


1. INTRODUCTION
1.1. Defining the value of a representation
Function models are one of the many design representations used by designers to understand the description of the product at an initial stage (Otto & Wood, Reference Otto and Wood2001; Ulrich & Eppinger, Reference Ulrich and Eppinger2008; Ullman, Reference Ullman2010; Pahl et al., Reference Pahl, Beitz, Blessing, Feldhusen, Grote and Wallace2013). A representation can be thought of as a language that can be used for creating models that are abstractions or substitutions for actual entities. For example, if a juicer is an entity, it can be modeled by using a method of representation, that is, a sketch, or a function model, or a three-dimensional geometric model. Each of these three representations has its own unique vocabulary, grammar, and expression used (Summers & Shah, Reference Summers and Shah2004).
In reverse engineering, function models are important because they help to define clear system boundaries around customer needs (Otto & Wood, Reference Otto and Wood2001). Moreover, the functional modeling representation helps engineers in ideation by providing means to abstract and decompose problems so as to manipulate partial solutions (Otto & Wood, Reference Otto and Wood2001). Previous research has helped to develop a deeper understanding of how much value this design representation has in terms of information content and designer interpretability (Caldwell & Mocko, Reference Caldwell and Mocko2008; Sen, Caldwell, et al., Reference Sen, Caldwell, Summers and Mocko2010; Caldwell, Thomas, et al., Reference Caldwell, Thomas, Sen, Mocko and Summers2012). The objective of the current research is to develop a deeper understanding of the value contained in this representation from a computational or information-centric perspective.
Value in a general context is understood as how beneficial something is perceived to be. In terms of value of a representation, it is defined as how well the representation can support reasoning activities. For instance, in comparing two functional models of a product, the one that is able to more accurately answer questions about the product could be considered to be more valuable. In this work, the ability of a function model to support the prediction of the market price of the product is one measure of value of the representation. The cost associated with creating the models in the different representations is out of scope for this study and reserved for future investigation.
In much the same manner that the value of information presents engineers and decision makers with a means of justifying how much effort or resources to expend to gather more information when making a decision (Bradley & Agogino, Reference Bradley and Agogino1994; Thomke, Reference Thomke1998; Radhakrishnan & McAdams, Reference Radhakrishnan and McAdams2005; Messer et al., Reference Messer, Panchal, Allen, Mistree, Krishnamurthy, Klein and Yoder2008; Panchal et al., Reference Panchal, Paredis, Allen and Mistree2008), this approach provides engineers with a means to compare representations in which to model their products. It is important to note that there are multiple function modeling methods available for designers to choose from, as will become clear from Section 2. Besides, even within the function structures, modifications can be made in order to create a distinct representation, as will become clear from Section 4. Under these circumstances, it is of the utmost important that these representations be classified using their value as a benchmark as a decision-making aid to the designers using these representations during the conceptual stage. While the method presented here can be extended to evaluate representations other than function models, the discussion in this work will be limited to function models only.
While some researchers have employed information theory as a means to measure the information content and therefore the value of the information (Shimomura et al., Reference Shimomura, Yoshioka, Takeda, Umeda and Tomiyama1998), the approach taken here is focused on the ability of the model within a representation to predict future information.
2. FUNCTION MODELING: A BACKGROUND
Function structures are discussed in engineering design textbooks, as one of the important component of the conceptual design phase (Otto & Wood, Reference Otto and Wood2001; Ulrich & Eppinger, Reference Ulrich and Eppinger2008; Ullman, Reference Ullman2010; Pahl et al., Reference Pahl, Beitz, Blessing, Feldhusen, Grote and Wallace2013). In the case of new products, it is all the more important to establish a function structure. Function structures assume an even more important role when it comes to product design textbooks. In the systematic design process, function structures are synthesized from customer requirements, and hence are instrumental in mapping customer requirements to possible physical solutions. Moreover, they are the among the earliest models of a solution, capturing at a high level how the desired functions within a product are supported through enabling functional transformations of material, energy, or signal. Outlining the initial functionality of a product is an important first step, although there are design representations other than function structures that can be used to do so.
Function representation is useful across engineering disciplines, most notably in the field of mechanical and electrical engineering (Chandrasekaran et al., Reference Chandrasekaran, Goel and Iwasaki1993; Chandrasekaran & Josephson, Reference Chandrasekaran and Josephson2000). Function representation in form of function behavior state is used to integrate conceptual design and computer-aided design (Umeda et al., Reference Umeda, Ishii, Yoshioka, Shimomura and Tomiyama1996). One of the notable function representations is the function, behavior, structure model, which is widely used in the domain of protocol studies to understand how design engineers address problems (Gero & Kannengiesser, Reference Gero and Kannengiesser2004). Function modeling can be useful in many other domains, but the representations selected here have been explicitly developed to model electromechanical systems.
Beyond the focus of defining function vocabulary (Szykman et al., Reference Szykman, Racz and Sriram1999; Hirtz et al., Reference Hirtz, Stone, McAdams, Szykman and Wood2002; Kurtoglu et al., Reference Kurtoglu, Campbell, Bryant, Stone and McAdams2005), researchers have explored ways to use the function models in supporting engineering design activities. For instance, researchers have employed functional representations as a basis for analogy identification, including defining critical function flows to define solution elements (Lucero et al., Reference Lucero, Viswanathan, Linsey and Turner2014, Reference Lucero, Linsey and Turner2016). Their definitions of critical function flows suggest that some elements of the functional model are more significant than others, which may be interpreted as being information rich. Other approaches also employ functional models to generate textual analogies based on equating functions with physical effects and physical effects with linguistic database searches (Qian & Gero, Reference Qian and Gero1996; Nix et al., Reference Nix, Sherrett and Stone2011; Russo et al., Reference Russo, Montecchi and Liu2012; Russo & Rizzi, Reference Russo and Rizzi2014; Montecchi & Russo, Reference Montecchi and Russo2015). Many of these efforts have focused on developing conceptual computer-aided design tools to aid in the synthesis of artifact models (Umeda & Tomiyama, Reference Umeda and Tomiyama1997; Vargas-Hernandez & Shah, Reference Vargas-Hernandez and Shah2004; Chakrabarti et al., Reference Chakrabarti, Shea, Stone, Cagan, Campbell, Hernandez and Wood2011).
Because of their significance in mechanical, electrical, and product design, researchers have tried to understand how to characterize and use function structures. One such effort includes attempts to formalize the function structures using a functional basis, which basically constitutes a standard functional design vocabulary (Stone & Wood, Reference Stone and Wood2000). A detailed study on the expressiveness of the functional basis found that the functional basis needs more formalization to achieve an increase in usefulness for reverse engineering and an increased level of expressiveness that can be achieved by an increased vocabulary for flow labels and an extended tertiary level vocabulary (Caldwell et al., Reference Caldwell, Sen, Mocko and Summers2010). A study was also conducted to understand how effectively student designers can use the formalizing rules to create function structures (Nagel et al., Reference Nagel, Bohm, Linsey and Riggs2015). It was found that with better instructions and formal rules, students construct better and more complete function structures. There have also been calls to the design community to work toward formalizing benchmarking protocols based on representation characteristics of function structures in order to create a formal comparison (Vucovich et al., Reference Vucovich, Bhardwaj, Hoi-Hei, Ramakrishna, Thakur and Stone2006).
