt \Pr (A \vert M\& E)$
and
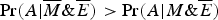 $\Pr (A \vert \overline M \& \overline E ) \gt \Pr (A \vert M\& \overline E )$
. This kind of reversal of correlations (between subpopulations and the overall population) is known as Simpson's Paradox.
$\Pr (A \vert \overline M \& \overline E ) \gt \Pr (A \vert M\& \overline E )$
. This kind of reversal of correlations (between subpopulations and the overall population) is known as Simpson's Paradox.
In the next section, I will provide a bit of theoretical background on confirmation theory. Then, I'll examine two recent discussions of Simpson's Paradox. Finally, I will present a new rationalizing explanation of the (apparent) paradoxicality of Simpson's paradox.
2. SOME BACKGROUND ON CONFIRMATION THEORY
From a deductive-logical point of view, “argument strength” does not come in degrees. An argument is either deductively valid or it is not. Confirmation theory aims to generalize this purely qualitative deductive notion of “argument strength.” Ideally, it would be nice to have a numerical measure of the degree to which some premise P supports some conclusion C. At least, that was Carnap's (Reference Carnap1962) dream – to construct a confirmation function
 $\frak {\rm c}$
(C, P), which (a) generalizes deductive entailment (in a sense to be made precise, below) and (b) is defined using probabilistic concepts, where (c) the probabilities in terms of which
$\frak {\rm c}$
(C, P), which (a) generalizes deductive entailment (in a sense to be made precise, below) and (b) is defined using probabilistic concepts, where (c) the probabilities in terms of which
 $\frak {\rm c}$
is defined are “objective” (and, ideally, logical). For present purposes, we won't need anything like a Carnapian confirmation function. This is for two main reasons. First, we'll only be looking at cases in which there are (uncontroversial, well-defined and well-known) statistical probabilities (viz., objective chances). So, we won't need to worry about the “objectivity” of the probability assignments that will underlie our confirmation-theoretic relations (and we won't need to mess around with “logical” probabilities). Second, we'll only need qualitative confirmation-theoretic concepts in order to provide our analyses (i.e., numerical confirmation measures won't be required for our purposes). In this sense, we will be employing a more Bayesian (and less Carnapian) approach to confirmation. However, we will follow Carnap in making a key distinction between two kinds of probabilistic confirmation.
$\frak {\rm c}$
is defined are “objective” (and, ideally, logical). For present purposes, we won't need anything like a Carnapian confirmation function. This is for two main reasons. First, we'll only be looking at cases in which there are (uncontroversial, well-defined and well-known) statistical probabilities (viz., objective chances). So, we won't need to worry about the “objectivity” of the probability assignments that will underlie our confirmation-theoretic relations (and we won't need to mess around with “logical” probabilities). Second, we'll only need qualitative confirmation-theoretic concepts in order to provide our analyses (i.e., numerical confirmation measures won't be required for our purposes). In this sense, we will be employing a more Bayesian (and less Carnapian) approach to confirmation. However, we will follow Carnap in making a key distinction between two kinds of probabilistic confirmation.
Confirmation as Firmness (confirms
f
). P confirms
f
C (relative to background supposition S
Footnote
5
) iff
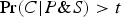 $\Pr (C \vert P \& S) \gt t$
, where t is some (possibly contextual) threshold.
$\Pr (C \vert P \& S) \gt t$
, where t is some (possibly contextual) threshold.
Confirmation as Increase in Firmness (confirms
i
). P confirms
i
C (relative to background supposition S) iff
 $\Pr (C \vert P\& S) \gt \Pr (C \vert S)$
.
$\Pr (C \vert P\& S) \gt \Pr (C \vert S)$
.
For present purposes, all of the conditional probabilities
 $\Pr ( \cdot \vert \cdot )$
will be given by a specification of some (uncontroversial) statistical probabilities (viz., objective chances). So, there will be no controversy about where the probabilities in question come from. Our focus here will be on using these two confirmation-theoretic relations to characterize Simpson's Paradox and explain why it seems paradoxical (but, in fact, is not).