From the recent developments in this field, it is seen that there is an emphasis on standardizing the creation and evaluation of function structures. This study aims at evaluating function structures representations from an inferencing viewpoint. While doing so, it is also important to adhere to some form of benchmarking approach in order to classify different types of function representations (Summers et al., Reference Summers, Eckert and Goel2013). The benchmarking approach adhered to in this research is modeler-driven benchmarking. It is important for the user to understand the value in and the utility of each type of the function structure in different stages of design or even for different kinds of tasks. Hence, even though different types of function structures may look similar on the surface, there is a marked difference between them based on their content (Rosen & Summers, Reference Rosen and Summers2012; Summers & Rosen, Reference Summers and Rosen2013). This difference makes it worthwhile to study whether this difference in the content of different types of function structures qualifies each type to be considered a different design representation. One such study describing the classification of design representations is of special interest to this research (Summers & Shah, Reference Summers and Shah2004). As per this research, any design representation can be completely described by a set of five characteristics: vocabulary, grammar, expression, purpose, and abstraction (Summers & Shah, Reference Summers and Shah2004). The next section lists the objectives of this research in greater detail.
3. RESEARCH MOTIVATION: COMPARATIVE STUDIES ON REPRESENTATION INFERENCING SUPPORT
This research is motivated by the need to define an objective method to select between different available representations. While most of the comparative studies on function representations have addressed starkly different vocabularies and grammars, this research seeks to determine whether there are differences between similar representations that would warrant the selection of one representation over another. As will be described in detail in the following sections, a change in the level of abstraction of a function structure gives rise to distinctly different function structure representation. For this reason, the function structure is selected as the base representation.
In order to experiment with various vocabularies and grammars, the function structures are pruned of whichever of these components are being studied. Thus, any impact on the value of the representation can be attributed to the pruned component. A series of similar representations are defined using previous work on function “pruning” rules (Caldwell & Mocko, Reference Caldwell and Mocko2012). The inferencing support (surrogate) explored here is the ability of a representation to support the prediction of a market value for a product based on the functional description. This work builds on previous work that explored market value prediction (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011), the accuracy of prediction models (Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016a ), and the precision of these prediction models (Mohinder et al., Reference Mohinder, Sudarshan, Summers and Gero2014, Reference Mohinder, Gill, Summers and Gero2016). The research questions are the following:
-
• Can the value of a representation be used to compare two similar function representations?
-
• Can the value of a representation be associated with specific pruning rules?
Previous research has focused on quantifying the information content of function models in an information theoretic approach (Sen, Caldwell, et al., Reference Sen, Caldwell, Summers and Mocko2010; Sen, Summers, et al., Reference Sen, Summers and Mocko2010) and also by means of user studies (Caldwell et al., Reference Caldwell, Sen, Mocko and Summers2010; Caldwell, Ramachandran, et al., Reference Caldwell, Ramachandran and Mocko2012; Caldwell, Thomas, et al., Reference Caldwell, Thomas, Sen, Mocko and Summers2012). An information metric was developed that is applicable to function structures constructed using vocabulary and nouns from a predetermined set of the same (Sen, Caldwell, et al., Reference Sen, Caldwell, Summers and Mocko2010). The information content is interpreted as the number of binary questions that need to be answered in order to re-create the function structure. The method of calculating the information content entails uncertainty, which can be offset to some extent by incorporating the topological information content of the function structure. This was extended to explore the information content found within the topology of a model (Sen, Summers, et al., Reference Sen, Summers and Mocko2010). In these approaches, the reasoning was supported through deductive reasoning, rather than historical reasoning (Summers, Reference Summers2005). Thus, this research explores an approach to comparing representations based on a different type of reasoning using historical learning through neural networks.
4. ABSTRACTION BY PRUNING AS A DISTINGUISHING CHARACTERISTIC OF FUNCTION STRUCTURES
Researchers have studied how composing the function structures can impact its level of detail (Caldwell & Mocko, Reference Caldwell and Mocko2008). It was found that when the function structures were pruned to simplify functional models, they still retain the same level of detail and retain their usefulness to the designer. This was verified by a user study (Caldwell, Thomas, et al., Reference Caldwell, Thomas, Sen, Mocko and Summers2012). Thus, the value of the representation is maintained with respect to the ability of engineers to interpret the models correctly. Recognizing that different metrics applied against similar products through different representations can result in different evaluations (Ameri et al., Reference Ameri, Summers, Mocko and Porter2008), it is important to explore whether the pruning representations defined in Caldwell and Mocko (Reference Caldwell and Mocko2008) result in an improved or decreased ability to predict market price based on historical reasoning.
Since changing the abstraction in a design representation can possibly lead to it being classified as a different design representation and the pruning rules themselves relate to both the grammar and the vocabulary allowed (Summers & Shah, Reference Summers and Shah2004), it is important to verify the impact on the original set of function structures of different abstractions carried out in the following section. In order to provide a uniform base for comparison of different representation, the same set of 20 consumer products were used for this study and are similar to the sets used in previous work (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011; Mohinder et al., Reference Mohinder, Sudarshan, Summers and Gero2014; Gill & Summers, Reference Gill and Summers2016; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016b ).
5. PRUNING FUNCTION STRUCTURES: NEW FUNCTION REPRESENTATIONS
5.1. Functional pruning
A function structure is made by combining a number of individual functions (Pahl et al., Reference Pahl, Beitz, Blessing, Feldhusen, Grote and Wallace2013), connecting these transformers by material and energy flow. For engineers to be able to use this tool meaningfully, it is important that it can be decomposed into smaller problems that can lead to known solutions. An identified challenge with using the function structures effectively is that the functional basis vocabulary was developed through reverse engineering (Caldwell et al., Reference Caldwell, Sen, Mocko and Summers2010). Thus, some aspects of this vocabulary are more relevant for describing existing products rather than future products. Further, a review of function models in a design repository found that most of the models were generated through reverse engineering (Bohm et al., Reference Bohm, Stone and Szykman2005, Reference Bohm, Vucovich and Stone2008). To address the challenge of pruning reverse engineering based function models to their core elements, a set of rules were developed (Caldwell & Mocko, Reference Caldwell and Mocko2008). In addition, the products whose function structures have been used in this study have all been developed using reverse engineering. This was done to ensure that the vocabulary was in line with the functional basis on which the set of rules is based.
Two methods developed to create function structures include using the functional basis hierarchy and definition based on functionality (Caldwell & Mocko, Reference Caldwell and Mocko2012). This research will focus on the latter, because synthesis using functional basis hierarchy does not present itself as an adequate method on which rules can be formalized. The next section discusses the rules that are defined.
5.2. Rules for functional pruning
When a function structure undergoes functional pruning, function blocks are removed and the function flows are rerouted accordingly. The pruning is carried out in accordance with the rules that have been previously developed (Caldwell & Mocko, Reference Caldwell and Mocko2008). It is important to understand that these rules were developed empirically. Another limitation of these rules is that they are applicable to function structures of electromechanical devices, and more specifically the ones present in the Design Repository (currently housed at Oregon State University). A total of nine rules were developed to prune the function structures. The rules are intended to prune the functions that tend to be solution specific and leave behind function structures that tend to be solution neutral. While initially developed to reduce the models, these rules can be enforced during model construction. Similarly, if product functionality can be implied by the flow or connections between the functions, they will not add much value to the higher level of composition and need to be pruned. These rules are listed in Table 1.
Table 1. Classification of pruning rules

The nine rules of pruning (Caldwell & Mocko, Reference Caldwell and Mocko2008) are classified here into three different categories: vocabulary, grammar, and topology. It is imperative to classify these rules according to their impact on a function structure. The rules that deal with just the text in the function block need to be differentiated from the rules that act on the function structures depending on the type of energy flow that is interacting with a function block containing a specific wording. Therefore, rules that deal with the usage of specific words in the functions are classified as vocabulary pruning rules. The rules that deal with function vocabulary that is used in conjunction with specific type of materials, energy, or signals were classified as grammar pruning rules. This classification is in line with the representation classification characteristics previously developed (Summers & Shah, Reference Summers and Shah2004). Vocabulary refers to the entities that make up the presentation, which in this case are the function blocks that contain the text. Grammar or structure refers to the structure of the representation, the rules that allow the vocabulary elements to be linked (Summers & Shah, Reference Summers and Shah2004). Topology pruning rules are those that deal with arrangement or sequencing of functions. Topology rules also deal with the structure of the function structure, but unlike grammar rules, do not interact with the vocabulary at all, and hence are classified separately. Pruning the reverse engineered models serves the purpose of removing specific function blocks. Function blocks that have been identified to belong to one of the categories identified in Table 1 are removed from the function structure so that the pruned function structure only contains the function blocks that fall in either one of the other categories or do not fall in any of those categories. Pruning is done to understand the information content of the function blocks that were removed.
The pruning rules are also accompanied by an independent set of six rules that guide the user in reconfiguring the flows while functions are being pruned. This set of six flow reconfiguration rules ensures the consistency of the flows while preventing duplication. These flow rules are provided in Table 2.
Table 2. Rules for rerouting the flows