$\Pr ( \cdot \vert \cdot )$
will be given by a specification of some (uncontroversial) statistical probabilities (viz., objective chances). So, there will be no controversy about where the probabilities in question come from. Our focus here will be on using these two confirmation-theoretic relations to characterize Simpson's Paradox and explain why it seems paradoxical (but, in fact, is not).
One important theoretical similarity between these two confirmation relations is that they both constitute generalizations of deductive validity, in the following sense. If P entails C, then P confirms C, relative to any background supposition S. To see why, note that if P entails C, then
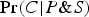 $\Pr (C \vert P\& S)$
will be maximal (i.e., equal to 1), and so we will (generallyFootnote
6
) have both
$\Pr (C \vert P\& S)$
will be maximal (i.e., equal to 1), and so we will (generallyFootnote
6
) have both
 $\Pr (C \vert P\& S) \gt t$
and
$\Pr (C \vert P\& S) \gt t$
and
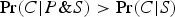 $\Pr (C \vert P\& S) \gt \Pr (C \vert S)$
. That is, entailing premises will (generally) make their conclusions highly probable and raise the probabilities of their conclusions (above the values taken relative to whatever background suppositions are involved).
$\Pr (C \vert P\& S) \gt \Pr (C \vert S)$
. That is, entailing premises will (generally) make their conclusions highly probable and raise the probabilities of their conclusions (above the values taken relative to whatever background suppositions are involved).
For our present purposes, the key theoretical differences between these two notions of confirmation can be seen by thinking of them as constituting (similar, but subtly different) explications of the concept of “argument strength.” If a premise P confers a high probability on conclusion C, then (at least in one sense) the argument can be said to be a “strong” one.Footnote
7
However, even if P confers a high probability on C, it may also be true that P lowers the probability of C (as compared with its initial/prior probability). In such cases, there also seems to be a sense in which P can not form the basis of a “strong argument in favor of” C. There are many examples of this sort in the literature. Some of the most interesting examples fall under the rubric “the base rate fallacy” (Kahneman and Tversky Reference Kahneman, Tversky, Kahneman, Slovic and Tversky1982; Levi Reference Levi1983).Footnote
8
For instance, let P be the claim that a positive test result has been obtained from an imperfect but reliable test for some rare disease (performed on a sample drawn from some individual a). And, let C be the claim that a does not have the rare disease in question. If the disease is sufficiently rare (i.e., if Pr(C) is sufficiently high), then
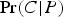 $\Pr (C \vert P)$
will (still) be very high. Nonetheless,
$\Pr (C \vert P)$
will (still) be very high. Nonetheless,
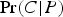 $\Pr (C \vert P)$
will be less than Pr(C), and so P will lower the probability of C. In such a case, it would be odd to say that P constitutes strong evidence in favor of C. The problem here is that “argument strength” has (at least) two probabilistic components: confirms
f
and confirms
i
, and these two components can run in opposite directions. This is what happens in “base rate fallacy” cases (and many other cases besides – see Fitelson (Reference Fitelson2015) for further discussion). Such cases reveal one important theoretical difference between confirms
f
and confirms
i
.
$\Pr (C \vert P)$
will be less than Pr(C), and so P will lower the probability of C. In such a case, it would be odd to say that P constitutes strong evidence in favor of C. The problem here is that “argument strength” has (at least) two probabilistic components: confirms
f
and confirms
i
, and these two components can run in opposite directions. This is what happens in “base rate fallacy” cases (and many other cases besides – see Fitelson (Reference Fitelson2015) for further discussion). Such cases reveal one important theoretical difference between confirms
f
and confirms
i
.
These two concepts also exhibit some more subtle theoretical divergences that will be important for our analysis of Simpson's Paradox. In order to grasp these more subtle theoretical differences, it is useful to consider the following principle regarding “argument strength.”
The Suppositional Sure Thing Principle (SSTP).Footnote
9
If P constitutes a strong argument for C on the supposition that S and P constitutes a strong argument for C on the supposition that
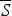 $\overline S $
, then P constitutes a strong argument for C (unconditionally).
$\overline S $
, then P constitutes a strong argument for C (unconditionally).
Basically, the SSTP involves a sort of suppositional “reasoning by cases.” It asks us to consider whether (a) the argument
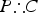 $P\therefore C$
is strong, given some (indicative) supposition S and (b) the argument
$P\therefore C$
is strong, given some (indicative) supposition S and (b) the argument
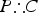 $P\therefore C$
is strong, given the negation of that (indicative) supposition (viz.,
$P\therefore C$
is strong, given the negation of that (indicative) supposition (viz.,
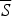 $\overline S $
). And, if both of these assessments come out positive, then the SSTP implies that
$\overline S $
). And, if both of these assessments come out positive, then the SSTP implies that
 $P\therefore C$
is strong unconditionally (i.e., in the absence of background suppositions).
$P\therefore C$
is strong unconditionally (i.e., in the absence of background suppositions).
This kind of suppositional “reasoning by cases” is correct for some understandings of “argument strength” but not for others. Specifically, SSTP is satisfied by confirmation as firmness (confirms f ), but not by confirmation as increase in firmness (confirms i ). That is to say, we have the following two key theoretical facts.Footnote 10
Fact 1. Confirmation
f
satisfies SSTP. In other words, it is generally true that if (a) P confirms
f
C, relative to S and (b) P confirms
f
C, relative to
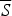 $\overline S $
, then (c) P confirms
f
C, unconditionally.
$\overline S $
, then (c) P confirms
f
C, unconditionally.
Fact 2. Confirmation
i
violates SSTP. In other words, there exist cases/contexts in which (a) P confirms
i
C, relative to S and (b) P confirms
i
C, relative to
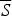 $\overline S $
; but, (c) P does not confirm
i
C, unconditionally.
$\overline S $
; but, (c) P does not confirm
i
C, unconditionally.
Fact 2 is the theoretical property of confirms i which makes Simpson's Paradox possible in the first place. Indeed, Simpson's Paradox cases just are the examples which establish the truth of Fact 2 (e.g., the simplified BGS example depicted in Table 1 above).
Table 1 Probabilistic structure of canonical (BGS) example of Simpson's Paradox.

While confirms f and confirms i disagree regarding the SSTP, they agree on a similar (but subtly different) theoretical principle regarding “argument strength.” To wit:
The Conjunctive Sure Thing Principle (CSTP). If
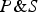 $P\& S$
constitutes a strong argument for C (unconditionally) and
$P\& S$
constitutes a strong argument for C (unconditionally) and
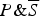 $P\& \overline S $
constitutes a strong argument for C (unconditionally), then P constitutes a strong argument for C (unconditionally).
$P\& \overline S $
constitutes a strong argument for C (unconditionally), then P constitutes a strong argument for C (unconditionally).
Like the SSTP, the CSTP also involves “reasoning by cases.” However, unlike the SSTP (which involves suppositional reasoning), the CSTP involves conjunctive (and non-suppositional) “reasoning by cases.” That is, the CSTP does not ask us to assess the strength of a single argument
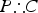 $P\therefore C$
, relative to a pair of suppositions (viz., S and
$P\therefore C$
, relative to a pair of suppositions (viz., S and
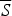 $\overline S $
). Rather, the CSTP asks us to consider the unconditional strength of a pair of arguments (
$\overline S $
). Rather, the CSTP asks us to consider the unconditional strength of a pair of arguments (
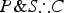 $P\& S\therefore C$
and
$P\& S\therefore C$
and
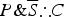 $P\& \overline S \therefore C$
). Interestingly, both confirmation
f
and confirmation
i
satisfy the CSTP. That is, we have:
$P\& \overline S \therefore C$
). Interestingly, both confirmation
f
and confirmation
i
satisfy the CSTP. That is, we have:
Fact 3. Confirmation
f
and confirmation
i
satisfy CSTP. In other words, it is generally true that if (a)
 $P\& S$
confirms C and (b)
$P\& S$
confirms C and (b)
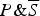 $P\& \overline S $
confirms C, then (c) P confirms C.Footnote
11
$P\& \overline S $
confirms C, then (c) P confirms C.Footnote
11
The disagreement between confirms
f
and confirms
i
with respect to SSTP vs. CSTP can be understood in terms of their ability to distinguish conjunctive vs. suppositional support/confirmation. Confirmation as firmness simply cannot distinguish between the two. If you want to know whether P confirms
f
C, on the supposition that S, you check whether
 $\Pr (C \vert P\& S) \gt t$
. And, this is exactly the same thing you must do if you want to check whether
$\Pr (C \vert P\& S) \gt t$
. And, this is exactly the same thing you must do if you want to check whether
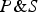 $P\& S$
confirms
f
C, unconditionally. In other words, from the point of view of confirmation as firmness, there is no distinction between conjunctive and suppositional support (in general). In light of this, it is easy to see why Facts 1 and 3 both obtain (for confirms
f
) – they are actually one and the same fact, from the perspective of confirmation
f
. This is not so for confirmation
i
, which distinguishes suppositional and conjunctive support in such a way that allows for Simpson's-Paradoxical cases (i.e., violations of the SSTP) to arise.