5.3. Pruning of function structures
In this research, each set of these rules was used separately to prune the function structures. In this manner, the effect of the pruning rules on the overall representation to predict information or answer questions can be measured. The application of these rules to reduce the number of functions in the function structures is called “pruning” instead of composition. This distinction has been made because composition implies applying all these rules at once, whereas pruning implies applying a subset of rules one at a time. The need for distinguishing the two terms also arises because the motivation of these rules is not to develop a method for composition, but rather to study how different components of a function structure impact the level of detail and amount of information content from the perspective of artificial intelligence.
To illustrate the pruning, an example of a juice extractor function structure as found in the Design Repository (http://design.engr.oregonstate.edu/repo) is used. These are the same function models used in previous work on predicting assembly time and market price (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016b ). Figure 1 shows the initial function structure for the juicer. There are a total of 24 function blocks in the model. It is noted that the function model does not include a clearly identified system boundary as recommended by several researchers (Kurfman et al., Reference Kurfman, Stone, van Wie, Wood and Otto2000; Otto & Wood, Reference Otto and Wood2001; Ullman, Reference Ullman2010; Pahl et al., Reference Pahl, Beitz, Blessing, Feldhusen, Grote and Wallace2013; Schultz et al., Reference Schultz, Mathieson, Summers and Caldwell2014; Nagel et al., Reference Nagel, Bohm, Linsey and Riggs2015). Other limitations of the model include inconsistently applied conservation principles and vocabulary. The model was not modified from what was found in the Design Repository. The intention of these observations is to highlight the limitations of the function structures obtained from the Design Repository and is not intended to be a comment on the robustness of the pruning rules.

Fig. 1. Unpruned function structure of a juicer.
Other products extracted from the Design Repository and used for training in this research include electric toothbrush, sander, garage door opener, hot air popper, iRobot Roomba, nail gun, mixer, hair dryer, lawn mower, jigsaw, sewing machine, blender, drill, and hole punch. Five separate products were randomly selected to be used for testing: grill, Maglite, solar yard light, vise, and stapler. This is a similar product database as used in previous studies (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016b ). Applying the vocabulary rules (CR1, CR5, and CR8) to the juicer function model results in a pruned model (Fig. 2).

Fig. 2. Vocabulary pruned function structure for juicer.
Applying the grammar rules to the initial function structure for the juicer (Fig. 1) results in a pruned function structure with only 13 functions (Fig. 3).

Fig. 3. Grammar pruned function structure of a juicer.
A third function model is generated from the initial juicer model by applying the topological pruning rules (Fig. 4). It should be noted that no changes resulted from the application of the topological rules. Changes were found in other product models when the topological rules were applied.

Fig. 4. Topology pruned function structure of a juicer (no impact of pruning).
Finally, all rules are applied to the juicer function model, resulting in Figure 5. Note that the remaining functions and flows in Figure 5 closely resemble the critical functions and flows described in (Lucero et al., Reference Lucero, Viswanathan, Linsey and Turner2014, Reference Lucero, Linsey and Turner2016).

Fig. 5. Vocabulary + grammar + topology pruned function structure of a juicer.
The same process is applied to all the function structures. As these are models derived from the same reverse engineered products, and the differences in ability to predict market price is dependent only on the information contained within the models. Table 3 illustrates the results from the pruning activities in terms of the removed flows and functions for each product. For all the products analyzed, the amount of function blocks removed due to application of these four sets of rules (vocabulary, grammar, topology, and a combination of vocabulary + grammar + topology) are listed in the columns. The number of function blocks removed as a percentage of the total number of functions contained in the original function structure of the product has been listed in the column corresponding to the absolute number of function removed. This percentage is useful for a relative comparison of the amount of function blocks that get removed as a result of the application of the particular set of rules. At this point, it is also important to note that the 15 products listed in Table 3 are used to train the artificial neural networks (ANNs), and the last five are used to test the model. More details on the ANNs have been listed in Section 7.2.
Table 3. Number of function blocks removed as a percentage of the total function blocks removed

6. CLASSIFICATION OF PRUNED FUNCTION STRUCTURES AS INDEPENDENT REPRESENTATIONS
From the previous discussions on pruning and comparison of error values obtained from the graph connectivity complexity method, which will be discussed further in Section 7, it is clear that there is a marked difference in how well each of the various pruned function structure sets behave as prediction models. This method has been used for market price prediction (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011; Mohinder et al., Reference Mohinder, Sudarshan, Summers and Gero2014; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016b ), for assembly time estimation (Owensby et al., Reference Owensby, Namouz, Shanthakumar and Summers2012; Namouz & Summers, Reference Namouz, Summers, Abramivici and Stark2013, Reference Namouz and Summers2014), for assembly quality defect prediction (Patel et al., Reference Patel, Andrews and Summers2016), and for using requirements to predict life cycle costs (Visotsky et al., Reference Visotsky, Patel and Summers2017). As per the classification framework developed in Summers and Shah (Reference Summers and Shah2004), a design representation can be classified as being distinct on the basis of these five characteristics: vocabulary, structure (grammar), expression, purpose, and abstraction of the representation. The application of pruning rules makes a change to some of these characteristics of the function structures on which the rules are applied. In Table 4, each of the pruned function structure scheme's five characteristics has been compared to those of the unpruned function structure. If the characteristics of the pruned function structures were found to be different than those of the unpruned function structures, this was indicated by an X. This section will focus on elaborating why each of the pruned function structures qualifies as an independent design representation. It can be seen that verbal pruned function structures differ from the unpruned function structures in terms of vocabulary and abstraction. The vocabulary pruning rules shown in Table 1 restrict the function blocks having specific vocabulary. For example, CR1 requires the removal of all function blocks that have the term import or export in them. Hence, the functional basis (Stone & Wood, Reference Stone and Wood2000) available for the vocabulary pruned function structures is limited as compared to the one available for unpruned function structures. As a result, the type and size of vocabulary elements differ in the two representations. The two representations also differ in terms of abstraction. To indicate this in a condensed manner, the two blocks, corresponding to vocabulary and abstraction for the vocabulary pruned function structures, have been blacked out in Table 4.
Table 4. Comparison of characteristics of the unpruned and pruned function structures