$P\& S$
confirms
f
C, unconditionally. In other words, from the point of view of confirmation as firmness, there is no distinction between conjunctive and suppositional support (in general). In light of this, it is easy to see why Facts 1 and 3 both obtain (for confirms
f
) – they are actually one and the same fact, from the perspective of confirmation
f
. This is not so for confirmation
i
, which distinguishes suppositional and conjunctive support in such a way that allows for Simpson's-Paradoxical cases (i.e., violations of the SSTP) to arise.
Facts 1–3 are the key theoretical facts that will undergird my (ultimate) rationalizing explanation of Simpson's Paradox. In the next section, I will examine two recent discussions of Simpson's Paradox. This will lead naturally into a new rationalizing explanation, based on Facts 1–3 above.
3. TWO RECENT DISCUSSIONS OF SIMPSON'S PARADOX
It is clear that there can be nothing truly paradoxical about “Simpson's Paradox.” After all, examples like Cartwright's BGS example actually occur in nature (all the time). So, what needs to be explained (or perhaps explained away) is the appearance of paradoxicality in cases of Simpson's Paradox (i.e., their prima facie paradoxicality). In this section, I'll discuss two recent treatments of Simpson's Paradox. Then, I'll propose a new, purely confirmation theoretic rationalizing explanation.
3.1 Pearl's Causal Rationalizing Explanation
Pearl (Reference Pearl2009: §6.1) provides a causal rationalizing explanation of Simpson's Paradox, according to which its apparent paradoxicality involves the conflation of an invalid argument involving confirmation i and a valid argument involving causation. Let's use our BGS example to illustrate Pearl's approach. In that example, there is a correlation between being female and being rejected from graduate school. But, this correlation is spurious. It is explained by the fact that females tend to apply to departments with lower acceptance rates. Furthermore, this “tendency” is not itself causal. How can we tell? Pearl would explain this by postulating that if we were to intervene on an applicant's gender, this would not have an effect on the probability that they apply to one department rather than another. In Pearl's notation, this amounts to the following assumption:
(†)
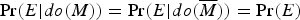 $\Pr (E \vert do(M)) = \Pr (E \vert do(\overline M )) = \Pr (E)$
.Footnote
12
$\Pr (E \vert do(M)) = \Pr (E \vert do(\overline M )) = \Pr (E)$
.Footnote
12
The main idea behind Pearl's rationalizing explanation is that people (to the extent they see the BGS case as paradoxical) are (falsely) assuming that the correlations involved all reflect causal relationships. In Pearl's notation, we can express the three key correlations in the BGS case as causal relations, in the following way:
(1)
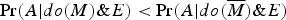 $\Pr (A \vert do(M)\& E) \lt \Pr (A \vert do(\overline M )\& E)$
$\Pr (A \vert do(M)\& E) \lt \Pr (A \vert do(\overline M )\& E)$
(2)
 $\Pr (A \vert do(M)\& \overline E ) \lt \Pr (A \vert do(\overline M )\& \overline E )$
$\Pr (A \vert do(M)\& \overline E ) \lt \Pr (A \vert do(\overline M )\& \overline E )$
(3)
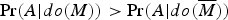 $\Pr (A \vert do(M)) \gt \Pr (A \vert do(\overline M ))$
$\Pr (A \vert do(M)) \gt \Pr (A \vert do(\overline M ))$
Claim (1) asserts that being male causally decreases the chance of acceptance – within department E. Claim (2) asserts that being male causally decreases the chance of acceptance – within department
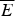 $\overline E $
. And, claim (3) asserts that being male causally increases the chance of acceptance – in the overall population.