Similarly, the grammar pruned function structures differ in structure and abstraction from the unpruned function structures and have thus been colored as black. Structure refers to the allowable configurations between entities and relations (Summers & Shah, Reference Summers and Shah2004). Grammar pruning rules remove the function blocks in which the functional verb refers to any type of material, signal, or energy. This changes the structural characteristics of the grammar pruned function structures. The change in abstraction is attributed to the change in accuracy of the predicted market values that in turn is a manifestation of the change in the information content, as has been discussed in the case of verbal pruned structures. These differences lead to the grammar pruned function structures being classified as a different design representation.
The topology pruning also leads to a change in the structure of the function structure. This change in structure is global in nature, in that it impacts how adjacent function blocks will be put together under certain conditions (Summers & Shah, Reference Summers and Shah2004). The difference in abstraction follows the same line of reasoning as has been discussed in the case of verbal and grammar pruned function structures.
By extension, the last type of function structure scheme, which is a combination all of the previous pruned schemes, differs from the unpruned function structures in a combination of all the ways that each of the previously discussed representations differs from the unpruned function structures. Hence, the combined verbal + grammar + topology function scheme is a unique and distinct design representation. Moreover, it must be noted that all of these pruned function schemes are not only distinct from the unpruned function structure scheme but also distinct from one another.
7. GRAPH COMPLEXITY CONNECTIVITY METHOD
In order to determine the ability of a representation to predict information or answer questions, a previous approach is used: the graph connectivity complexity method (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011; Namouz & Summers, Reference Namouz, Summers, Abramivici and Stark2013, Reference Namouz and Summers2014; Mohinder et al., Reference Mohinder, Sudarshan, Summers and Gero2014; Owensby & Summers, Reference Owensby and Summers2014; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016b ; Summers et al., Reference Summers, Miller, Mathieson, Mocko, Summers, Mathieson and Mocko2014). This method has been used to predict assembly times from assembly models (Namouz & Summers, Reference Namouz and Summers2014; Owensby & Summers, Reference Owensby and Summers2014; Summers et al., Reference Summers, Miller, Mathieson, Mocko, Summers, Mathieson and Mocko2014) and market price from function structures (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011). Recent work compared the ability of the different representations (assembly models and function structures) to predict information about market price and assembly time (Mohinder et al., Reference Mohinder, Sudarshan, Summers and Gero2014; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016b ).
The procedure is executed in multiple steps (Fig. 6). Initially, the information used for prediction (function structures) and the performance metric (market price) being predicted is collected. Graph complexity metrics are applied against the function graphs using a complexity analysis tool (Mathieson & Summers, Reference Mathieson and Summers2010). The complexity metrics and the known targets are used to train ANNs. The 29 complexity metrics for each of the 15 training products serves as the input to the ANNs.

Fig. 6. Artificial neural network prediction function structures.
7.1. Structural-complexity metrics
To extract meaningful information from the function structures, their complexity must be quantified. The complexity is quantified in terms of 29 complexity metrics (Fig. 7) that are classified into four classes: size, interconnection, centrality, and decomposition (Mathieson & Summers, Reference Mathieson and Summers2010). These complexity metrics have been successfully used to model the assembly time and market values using the product's function structure and assembly models (Mathieson et al., Reference Mathieson, Arlitt, Summers, Stone, Shanthakumar and Sen2011; Namouz & Summers, Reference Namouz, Summers, Abramivici and Stark2013, Reference Namouz and Summers2014; Owensby & Summers, Reference Owensby and Summers2014).

Fig. 7. List of the 29 complexity metrics (Mathieson & Summers, Reference Mathieson and Summers2010).
By compressing graphs into a vector of the structural complexity metrics, graphs of different sizes and topologies can be encoded in the same manner. Where other researchers seek to create a single integrated complexity metric (Bashir & Thomson, Reference Bashir and Thomson2001; Shah & Runger, Reference Shah and Runger2011; Singh et al., Reference Singh, Balaji, Shah, Corman, Howard, Mattikalli and Stuart2012; Sinha & de Weck, Reference Sinha and de Weck2013a , Reference Sinha and de Weck2013b ), the approach taken here is to use many metrics and to let the surrogate modeling approach determine which are relevant for predicting the sought information. Further, previous research efforts in design complexity have focused on the final end product (Braha & Maimon, Reference Braha and Maimon1998; Bashir & Thomson, Reference Bashir and Thomson2004; Shah & Runger, Reference Shah and Runger2011; Singh et al., Reference Singh, Balaji, Shah, Corman, Howard, Mattikalli and Stuart2012), rather than early-stage design representations. This limits the potential usefulness of the metrics as predictors and guiding tools in the development process, as the complexity of the final product is only known after the design of the product is complete.
In previous studies that explored the sensitivity of the metrics to predict information, it was found that there is no global set of metrics that were most critical, except for the first size metric: dimensional elements (number of nodes in the graph). What has been found is that in every representation and prediction pair, at least one metric from each of the four classes has been found to be significant (Namouz & Summers, Reference Namouz, Summers, Abramivici and Stark2013; Mohinder et al., Reference Mohinder, Sudarshan, Summers and Gero2014; Sridhar et al., Reference Sridhar, Fazelpour, Gill and Summers2016a ).
7.2. ANNs
ANNs are used to generate the nonlinear prediction models. The complexity metrics developed for 20 electromechanical products are fed in to an ANN code. Fifteen products are used to train the ANN and the rest are used to test it. The ANN uses this information to relate the target values with the inputs, and therefore can predict market values. The ANNs used in this work are supervised backpropagation networks (Mathieson et al., Reference Mathieson, Wallace and Summers2013). In this work, multiple ANNs are used in the prediction modeling. Multiple architectures of the ANNs are used. The architecture is defined by the number of neurons in each layer and the number of hidden layers. A total of 189 different ANN architectures are used. This approach removes the “art” of ANN modeling where researchers try to construct a single ANN to be used. Moreover, each architecture is repeated 100 times with different initial weights on the links between neurons. These weights are randomly defined. Thus, a total of 18,900 ANNs are used for the prediction model. A histogram of the results from each ANN is used to find the average prediction.
ANNs are used due to their ability to perform nonlinear statistical modeling (Tu, Reference Tu1996). Other machine learning approaches, such as support vector machines and decision trees, are ill suited to this problem as they primarily perform a classification or clustering function and provide no continuous differentiable output. The advantages of ANNs include requiring less formal statistical training, the ability to detect complex nonlinear relationships between independent and dependent variables, the ability to discover possible interactions between predictor variables, and the ability to use multiple training algorithms (Tu, Reference Tu1996). ANN analysis has the characteristics of a black-box nature, greater computational expense, the tendency to “overfit,” and the empirical nature of the development of the model (Tu, Reference Tu1996; Zhang et al., Reference Zhang, Patuwo and Hu1998). Because the purpose of this research is to develop predictive models that reliably generalize between the input graph properties (complexity vectors) and performance predictors without requiring explicit meanings between each, the black-box nature is most appropriate. Further, overfitting in training is addressed by instituting an early stopping algorithm as well as withholding samples from training to test the generalization on nontrained data. Table 5 summarizes the results of several studies regarding the applicability and performance of ANNs as compared to other methods.
Table 5. ANN versus other inductive learning according to Miller, Mathieson, Summers, and Mocko (Reference Miller, Mathieson, Summers and Mocko2012)

8. EXPERIMENTAL PROCEDURE
In this study, the function structures were pruned in four different sets, resulting in different representations based on their refined local structure (Summers & Shah, Reference Summers and Shah2004): vocabulary, grammar, topology, and a combination of all three of these. As has been mentioned before, these function structures consist of consumer electromechanical products. The function structures for each of these have been developed by reverse engineering these products and are available in the Design Repository.
The graphs of these function structures are used to calculate the 29 complexity metrics. The market values for each of the 20 electromechanical products were calculated using averages from five different values from Amazon.com. These average market values for the test products used in this research are listed in Table 6.
Table 6. Correlation analysis for the four pruned prediction models and the unpruned prediction model

This information was used to train each set of the 18,900 ANNs. Fifteen products were used to train the ANNs, and 5 randomly selected products were reserved used to externally test the surrogate model. The same products were used for training for each of the different representation sets. The test products have been highlighted in Table 3. Based on this output, descriptive statistics including mean and standard deviation of market value were calculated for the market of each test product. These values average and have been listed alongside each other in Table 7. To clarify, each product was modeled in each representation: unpruned, vocabulary pruned, grammar pruned, topology pruned, and complete pruned. These models were then used to train 18,900 ANNs in five sets (one for each representation). The test models were only used for validation using the ANN set trained for that same representation. Thus, the grill model in the grammar pruned representation was tested with the ANN set that was trained on all the grammar pruned models.
Table 7. True and predicted market values for the four pruned prediction models and the unpruned prediction model

To understand the accuracy from each of the four prediction models, it is important to understand the amount of error in each of these models. To calculate the amount of error, three different types of error analysis formulae, listed in this section, were used based on those found in Patel et al. (Reference Patel, Andrews and Summers2016). To handle the wide range of values calculated by the ANNs, it is important to have a specialized error calculation formula. This is why the normalized error has been chosen to be used as one of the error calculation formula alongside the residual and standardized error. Residual error loses its sensitivity when one of the values, target or predicted, is very much larger than the other. The percent error has the ability to contextualize the extent of the error in a more accurate manner, because the error is expressed as the percentage of the difference between the predicted and the target value as a proportion of the target value. The percent error has a limitation in that the results can tend to be counterintuitive in situations where there is a large difference in the target and predicted values. Consider, for example, that the target value of a product is $600 and the predicted value is $5, then the standard error yields an output of 99.16%. In the next case, if the target and predicted values were switched to be $5 and $600, respectively, the standard error would yield an output of 11,900%. Hence, in such cases, the percent error cannot accurately describe the error.
These disadvantages can be overcome easily by using the normalized error, as the denominator of the normalized error is a product of both the predicted and target values. Hence, for the case discussed above, even if the values are switched, the error in both cases remains the same, that is, 11,801%. Hence, this stability of the normalized error makes it the preferred choice in the error calculations. This was done in order to ensure the robustness of the error calculation methodology. The three error calculation formulae are the following:
 $$\hbox{Residual Error} = \hbox{Target Value} - \hbox{Predicted Value},$$
$$\hbox{Residual Error} = \hbox{Target Value} - \hbox{Predicted Value},$$
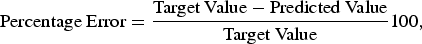 $$\hbox{Percentage Error} = \displaystyle{\hbox{Target Value} - \hbox{Predicted Value} \over \hbox{Target Value}} 100,$$
$$\hbox{Percentage Error} = \displaystyle{\hbox{Target Value} - \hbox{Predicted Value} \over \hbox{Target Value}} 100,$$
 $$\hbox{Normalized Error} = \displaystyle{\vert \hbox{Target Value} - \hbox{Predicted Value} \vert^2 \over \vert \hbox{Target Value} \times \hbox{Predicted Value} \vert} 100. $$
$$\hbox{Normalized Error} = \displaystyle{\vert \hbox{Target Value} - \hbox{Predicted Value} \vert^2 \over \vert \hbox{Target Value} \times \hbox{Predicted Value} \vert} 100. $$
The results from these error calculations for all five prediction models have been compiled in Figure 8. In this manner, the prediction error can be greater than 100% for the percent error and the normalized error. It is fully recognized that improvements to the predictive power of the approach can be made based on larger training sets, more similar training samples, and including information beyond the graph connectivity of the models (see Patel et al., Reference Patel, Andrews and Summers2016, for a comparison on factors influencing the inferencing power). However, improving the predictive capabilities of the approach is not the focus of this paper; rather, comparing the representations using the same prediction framework is.