$\overline E $
. And, claim (3) asserts that being male causally increases the chance of acceptance – in the overall population.
It can be shown (1)–(3) cannot all be true, if gender has no causal influence on which department one applies to (i.e., if claim (†) is true). That is, assuming (†), it is impossible for the three key (Simpson-reversal) correlations in the BGS case to reflect causal relationships. And, according to Pearl, this explains the sense of paradoxicality one may feel when one first hears about (e.g.) the BGS case. For if all of the correlations involved in the reversal were causal, then — assuming (†) — this would be paradoxical (as it would involve an inconsistent set of probabilistic claims). Thus, Pearl's account predicts that once one learns the underlying causal structure of the case (e.g., that condition (†) holds in the case, etc.), one's sense of paradoxicality should disappear.Footnote 13
Pearl's causal rationalizing explanation is interesting and illuminating. But, I think it has a couple of potential shortcomings. First, it is not a purely confirmation-theoretic explanation. Simpson's Paradox does not essentially involve any causal concepts. It only (essentially) involves relations of confirmation i . As such, it would be nice to have a purely confirmation-theoretic rationalizing explanation. Second, while Pearl's account does involve the conflation of a valid argument (his causal argument) and an invalid one (the purely confirmation i -theoretic one), the valid argument is enthymematic. That is, Pearl's causal paradox does not just involve the correlations that are given in the statement of the paradox [i.e., (1)–(3)] it also involves an unstated causal independence premise/assumption [i.e., (†)] which is not essential to the statement of Simpson's Paradox. In these two senses, Pearl's rationalizing explanation brings in considerations that are not essential to the Paradox (per se). It would be preferable (ceteris paribus) to have a rationalizing explanation that appeals only to information that is given (essentially) in the statement of the paradoxical cases.
Next, I will discuss Kotzen's (Reference Kotzen2013) recent take on Simpson's Paradox. That will lead us toward our purely confirmation-theoretic rationalizing explanation.
3.2 Kotzen on Simpson's Paradox and The Miners Puzzle
Kotzen (Reference Kotzen2013) draws an analogy between Simpson's Paradox and the Miners Puzzle (Kolodny and MacFarlane Reference Kolodny and MacFarlane2010). For our purposes, the key feature of Kotzen's approach is the reconstruction of Simpson's paradoxical cases as violations of the following classically valid form of deductive inference:
If S, then P confirms i Q.
If
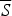 $\overline S $
, then P confirms
i
Q.
$\overline S $
, then P confirms
i
Q.
Therefore, P confirms i Q.
While this form of argument is valid for the material conditional (i.e., if ⌜if p, then q⌝ is interpreted as ⌜p⊃q⌝), it may not be valid for other kinds of conditionals (e.g., the English indicative conditional). Some authors have taken the Miners Puzzle to provide reasons to think that the English indicative does not obey various classically valid forms of deductive inference (e.g., the form of inference above, or even modus ponens), when the consequent(s) of the conditionals contain various sorts of modal expressions (Kolodny and MacFarlane Reference Kolodny and MacFarlane2010). Similarly, Kotzen presents Simpson's Paradox as having an analogous structure/upshot – but with respect to consequent(s) containing confirmation i -theoretic expressions.
While Kotzen's aim is not to provide a rationalizing explanation of why Simpson's Paradox seems paradoxical in the first place, I think his analogy with the Miners Puzzle puts us on the right track toward formulating such an explanation.