Fig. 8. Calculated error values for the four pruned prediction models and the unpruned prediction model; R, residual error; P, percentage error; N, normalized error.
9. ANALYSIS OF RESULTS
The predicted market values of the five test products for all four prediction models were calculated in Table 7. These predicted market values are an average of 18,900 predicted ANN results. All of the values are in US dollars. The standard deviations for these market values are also listed in the table. It lists the actual market prices of all five test products in the first column. This is followed by the average (mean) market prices as predicted by the prediction models. In addition to the average market prices, the standard deviation for all test products across all five prediction models has also been listed in Table 7.
To analyze the results of the calculations, the accuracy of the results was computed using the three error calculation formulas (residual, standard, and normalized). These were applied to all test products used across all five prediction models. This was done in Figure 8. Under each prediction model, the column labeled R lists the residual error values. Similarly, the values in the columns labeled P and N are computed using the percent and normalized error formulae, respectively.
To better understand the relative accuracy of the prediction models, the mean error for each error type, the error percentage values of ≤100 were highlighted green, values in the range of >100 and ≤300 were highlighted yellow, values in the range of >300 and ≤400 were highlighted red, and all values ≥400 were highlighted brown in the bottom row of Figure 8. A key has been provided underneath the figure to indicate these values visually. This nomenclature was applied at two levels. The first level is the error type level and the second is the model type. In the error type level, each of the three error types (P, N, and R) for each prediction model is evaluated separately. In the second level, the nomenclature is applied to the average error across each prediction model. This average error is the average of these three different error types (P, N, and R).
Based on this analysis, it was found that the prediction model with the lowest total mean error was the unpruned function representation, followed by topology pruned representation, vocabulary pruned representation, grammar pruned representation, and finally complete pruned representation. It is important to note that this trend is followed by not only the total mean error but also all the mean of each of three individual error types used (residual, percent, and normalized). This trend, however, does not hold true for each of the five individual test products across the representations and errors as is shown by the error rank analysis shown in Figure 9.