4. A NEW RATIONALIZING EXPLANATION OF SIMPSON'S PARADOX
I think Kotzen's discussion leads us in the direction of a purely confirmation-theoretic rationalizing explanation of Simpson's Paradox. I propose that the prima facie paradoxicality of Simpson's Paradox can be explained (at least in part) by appealing to the (subtle) distinction between conjunctive confirmation (or support) and suppositional confirmation (or support) that was implicit in our discussion of SSTP vs. CSTP above. To wit, contrast the following:
Suppositional Reading. If S, then P confirms C.
Conjunctive Reading.
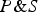 $P\& S$
confirms C.Footnote
14
$P\& S$
confirms C.Footnote
14
I propose that there is a tendency for hearers of descriptions of Simpson's Paradox cases to conflate these two readings. Let's apply this to our BGS case. To make things more concrete, let us now suppose that department
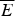 $\overline E $
is History. Then, we may describe the correlation between being female and being accepted to History, in the following two ways:
$\overline E $
is History. Then, we may describe the correlation between being female and being accepted to History, in the following two ways:
Suppositional. If one applies to History, then being female improves one's chances of acceptance.
Conjunctive. Being a female History applicant improves one's chances of acceptance.
In our BGS example, it is only the Suppositional reading that is true.Footnote 15 Moreover, as we have seen, these two readings – while similar-sounding to the (untrained) ear – make all the difference, in terms of paradoxicality. If we slide from Suppositional to Conjunctive, then we are sliding from an interpretation on which the examples described are possible (because of Fact 2), to one on which they are impossible (because of Fact 3). And, this will be true for any example of Simpson's Paradox – even ones in which Pearl's causal independence assumption (†) fails. So, if my proposal is right, then we can exploit the fact that the conjunctive STP is a truism about confirmation (no matter how it is explicated) to furnish an explanation-away of the apparent paradoxicality of Simpson's Paradox.
Here's how that explanation would go. Examples of Simpson's Paradox involve violations of the SSTP. To the extent that hearers tend to conflate suppositional vs. conjunctive readings of the key locutions involved in descriptions of such cases, there will be a tendency to hear such cases as violations of the C STP. But, there can be no violations of the CSTP (since, as Fact 3 reveals, it is a general truism about confirmation — no matter how it is explicated). Therefore, to the extent that hearers tend to conflate suppositional vs. conjunctive readings of the key locutions involved in descriptions of such cases, there will be a tendency for hearers to interpret the cases as implying something paradoxical (i.e., as somehow contradicting a theoretical truism).Footnote 16 But, because there can be no such cases, the appearance of paradoxicality is a mere appearance (arising, at least in part, from said conflation).
Our rationalizing explanation has a couple of virtues, in comparison with Pearl's causal rationalizing explanation. First, ours is purely confirmation-theoretic – it makes no appeal to causal relations, which are inessential to the description of Simpson's Paradoxical cases. Moreover, Pearl's explanation relies on an implicit causal independence assumption [(†)] which is not stated in the descriptions of the Paradox. Our explanation applies to all instances of Simpson's Paradox – even ones in which Pearl's assumption (†) fails.Footnote 17 In any case, even if causal facts/presuppositions are playing a role in the (prima facie) paradoxicality of Simpson's Paradox, my proposal is that the suppositional/conjunctive distinction/conflation also has (independent, rationalizing) explanatory relevance/force.
APPENDIX: PROOFS OF FACTS 1–3
For our proofs, we will adopt the algebraic style/methods of Fitelson (Reference Fitelson2008). The following stochastic truth table (Fitelson Reference Fitelson2008) represents all possible probability distributions over the {P,C,S} language, via the 7 real variables a, b, c, d, e, f, g ∈ [0, 1].

Fact 1. Confirmation
f
satisfies SSTP. In other words, it is generally true that if (a) P confirms
f
C, relative to S and (b) P confirms
f
C, relative to
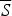 $\overline S $
, then (c) P confirms
f
C, unconditionally.
$\overline S $
, then (c) P confirms
f
C, unconditionally.
Proof. Fact 1 asserts that the following argument in probability calculus is valid (where t is some positive threshold value on the unit interval).

Algebraically (using the above setup (Fitelson Reference Fitelson2008)),
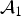 ${\cal A}_1$
is equivalent to:
${\cal A}_1$
is equivalent to:

Cross-multiplying (1) & (2) yields:
 $$a \gt (a + c) \cdot t$$
$$a \gt (a + c) \cdot t$$
 $$b \gt (b + d) \cdot t$$
$$b \gt (b + d) \cdot t$$
Adding the lhs & rhs of these and collecting t yields
 $$a + b \gt (a + b + c + d) \cdot t$$
$$a + b \gt (a + b + c + d) \cdot t$$
which is equivalent to (3). □
Fact 2. Confirmation
i
violates SSTP. In other words, there exist cases/contexts in which (a) P confirms
i
C, relative to S and (b) P confirms
i
C, relative to
 $\overline S $
; but, (c) P does not confirm
i
C, unconditionally.
$\overline S $
; but, (c) P does not confirm
i
C, unconditionally.
Proof. The BGS example depicted in Table 1 is sufficient to establish this claim. For completeness, I include here the full stochastic truth table representation of the probability model depicted in Table 1 above (in this example, the relevant instantiation of the SSTP schema is:
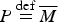 $P\mathop = \limits^{{\rm def}} \overline M $
,
$P\mathop = \limits^{{\rm def}} \overline M $
,
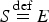 $S\mathop = \limits^{{\rm def}} E$
, and
$S\mathop = \limits^{{\rm def}} E$
, and
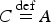 $C\mathop = \limits^{{\rm def}} A$
).
$C\mathop = \limits^{{\rm def}} A$
).

It is easily verified that, in this model, the following three constraints are satisfied:
-
(i)
 $\overline M $
confirms
i
A, relative to E.
$$\Pr (A \vert \overline M \& E) = {4/5} \gt {3/4} = \Pr (A \vert M\& E)$$
$\overline M $
confirms
i
A, relative to E.
$$\Pr (A \vert \overline M \& E) = {4/5} \gt {3/4} = \Pr (A \vert M\& E)$$
-
(ii)
$\overline M $
confirms
i
A, relative to
$\overline E $
.
$$\Pr (A \vert \overline M \& \overline E ) = {1/4} \gt {1/5} = \Pr (A \vert M\& \overline E )$$
-
(ii)
$\overline M $
disconfirms
i
A, unconditionally.
$$\Pr (A \vert \overline M ) = 6/{13} \lt 7/{13} = \Pr (A \vert M)$$





Thus, the BGS example illustrates the failure of confirms i to satisfy the SSTP.□
Fact 3. Confirmation
f
and confirmation
i
satisfy CSTP. In other words, it is generally true that if (a)
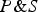 $P\& S$
confirms C and (b)
$P\& S$
confirms C and (b)
 $P\& \overline S $
confirms C, then (c) P confirms C.
$P\& \overline S $
confirms C, then (c) P confirms C.
Proof. We have already shown that confirmation
f
satisfies CSTP, since this is equivalent to showing that argument form
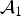 ${\cal A}_1$
, above, is valid.
${\cal A}_1$
, above, is valid.
To show that confirmation i satisfies CSTP, we just need to show that the following argument form is valid.

Algebraically (using the above setup (Fitelson Reference Fitelson2008)),
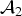 ${\cal A}_2$
is equivalent to
${\cal A}_2$
is equivalent to

Cross-multiplying (1) & (2) yields
 $$a \gt (a + c) \cdot (a + b + e + f)$$
$$a \gt (a + c) \cdot (a + b + e + f)$$
 $$b \gt (b + d) \cdot (a + b + e + f)$$
$$b \gt (b + d) \cdot (a + b + e + f)$$
Adding the lhs & rhs of these and collecting t yields
 $$a + b \gt (a + b + c + d) \cdot (a + b + e + f)$$
$$a + b \gt (a + b + c + d) \cdot (a + b + e + f)$$
which is equivalent to (3).Footnote 18