Fig. 9. Calculated error rank analysis for the four pruned prediction models and the unpruned prediction model.
The only exception to this trend is the mean normalized error for the topology pruned function representation, which is slightly lower than the mean normalized error for the unpruned function structures. Three out of the five test products in topology pruned representation showing lower normalized error values as compared to unpruned function representation.
Because three different error calculation formulae were used, it is important to analyze their consistency within each prediction model and across all four prediction models. To accomplish this, an error rank analysis was done. As shown in Figure 9, the error values in each column were ranked from 1 to 5, 1 being the smallest error value and 5 being the largest. Color coding in the table is used to illustrate the rankings: white for rank 1, blue for rank 2, green for rank 3, yellow for rank 4, and red for rank 5. There are a few exceptions to this rank ordering. Seven product-representation pairs had rank ordering of the three error types that were more than one step difference. For example, the solar yard light vocabulary pruned representation had a rank 1 for the residual error but rank 3 for the standard and normalized errors. Further, the stapler-fully pruned model had a rank of 1 for the residual, a rank of 2 for the standard, and a rank of 3 for the normalized. In addition, a correlation analysis was conducted in Table 7 to evaluate whether the variations in error are correlated with the different models to estimate how consistent the variations are between the different error metrics. Correlations approaching 1 indicate that the error variations are consistent between the metrics, while correlations near 0 indicate no relationship. Negative values indicate an inverse relationship may be present. This analysis is summarized in Figure 9. The correlation analysis shows significant agreement in behavior between the different error metrics for every case except when all pruning rules are applied. When all pruning rules are applied, the residual error exhibits little if any agreement with the behavior of the standard and normalized errors.
When a consistency check was done for each type of error calculation across the four prediction models, limited consistency was observed. This was expected, because the type and amount information differs for each representation.
10. INTERPRETATION OF ERROR CALCULATIONS
Now that the four prediction models have been analyzed for accuracy, it is important to understand and interpret these results and relate them back to pruning. As has been discussed previously, the rules used to prune the function structures are meant to compose it. The functional basis used in these function structures is at the same level of hierarchy, which in this case is the secondary level. This means that the difference between the accuracy of the prediction models is the result of change (reduction) in information content.
One way to measure the change in information content is the number of function blocks removed as a result of application of a group of pruning rules. Table 3 shows the absolute number and percentage of function blocks removed as a result of pruning rules for each prediction model applied to each one of the 20 consumer products. As can be seen from the table, the maximum number of function blocks are removed in the vocabulary + grammar + topology pruned prediction model.
This model also corresponds to the maximum mean model error as reported in Figure 8. The topology pruned prediction model had the minimum number of function blocks removed. This model also showed the least amount of error. The vocabulary and grammar pruned prediction models are similar in terms of mean model error reported and the number of function blocks removed. The relationship between the mean model error and the number of function blocks removed in the case of these two blocks is, however, inverted. In the case of grammar and vocabulary pruned prediction models, there does not seem to be a clear relationship between the number of function blocks removed and the error value for individual test products.
This can be explained by the fact that not all function blocks have one flow entering or exiting them. The amount of information removed from the function structure increases if the removal of one function block also results in removal of multiple flows instead of just one flow. There is also a difference due to the location of the function block in the function structure. For example, the vocabulary pruning rules contain the remove all import and export functions. Both of these functions, almost without exception, are located on the periphery of the function structures. In contrast, grammar pruning rules deal with functions that are almost always located away from the periphery of the function structure. All of these are reflected in the complexity metrics that form the basis of data being fed into the ANNs. There is evidence to suggest that a significant change in the number of function blocks, and by default the information content, is reflected intuitively in the mean model error values. This corroborates well to the information theoretic approach (Sen, Summers, et al., Reference Sen, Summers and Mocko2010) discussed in the motivation section.
11. CONCLUDING REMARKS AND FUTURE WORK
The aim of this study was to understand the value contained in a representation and use this value to compare different design representations. The design representation used in this case is function structures. The value of representation is defined as the representation's ability to accurately predict market values of the products. The study also addresses the question of whether applying a different set of pruning rules to the original set of function structures yields pruned function structures that could be considered as independent representations.
To accomplish this, the functional pruning rules were applied to the function structures obtained from the Design Repository. Four different sets of function structures were obtained by applying different sets of pruning rules to the original function structures. Hence, a total of five different functional representations, including the original set of function structures, were available for analysis.
In order to assess the value present in each of these five function models, the functional models were then evaluated for their ability to accurately predict the market values of the products that they were being modeled after. ANNs were used for these predictions. The predicted market values were different for each of the five prediction models. The unpruned function structures had the lowest total mean error at 49%, followed by topology pruned at 61.8%, vocabulary pruned at 195.8%, grammar pruned at 251.1%, and the vocabulary + grammar + topology pruned at 1139.4%. A direct relationship was also found between the number of function blocks removed from the function model corresponding to reasoning ability of the representation. Because the accuracy of prediction of each of these function models is different, it can be concluded that these representations differ in their ability to support reasoning activities. Therefore, it is valid to conclude that the five different function models differ in their value content. It can also be concluded that the application of different pruning rules to the original function models gives rise to pruned models that differ in the amount of value contained in them. This is evident from the fact that each of the pruned models predicts the market values with a different accuracy.
The error values serve as a benchmark for the designer when making a choice of choosing a function modeling scheme. An important area of future work would be to quantify the effort that goes into creating models in each representation. This would further help in improving the benchmarking and enabling the designers to choose a functional modeling scheme on not only the basis of accuracy but also the amount of effort that goes into ensuring the said accuracy.
Furthermore, an empirical examination scheme developed in Summers and Shah (Reference Summers and Shah2004) was applied to all the pruned function models in order to compare each of the pruned representations to the unpruned representation. This comparison was based on five characteristics of each design representation: vocabulary, structure (grammar), expression, purpose, and abstraction. It was found that the application of pruning rules resulted in a change in one or more of these features for all pruned models. The only characteristics that remained unaffected by the application of pruning rules were expression and purpose. It was found that the vocabulary pruning rules impacted the vocabulary characteristics and the grammar and topology pruning rules impacted the structure (grammar) dimension. It was therefore concluded that all of these function models are distinct design representations, as their characteristics differ from one another and from the original unpruned function representation.
With this initial step in the benchmarking study, it is important to extend this research to other design representations that have their basis as functions, for example, structure–behavior–function models, and develop a holistic set of guidelines that will help the designer pick from the design representations, the most appropriate one for the stage of the design process the user is at. The basis of this selection would be the value of information that is contained in the representation per a unit amount of effort required to create the representation.
Amaninder S. Gill is a PhD student in automotive engineering at Clemson University and a Research Assistant in the Clemson Engineering Design Applications and Research Group. He previously worked for Honda Cars India Ltd. (powertrain manufacturing) and Exotic Metals Forming Co. (aerospace sheet metal fabrication). Amaninder earned his MS in mechanical engineering from Washington State University (product life cycle analysis) and his BS in mechanical engineering (manufacturing) from Punjabi University, India. His current research focuses on the quantification of value of information contained in conceptual design representations (functional structures) using computational and cognitive metrics.
Joshua D. Summers is a Professor of mechanical engineering at Clemson University, where he is also the Co-Director of the Clemson Engineering Design Applications and Research Group. He earned his PhD in mechanical engineering from Arizona State University and his MS and BS from the University of Missouri. Dr. Summers worked at the Naval Research Laboratory (VR Lab and NCARAI). His research has been funded by government, large industry, and small- to medium-sized enterprises. Joshua's areas of interest include collaborative design, knowledge management, and design enabler development with the overall objective of improving design through collaboration and computation.
Cameron J. Turner is a Professor in the Department of Mechanical Engineering at Clemson University. He previously worked at the Colorado School of Mines and was also a Technical Staff Member at Los Alamos National Laboratories. Dr. Turner teaches classes in engineering design methods, design optimization, mechanical systems, computer-aided design/engineering/manufacturing, and design of complex systems. Cameron is currently the Program Chair for the ASME CIE Division Executive Committee and is a member of the International Design Simulation Competition Committee of ASME. Prof. Turner won the CSM Design Program Director's Award in 2015 for service to the capstone design program.
















